"""
操作selenium的时候,先写一点,再按照它打开的浏览器写找到内容,因为我的浏览器可能是保存密码等设置过,和他的界面不一样!!
查找的时候,有id尽量找id
操作selenium命令如下
点击click()
各种通过id,text,class查找等
输入.send_keys()
获取cookie:get_cookies()
.add_cookie({'k1':'xxx','k2':'yyy'}) 设置cookie
bro.execute_script('alert("hello world")') #打印警告
执行脚本:browser.execute_script('window.open()')
"""
selenium的查找方式
显示等待和隐士等待
#显示等待和隐示等待
#隐式等待:在查找所有元素时,如果尚未被加载,则等10秒(针对所有)
# browser.implicitly_wait(10) 表示等待所有,
#显式等待:显式地等待某个元素被加载(针对局部,可能要写多个)
# wait=WebDriverWait(browser,10)
# wait.until(EC.presence_of_element_located((By.ID,'content_left')))
from selenium import webdriver
import time
bro=webdriver.Chrome()
bro.get("http://www.baidu.com")
bro.implicitly_wait(10)
# 1、find_element_by_id 根据id找
# 2、find_element_by_link_text 根据链接名字找到控件(a标签的文字)
# 3、find_element_by_partial_link_text 根据链接名字找到控件(a标签的文字)模糊查询
# 4、find_element_by_tag_name 根据标签名
# 5、find_element_by_class_name 根据类名
# 6、find_element_by_name 根据属性名
# 7、find_element_by_css_selector 根据css选择器
# 8、find_element_by_xpath 根据xpath选择
dl_button=bro.find_element_by_link_text("登录")
dl_button.click()
user_login=bro.find_element_by_id('TANGRAM__PSP_10__footerULoginBtn')
user_login.click()
time.sleep(1)
input_name=bro.find_element_by_name('userName')
input_name.send_keys("17851822064")
input_password=bro.find_element_by_id("TANGRAM__PSP_10__password")
input_password.send_keys("Az84564586")
submit_button=bro.find_element_by_id('TANGRAM__PSP_10__submit')
time.sleep(1)
submit_button.click()
time.sleep(100)
print(bro.get_cookies())
bro.close()
2 selenium爬取实例

上面这种多个属性的,选择其中一个属性即可。假如直接复制全部属性,那么使用css选择器,选择内部嵌套的标签就出现空格问题了!!!

换行问题
下面这个strong嵌套a,a中有文本。通过good.find_element_by_css_selector('.p-commit strong').text可将strong内的全部文本取出!
<strong><a id="J_comment_100002888716" target="_blank"href="//item.jd.com/100002888716.html#comment" onclick="searchlog(1,100002888716,1,3,'','flagsClk=1094717576')">6500+</a>条评价</strong>
from selenium import webdriver
from selenium.webdriver.common.keys import Keys #键盘按键操作
import time
bro=webdriver.Chrome()
bro.get("https://www.jd.com")
bro.implicitly_wait(10)
def get_goods(bro):
print("------------------------------------")
goods_li = bro.find_elements_by_class_name('gl-item')
for good in goods_li:
img_url = good.find_element_by_tag_name('img').get_attribute('src')
if not img_url:
img_url = 'https:' + good.find_element_by_css_selector('.p-img a img').get_attribute('data-lazy-img')
url = good.find_element_by_css_selector('.p-img a').get_attribute('href')
price = good.find_element_by_css_selector('.p-price i').text
# name = good.find_element_by_css_selector('.p-name p-name-type-2 em').text
name = good.find_element_by_css_selector('.p-name em').text.replace('
', '')
commit = good.find_element_by_css_selector('.p-commit strong').text#商品评论数:1.7万+条评价
print('''
商品链接:%s
商品图片:%s
商品名字:%s
商品价格:%s
商品评论数:%s
''' % (url, img_url, name, price,commit))
next_page = bro.find_element_by_partial_link_text("下一页")
time.sleep(1)
next_page.click()
time.sleep(1)
get_goods(bro)
input_search=bro.find_element_by_id('key')
input_search.send_keys("性感内裤")
input_search.send_keys(Keys.ENTER)
#进入了另一个页面
try:
get_goods(bro)
except Exception as e:
print("结束")
finally:
bro.()
操作
#获取属性:
# tag.get_attribute('src')
#获取文本内容(包含嵌套标签内的内容)
# tag.text
#获取标签ID,位置,名称,大小(了解)
# print(tag.id)
# print(tag.location)
# print(tag.tag_name)
# print(tag.size)
#模拟浏览器前进后退
# browser.back()
# time.sleep(10)
# browser.forward()
cookies管理
#cookies管理(*****)
# print(browser.get_cookies()) 获取cookie
# browser.add_cookie({'k1':'xxx','k2':'yyy'}) 设置cookie
运行js。执行脚本
#运行js。执行脚本
# from selenium import webdriver
# import time
#
# bro=webdriver.Chrome()
# bro.get("http://www.baidu.com")
# bro.execute_script('alert("hello world")') #打印警告
import time
from selenium import webdriver
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
#选项卡管理
用【1】来表示第几个选项卡。
import time
from selenium import webdriver
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles) #获取所有的选项卡
browser.switch_to_window(browser.window_handles[1])#选项框从左到右依次为0到正无穷
browser.get('https://www.taobao.com')
browser.close()
time.sleep(3)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://www.sina.com.cn')
browser.close()
动作链
#动作链
# from selenium import webdriver
# from selenium.webdriver import ActionChains
#
# from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
# import time
#
# driver = webdriver.Chrome()
# driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
# wait=WebDriverWait(driver,3)
# # driver.implicitly_wait(3) # 使用隐式等待
#
# try:
# driver.switch_to.frame('iframeResult') ##切换到iframeResult
# sourse=driver.find_element_by_id('draggable')
# target=driver.find_element_by_id('droppable')
#
#
# #方式一:基于同一个动作链串行执行
# # actions=ActionChains(driver) #拿到动作链对象
# # actions.drag_and_drop(sourse,target) #把动作放到动作链中,准备串行执行
# # actions.perform()
#
# #方式二:不同的动作链,每次移动的位移都不同
#
#
# ActionChains(driver).click_and_hold(sourse).perform()
# distance=target.location['x']-sourse.location['x']
#
#
# track=0
# while track < distance:
# ActionChains(driver).move_by_offset(xoffset=2,yoffset=0).perform()
# track+=2
#
# ActionChains(driver).release().perform()
#
# time.sleep(10)
#
#
# finally:
# driver.close()
只需要记得这张图即可
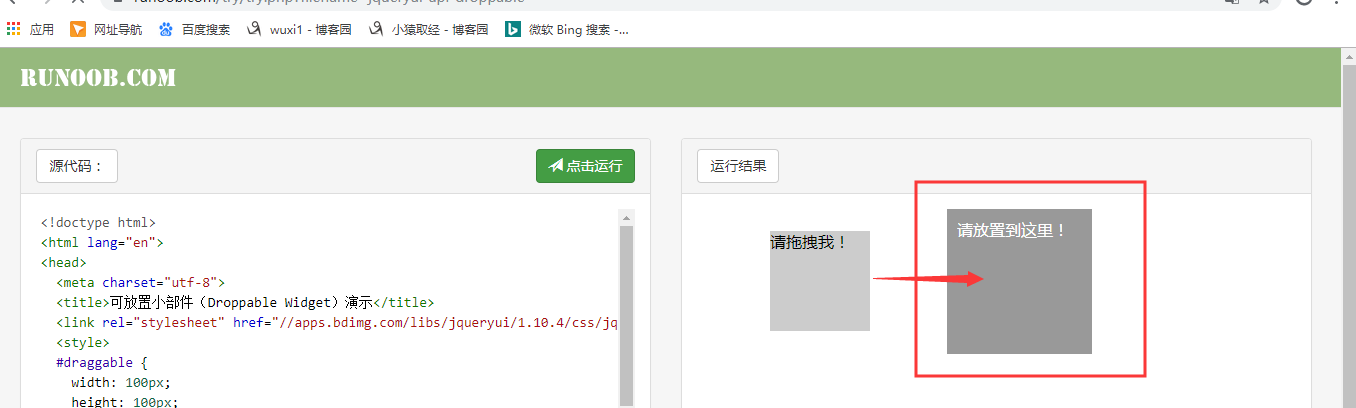
json操作
# 序列化和反序列化
with open('cookie.json','w')as f:
json.dump(cookie,f)
with open('cookie.json','r')as f:
di=json.load(f)

使用selenium打开网址,然后让用户完成手工登录,再获取cookie,根据获取来的cookies,并且带着头,来进行登陆
import requests
from selenium import webdriver
import time
import json
# 使用selenium打开网址,然后让用户完成手工登录,再获取cookie
url = 'https://account.cnblogs.com/signin?returnUrl=https%3A%2F%2Fwww.cnblogs.com%2F'
driver = webdriver.Chrome()
driver.get(url=url)
time.sleep(15)
driver.refresh()
c = driver.get_cookies()
print(c)
with open('xxx.txt','w') as f:
json.dump(c,f)
with open('xxx.txt', 'r') as f:
di = json.load(f)
cookies = {}
# 获取cookie中的name和value,转化成requests可以使用的形式
for cookie in di:
cookies[cookie['name']] = cookie['value']
print(cookies)
# from datetime import datetime
#
# GMT_FORMAT = '%a, %d %b %Y %H:%M:%S GMT'
#
# # Sun, 24 Nov 2019 06:14:53 GMT
# #Tue, 26 Nov 2019 22:18:23 GMT
# #Sun, 24 Nov 2019 06:14:53 GMT
# # Tue, 26 Nov 2019 14:16:01 GMT (GMT)
# print(datetime.now().strftime(GMT_FORMAT))
# ttt=str(datetime.now().strftime(GMT_FORMAT))
headers = {
# 'authority': 'www.jd.com',
# 'method': 'GET',
# 'path': '/',
# 'scheme': 'https',
# 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
# 'accept-encoding': 'gzip, deflate, br',
# 'accept-language': 'zh-CN,zh;q=0.9',
# 'cache-control': 'max-age=0',
# 'upgrade-insecure-requests': '1',
'authority': 'i-beta.cnblogs.com',
'method': 'GET',
'path': '/',
'scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'if-modified-since': 'Sun, 24 Nov 2019 06:14:53 GMT',
# 'if-modified-since': 'Sun, 24 Nov 2019 06:14:53 GMT,
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
# 使用该cookie完成请求
response = requests.get(url='https://i-beta.cnblogs.com/api/user', headers=headers, cookies=cookies)
print('xxx')
response.encoding = response.apparent_encoding
print(response.text)
requests-html
request-html安装:百度搜索request-html中文文档
pip install requests-html