字符编码发展史
字符编码的作用
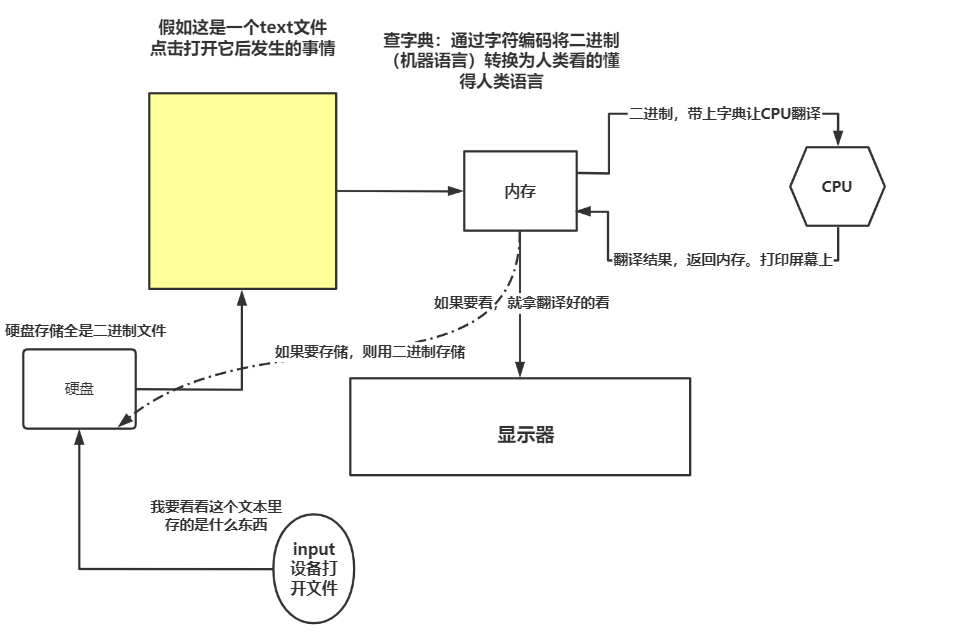
我们都知道,计算机内部是由二进制组成。我们人类如果想要与计算机进行交流和沟通,就必须有一个将人类语言翻译为计算机语言的过程。
ASCII码的出现
由于计算机是西方世界发明。所以第一本人类与计算机之间沟通的翻译词典则只会记载英文与计算机语言之间的关系,它叫做ASCII码表。用一串二进制来表示一个字符,如大写字母A代表的二进制是:'0b1000001'(十进制65),而小写字母a代表的二进制是'0b1100001'(十进制97)。它一共有8位二进制数组成,实际上7位即可表示全部的英文了。但是为了后期的拓展做准备,还是规定了8位一组。事实证明8位一组是明智的选择,后来ASCII码表这本词典中陆陆续续的还加入了很多其他的字符。
在ASCII码表中,一个字符占用1Bytes(8bit)的空间。

其他编码的出现
随着计算机的不断发展,越来越多的国家也开始使用计算机。但是不好意思,计算机语言与人类语言的翻译词典只有一本ASCII码表。也就是说人类语言中只有英语或者ASCII码表中记载的符号才能被计算机认识,其他的语言一律不行。
为了解决这种办法,陆陆续续的又出现了其他的字符编码表。
日本的
Shift-JIS表韩国的
Euc-kr表中国的
GBK表...
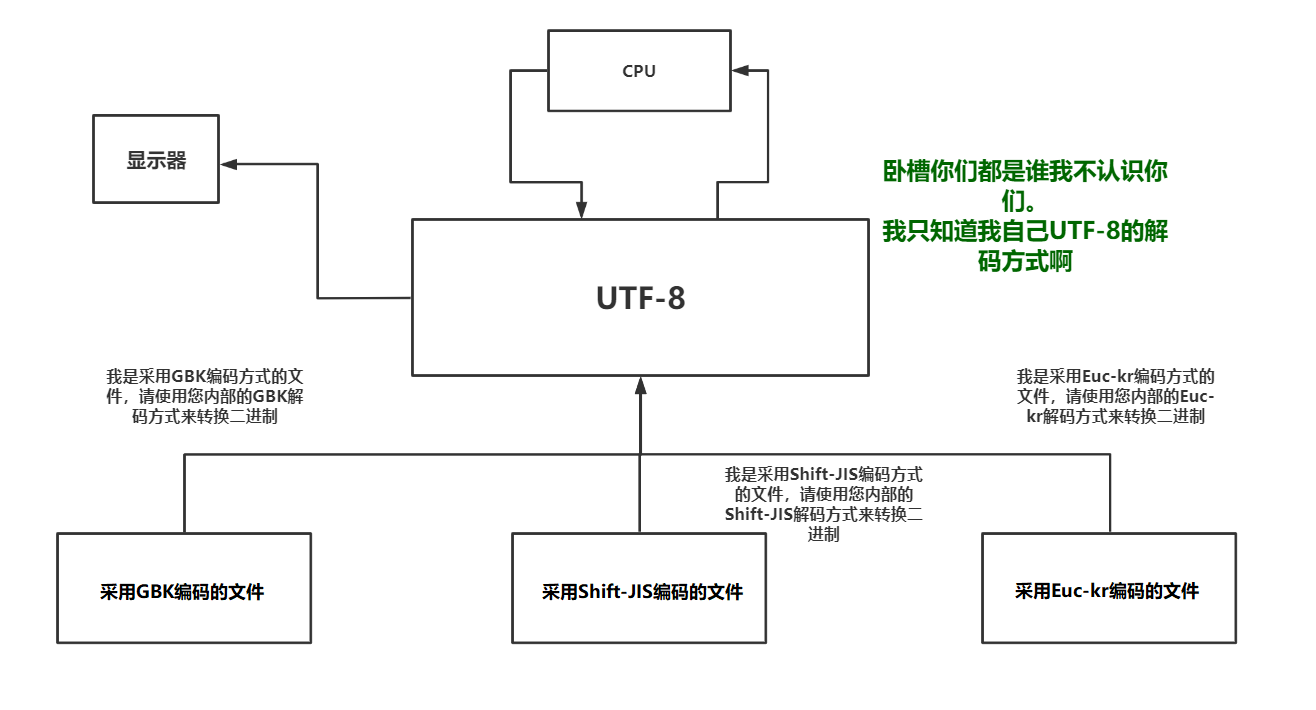
这些表都有一个共同的特点。他们除了融合了ASCII表中的所有人类语言与计算机语言之间的关系外,还包含了本国语言与计算机语言之间的关系。唯一不同的是占用字符空间不一样。这里拿GBK来举例:在GBK中,一个英文或字符占用1Bytes(8bit),而一个中文字符则占用2Bytes(16bit)
这样看似很和谐,实际上有一个致命的问题。看下图:
Unicode出现:统一规范
随着世界经济统一化,地球已经变为地球村。谁也不想打开一个日本动作片网站一看全是什么都不认识的乱码吧?为了解决这个问题,1990年研发的Unicode编码产生了至关重要的作用(1990年研发,1994年正式投入使用)。Unicode编码融合了所有人类语言与计算机语言之间的关系。现在计算机内存中带的那本翻译词典也都是Unicode编码表,有了它。麻麻再也不用担心打开动作片网站不认识标题了,哈哈哈。

在Unicode中,中文或者英文字符统一都占用2Bytes的空间(16bit),这一点尤其重要。直接催促了UTF-8的现世。
UTF-8出现:弥补Unicode缺点
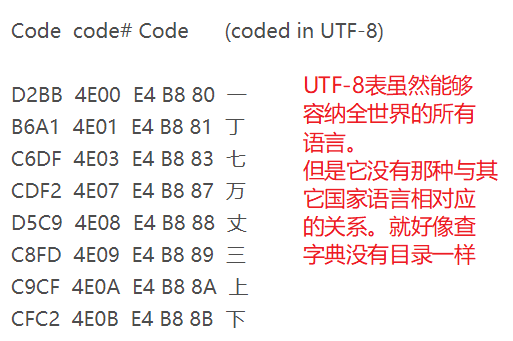
哈,看到这里肯定有人疑问。Unicode这么屌,为什么不用他直接进行存储呢?还用什么GBK和什么Shift-JIS啊?别急,我们先看看GBK的内存占用空间哈。GBK中文2字节,英文1字节。如果用Unicode进行存储那么英文也是2字节,使用者噼里啪啦全部都写了好多英文。那占用空间就多了非常多,占用空间一多当点击保存的时候必然硬盘的工作量更大了,硬盘工作量大导致I/O延迟致使整个程序的运行速度就慢了下来。所以,我们不用Unicode进行存储,为了解决这种办法。出现了UTF-8 (全称Unicode Transformation Format,即Unicode的转换格式)。被称为:可变长的字符编码
UTF-8英文字符占1Bytes(8bit),中文占3Bytes(24bit),生僻字则也可能使用4Bytes进行存储(32bit)。看起来占用空间更多了是吗?错了,其实占用空间相比于Unicode少了很多。因为在世界范围上来说,英文的资料比中文的资料多得多。
那么,既然这样的话为什么内存中不使用UTF-8来做翻译词典呢?为什么还要用Unicode做翻译词典?这个原因很简单。Unicode包含于其他字符编码之间的关系,而UTF-8则不包含这个关系,所以在如今GBK或者Shift-JIS依旧存在的情况下(此外还有很多字符编码)。使用Unicode作为翻译词典会更好。

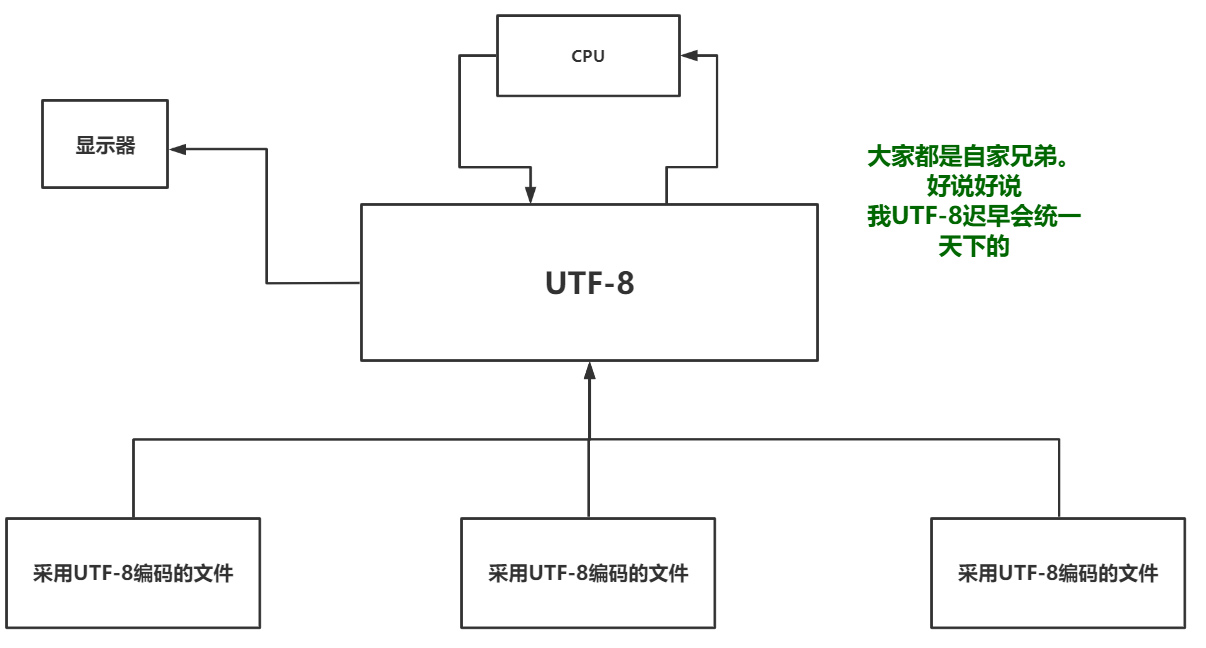
字符编码未来发展趋势
UTF-8对比Unicode唯一的缺点就是没有与其他字符编码之间的对应关系。其实这个缺点也不叫缺点。随着时间的推移以及越来越多的人使用UTF-8编码格式进行存储文件那么全世界共同使用同一套标准的话内存中就可以使用UTF-8来做这人类语言与机器语言之间翻译的桥梁了。如图所示:
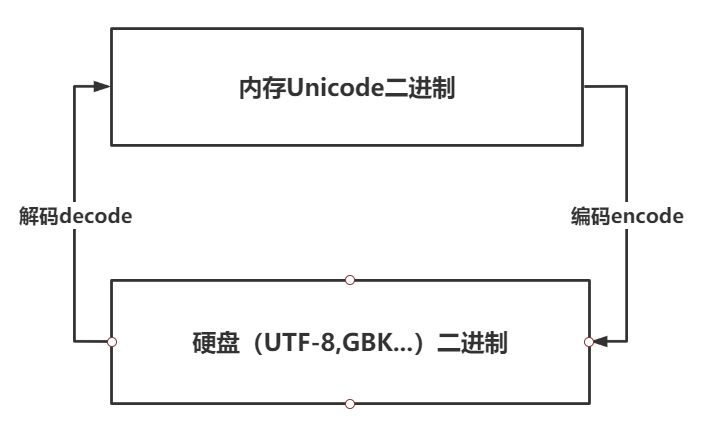
附:如何理解编码与解码
解码decode与编码encode图示:
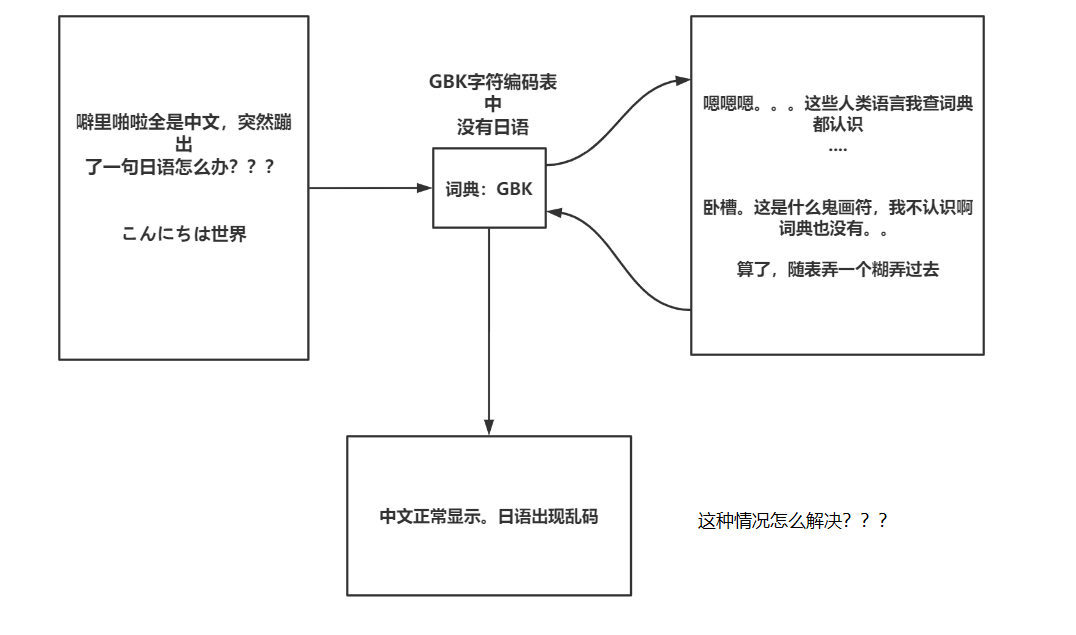
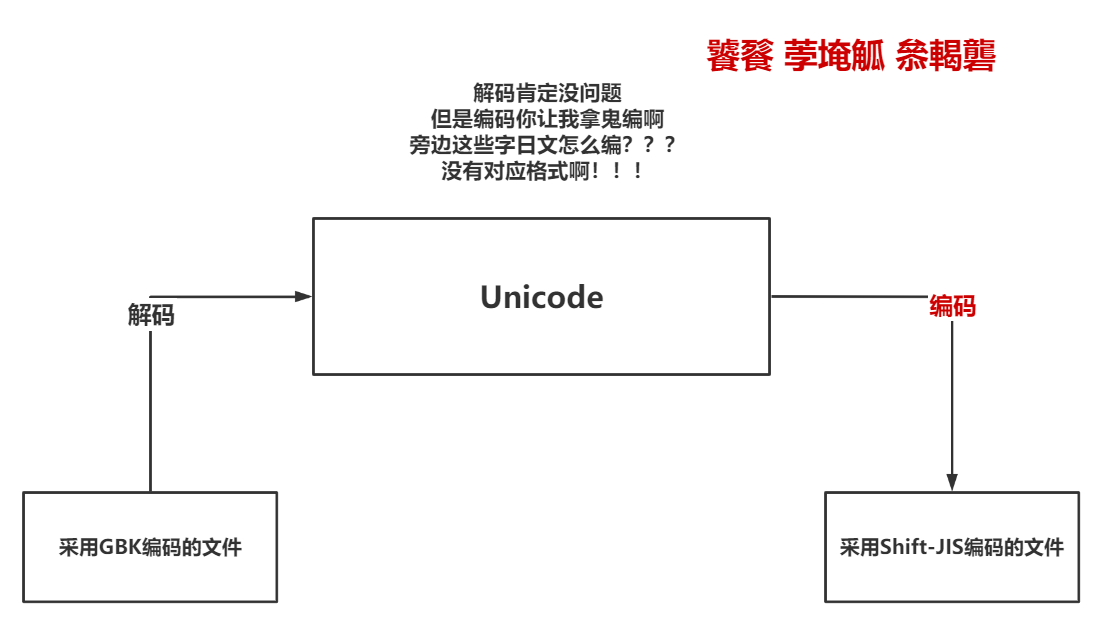
附:Unicode不支持跨编码互转的原因
很多新手朋友都有一个猜想。认为不同的编码都可以通过Unicode互相转换,其实这么做是不可能的。我们看一下图示:
进阶:其他编码转Unicode底层实现
这一节我想了很久要不要写。因为涉及到的东西太过底层了,所以也是郁闷了挺久。还是写写吧,感兴趣的朋友可以看一下,不感兴趣的朋友可以不看。
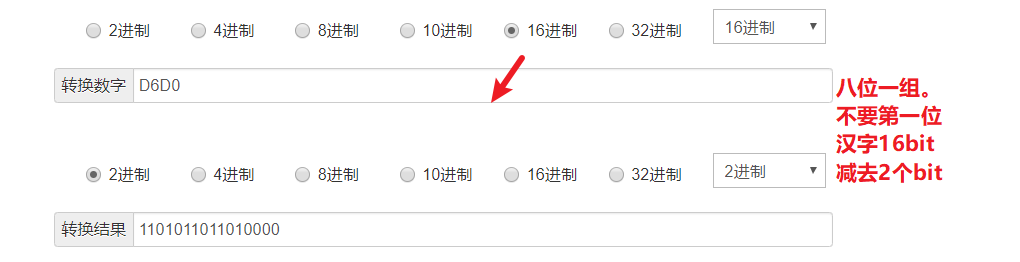
首先看一下中在Unicode中与GBK编码的关系

我们尝试写一个脚本,使用Python2来测试它的GBK编码是不是真的如同图上一样。
# coding:gbk # 在Python2中,列表里打印的是编码。而在Python3中,则是直接打印字符 x = "中" print([x]) # ['xd6xd0']
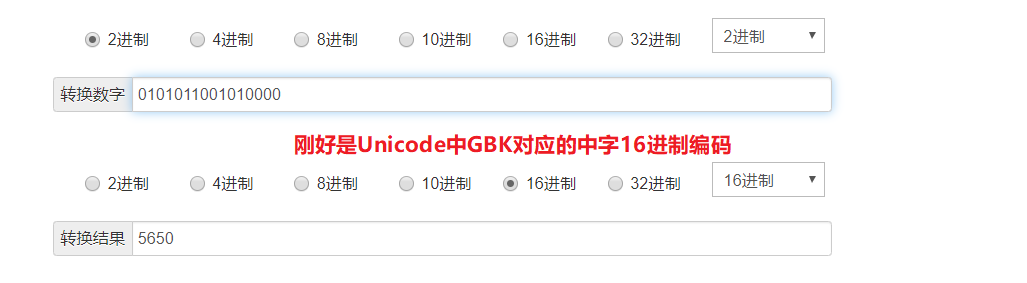
可以看到这里居然出现了D6D0,说好的5650呢?是怎么回事?
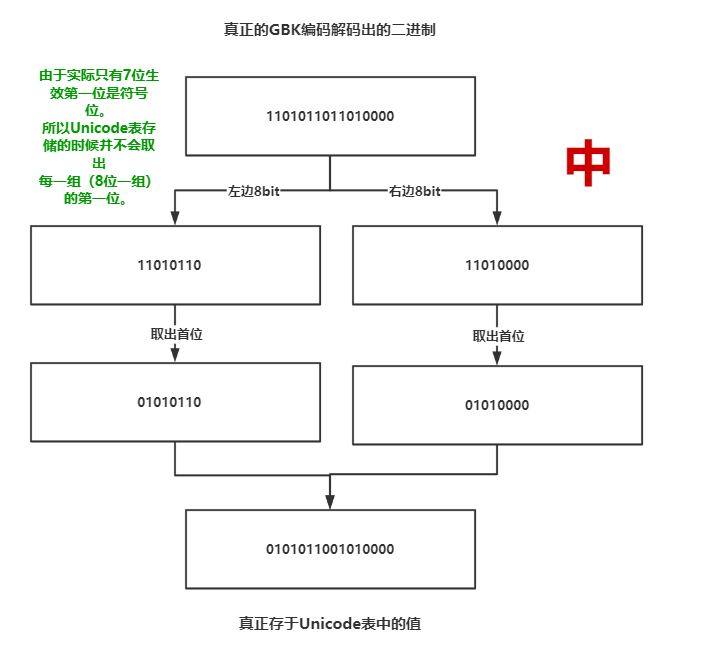
GBK编码汉字占2Bytes(16bit),英文占1Bytes(8bit)。如何区分它们?其实首位代表符号位。如果是汉字首位是1,如果是英文首位就是0。故汉字取15位,英文取7位才是Unicode表中真正存的值!!!
乱码问题剖析与解决
文本出现乱码原因
当一个文本使用GBK存储,而使用UTF-8进行读取的话势必会产生乱码问题。解决乱码核心点之一,用那种格式存的就由那种格式读。你想想。你丫GBK存的东西让计算机用UTF-8去读我吐了,你让他怎么读?标准都不一样啊。
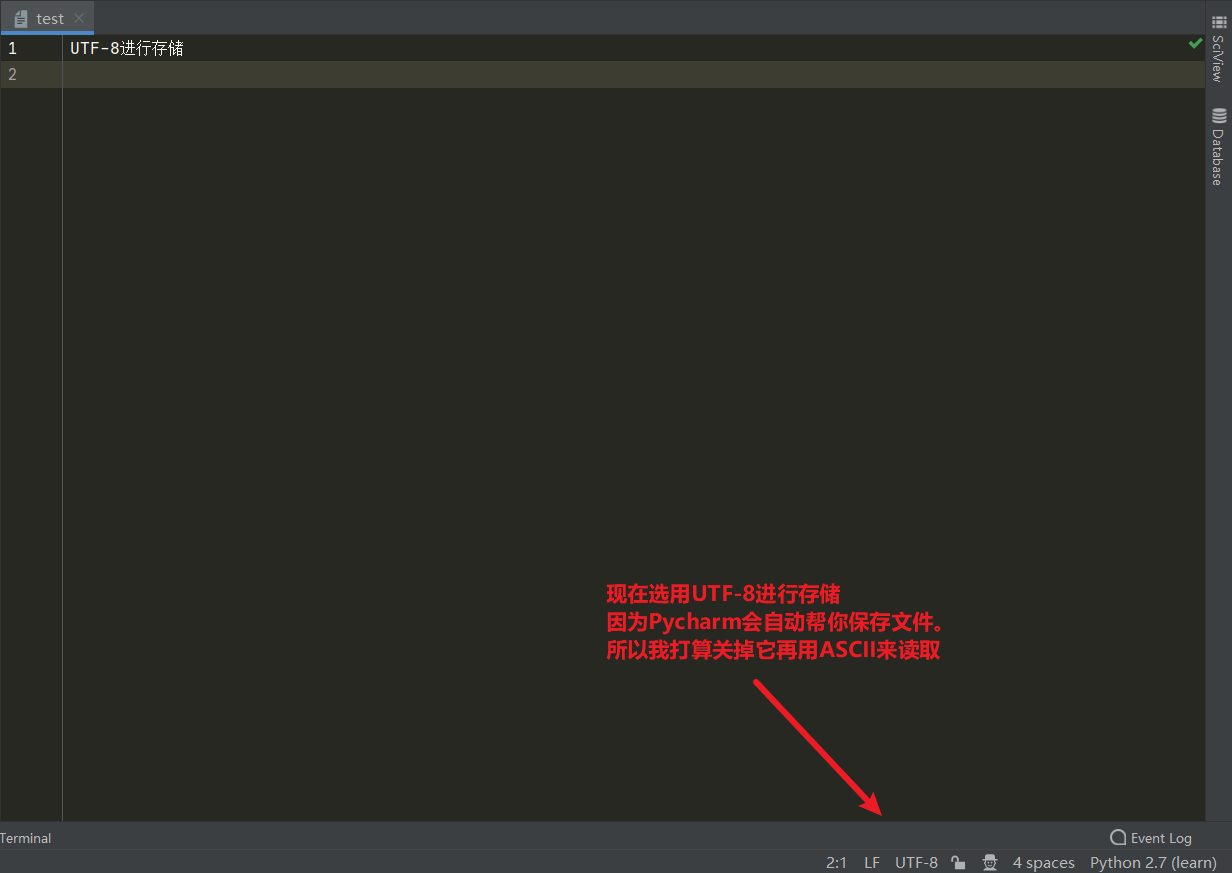
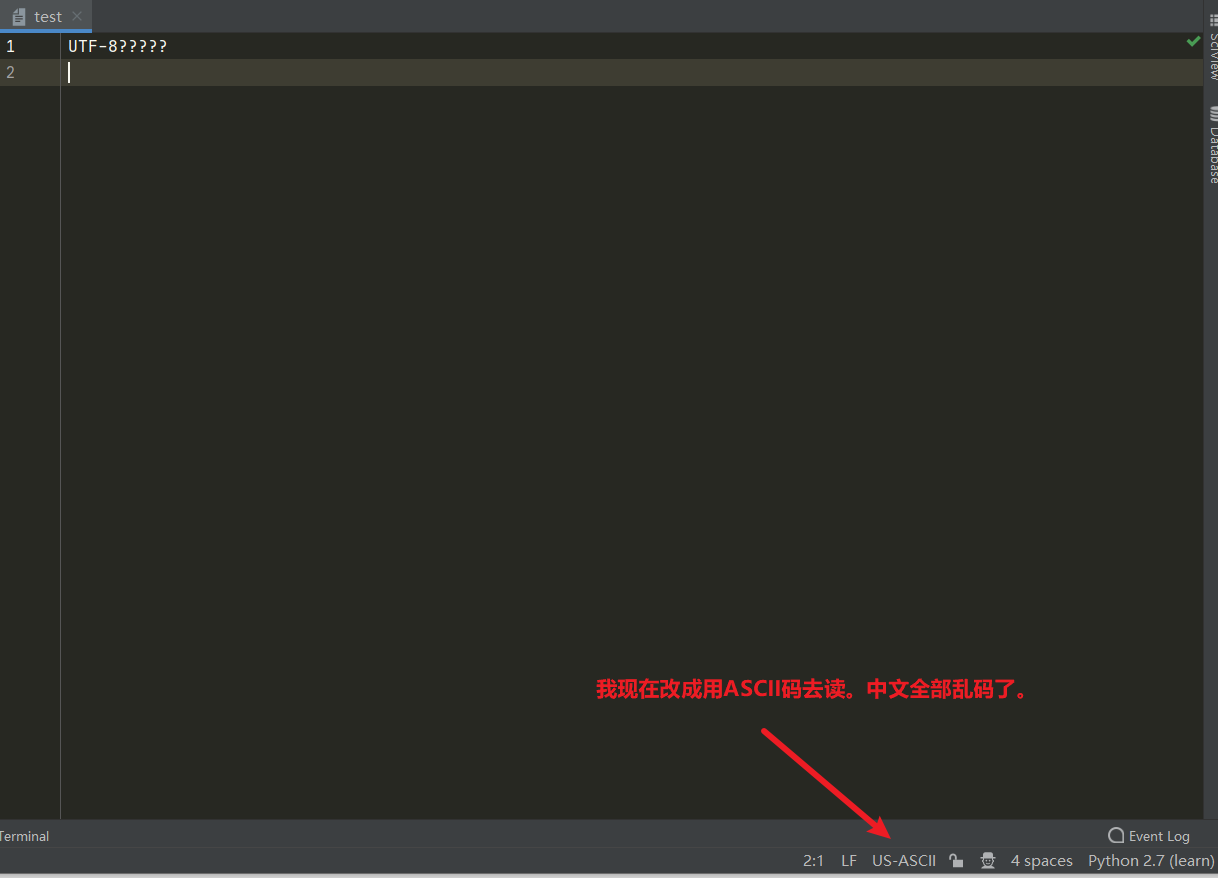
所以,这里验证了用什么方式存。就要用什么方式去读
还有一种骚操作,用什么方式写,就要用什么方式存。你丫写一堆日语用GBK去存,这不是找死吗?来我们试试。
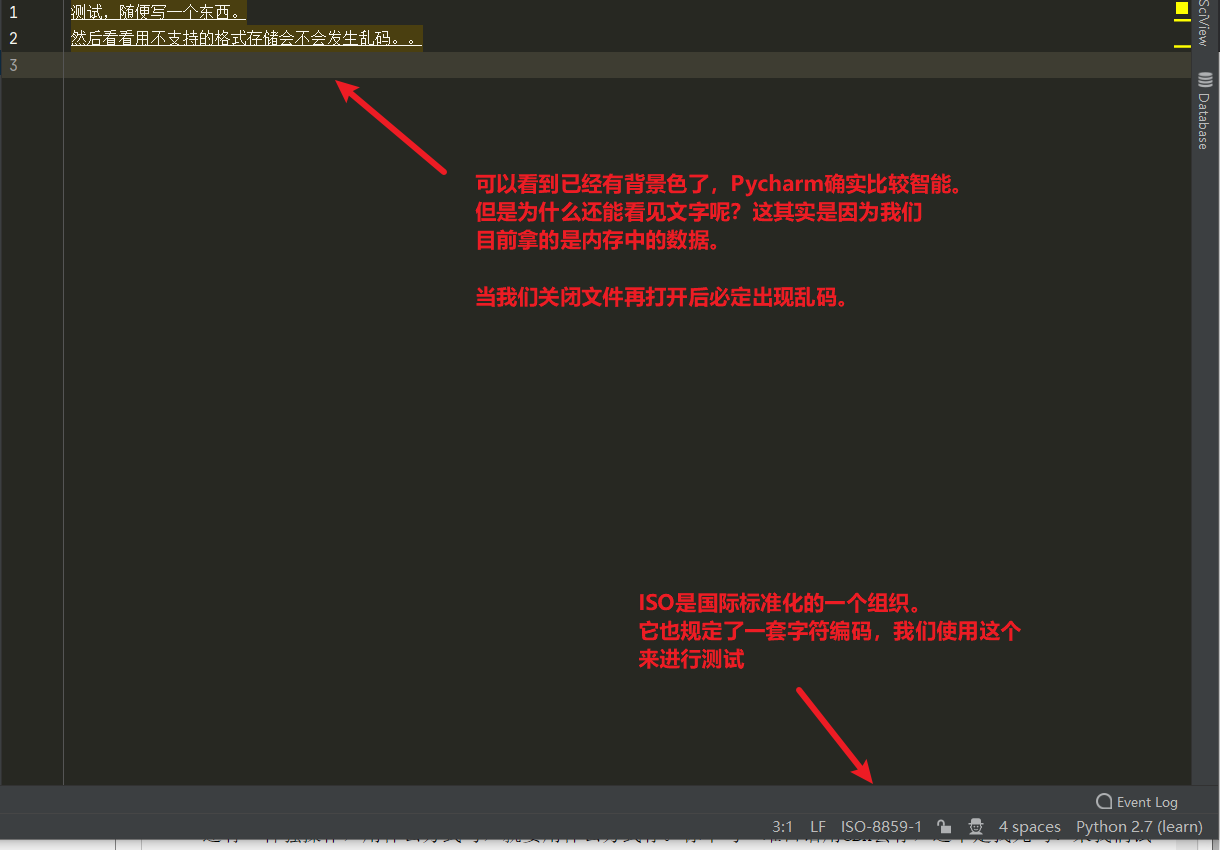
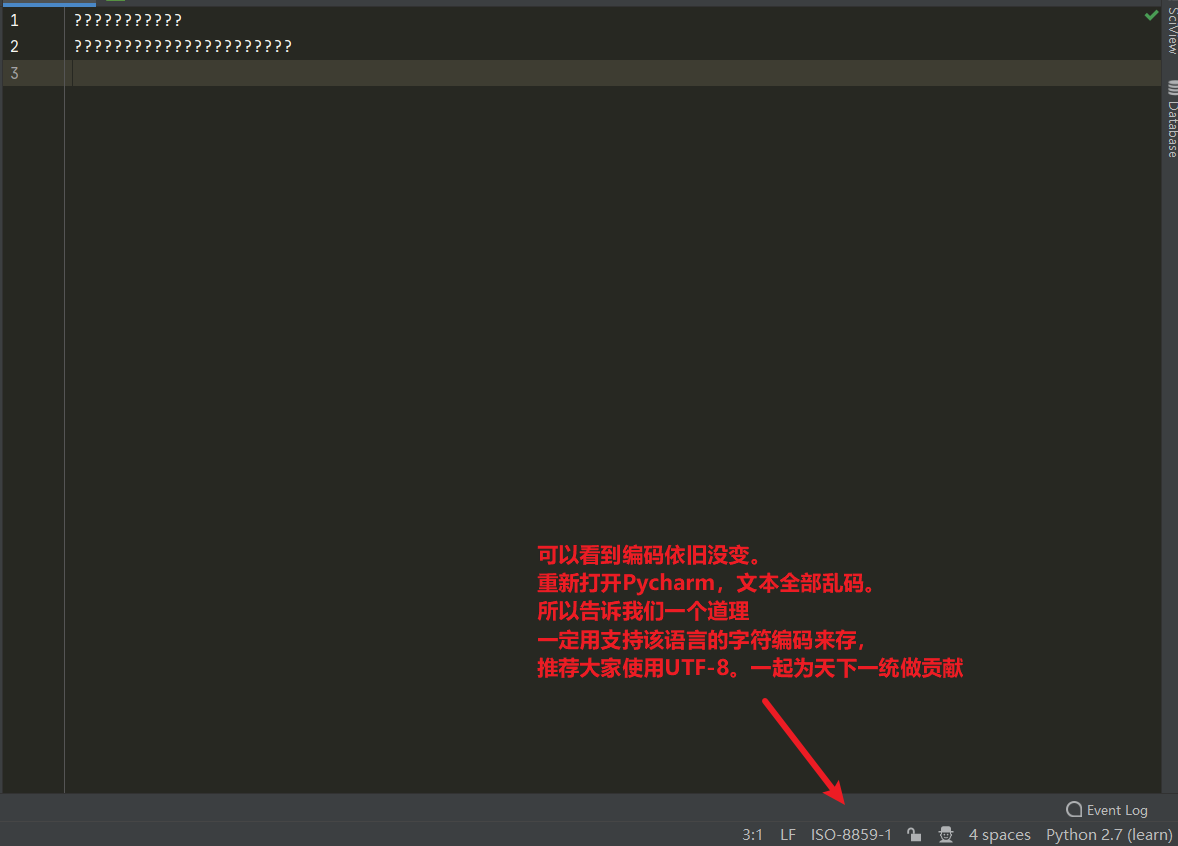
总结:用什么存的就用什么读,写的时候一定要用支持该语言的字符编码来存。不然全部是乱码,一定要使用UTF-8
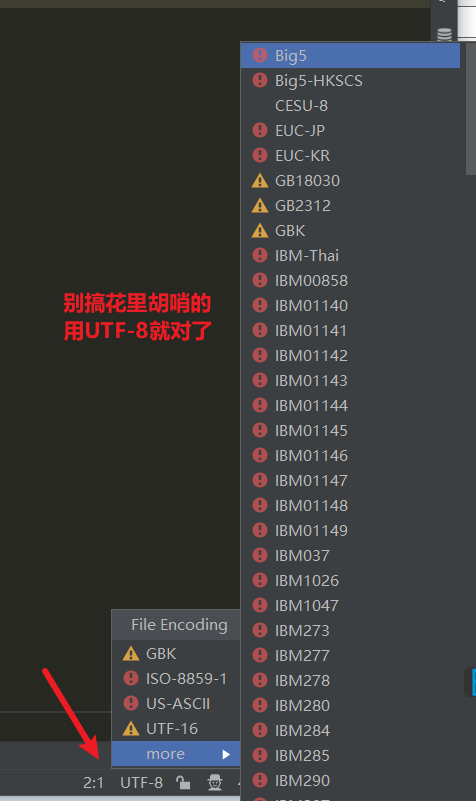
Python脚本存储时的字符编码格式
其实上面用Pycharm的时候已经做了演示了,在右下角可以指定Python脚本存储于硬盘的默认二进制字符编码格式。
Python2执行脚本时的字符编码格式
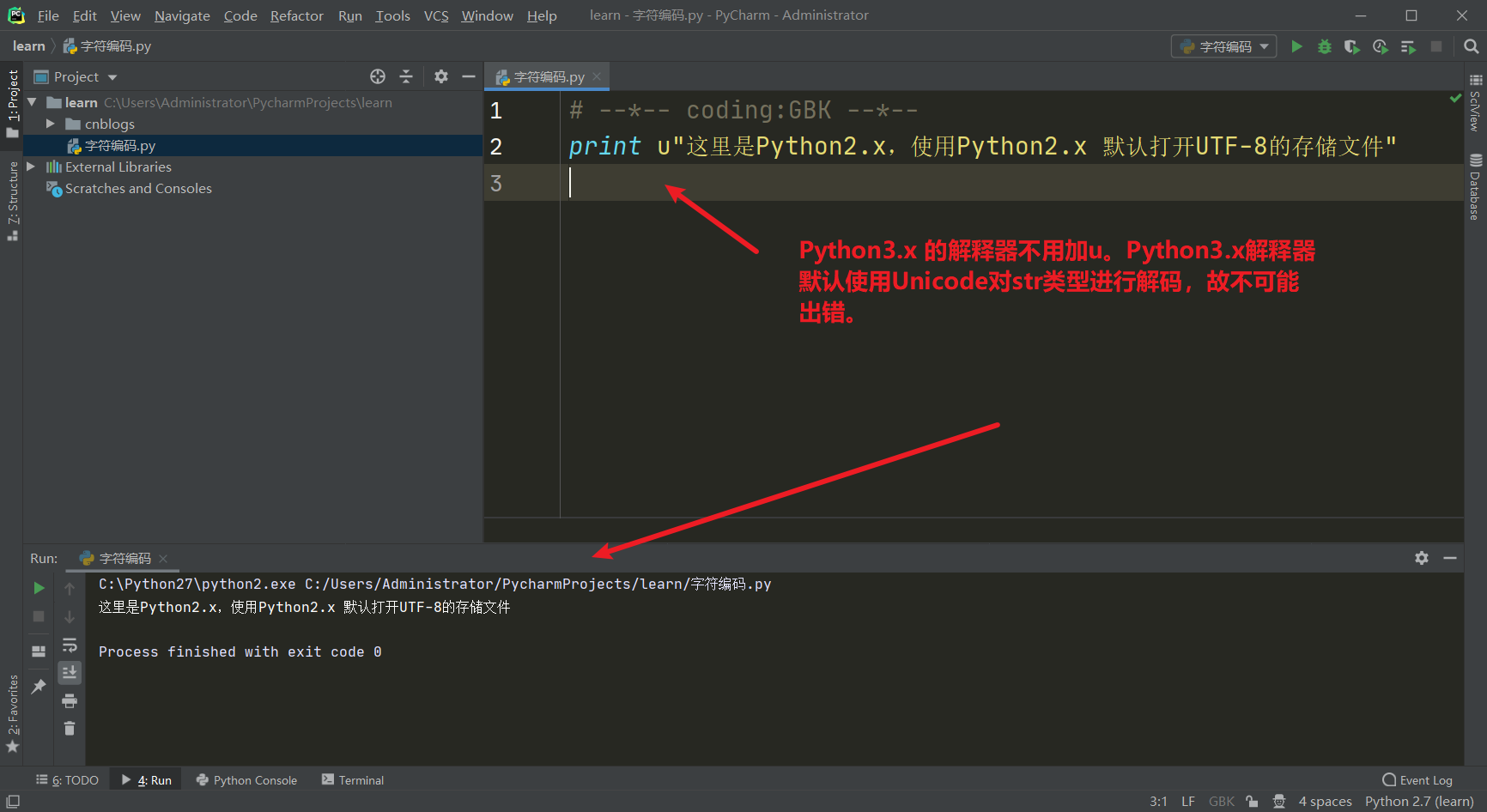
有意思的来了。Python脚本我们用UTF-8存于计算机硬盘内这个没毛病。当打开文件时也是以UTF-8的规范进行解码供我们查看代码和修改代码,这个也没毛病。但是当我们使用Python解释器进行执行的时候也是要指定编码的呀!不然会发生报错。这个其实就有2层意思了,你写好代码用UTF-8存起来,这个没毛病。也能打开,但是你解释器执行不了。为什么?我们试试。

说实话这个图我截的不是很满意,这里print后面的内容不应该写使用Python2 默认打开 UTF-8 的存储文件。而是应该执行才对。
为什么,Python2要使用ASCII码进行解码呢?因为龟叔发明Python2的时候还没有Unicode啊!!!!!!!一个是70年代,一个是90年代。你懂了吧?
Python3执行脚本时的字符编码格式
Python3 没什么好说的。解释器是用UTF-8进行解码操作,所以我们在存的时候 .py 文件一定要用UTF-8进行存储。下面我来演示一下如果使用GBK来存储,然后使用Python3的解释器默认解码来执行GBK编码的.py文件会发生什么。
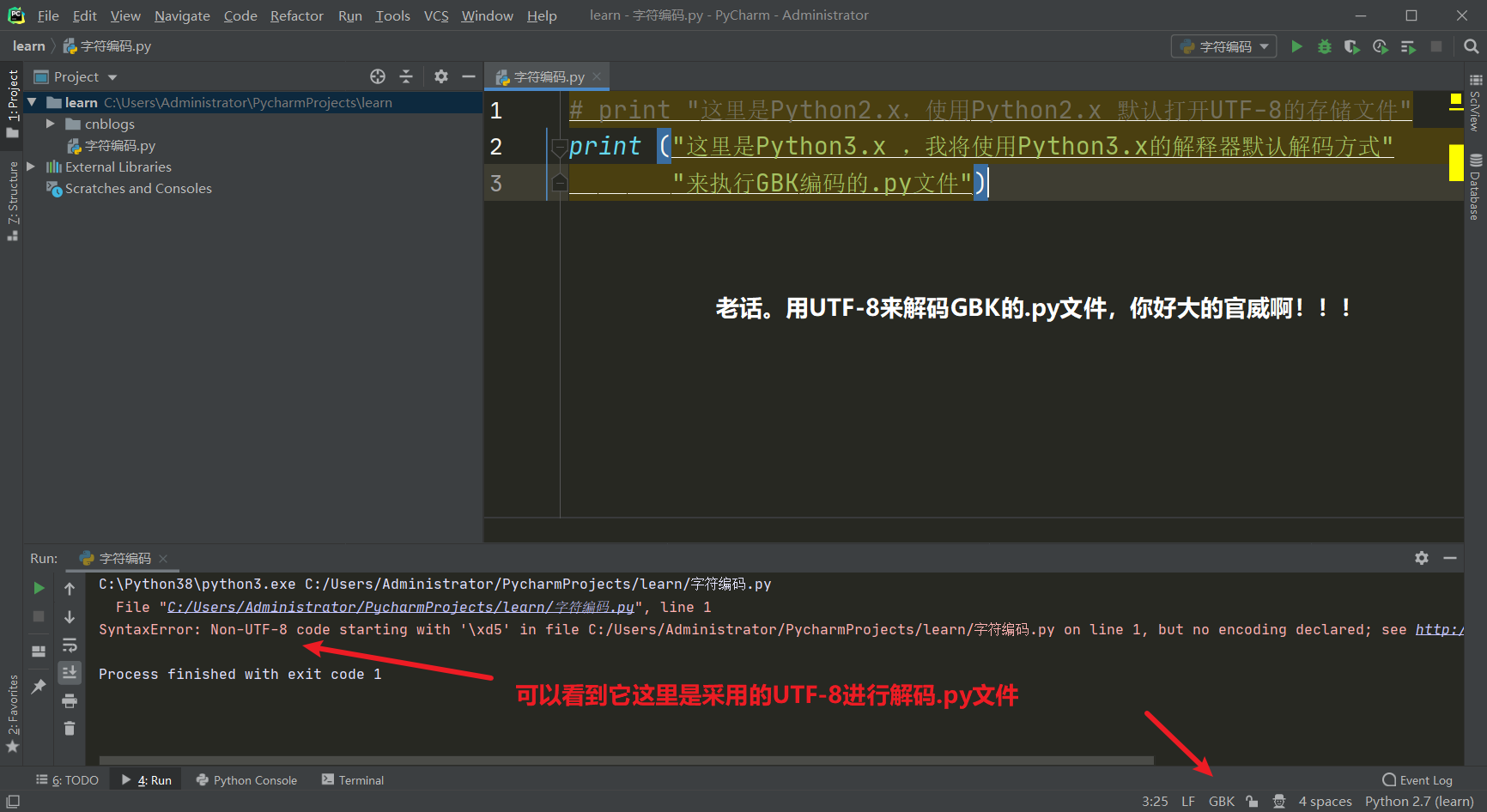
Python头文件初识:指定执行方式
好了,我们如果就想要Python3的解释器运行GBK编码的.py文件。或者说就想要Python2的解释器运行UTF-8编码的.py文件该怎么做呢?使用头文件。指定Python解释器以什么解码方式来解码这个.py文件。
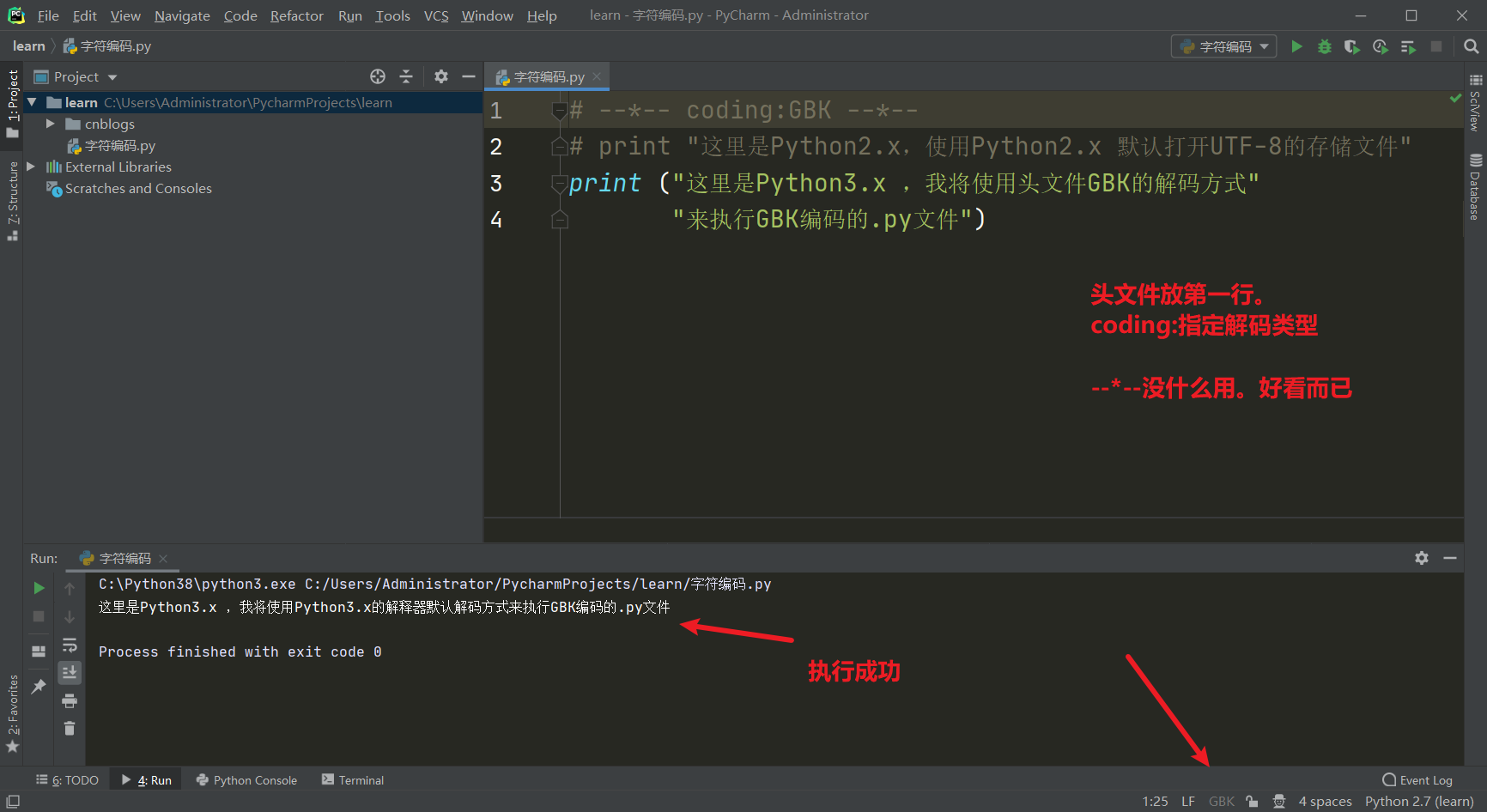
Python3对于字符串的处理
好了。接下来来点绕的,现在说到了2层解码对吧,但是切记一点。在Python脚本执行中,解释器还会找到变量,查看他变量的类型。如果是str类型,则在Python3中对于该字符串指定为Unicode解码方式(其他的如果没有头文件就按照UTF-8进行解码,如果有头文件则按照头文件进行解码)。如果是Python2,那么对不起更复杂。为什么要有第3层解码?你想。我Python解释器如果GBK来解释.py文件开始执行,而我的print()函数或者str类型的变量值中写了很多其他GBK不支持的语言怎么办?所以才会有第3层关于字符串的解释。
Python2对于字符串的处理
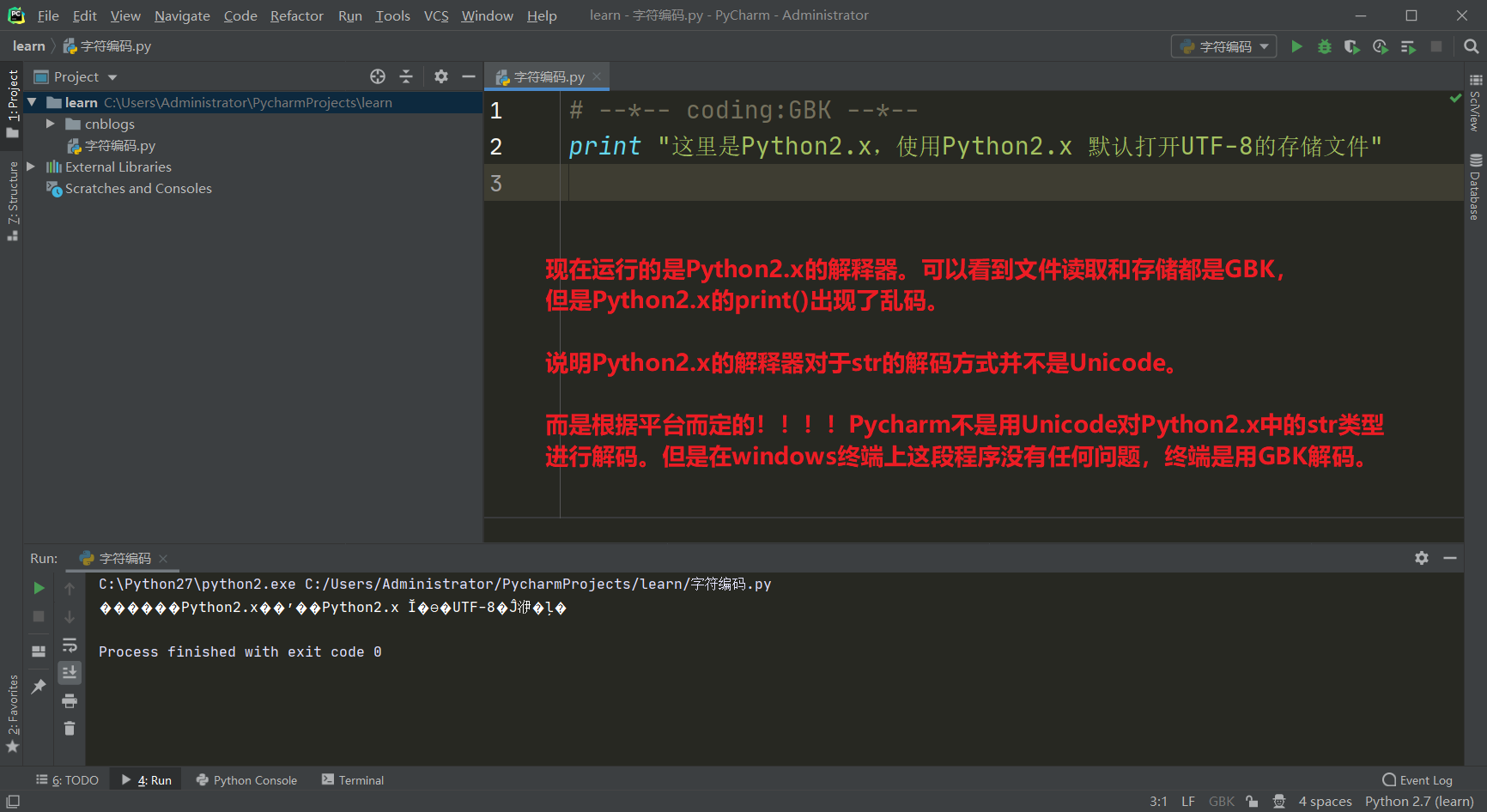
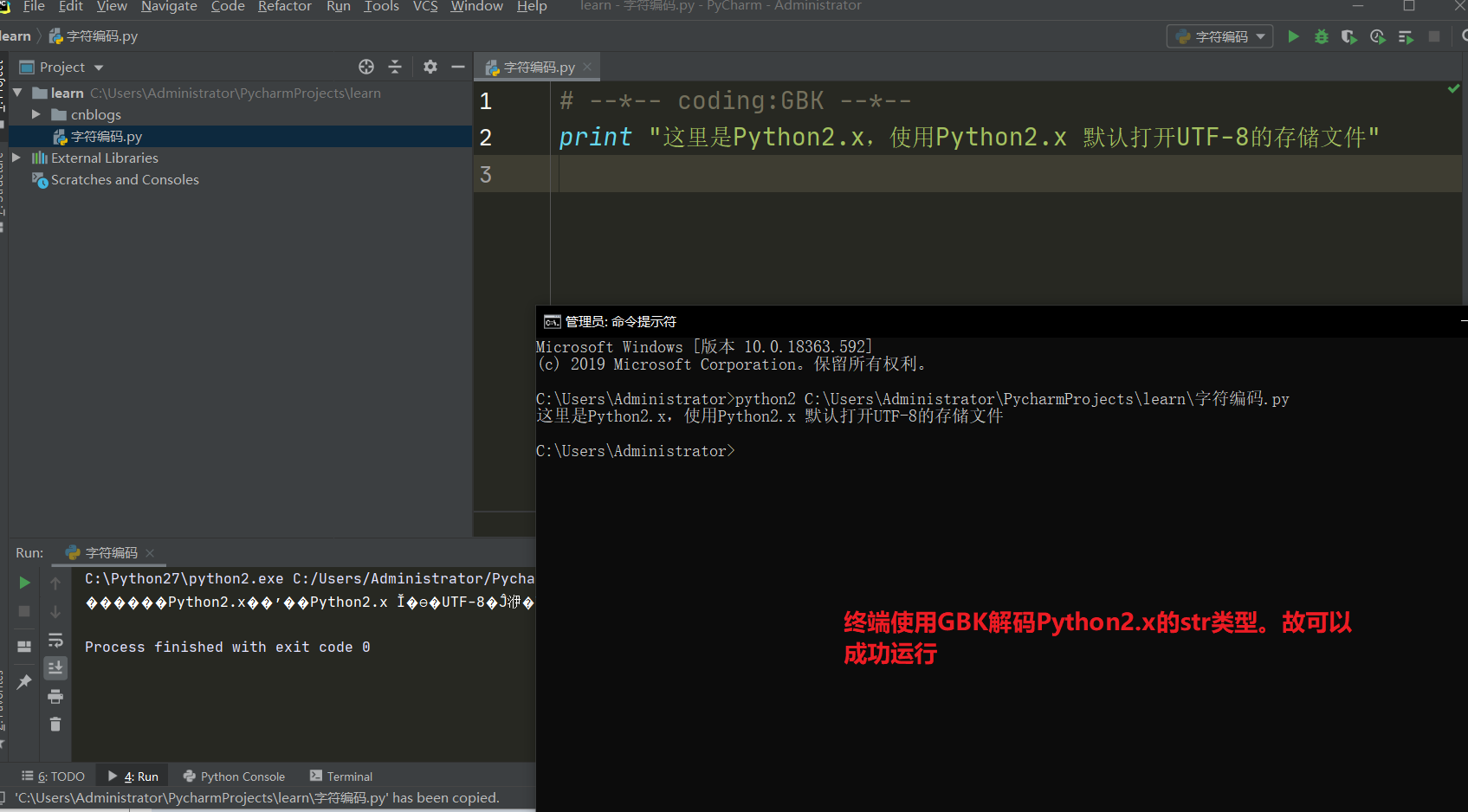
Python2中对于
str类型的解码方式:Pycharm,mac环境下全部使用
UTF-8进行解码。UTF-8来解我GBK的码,你好大的官威啊。Windows终端环境下则使用
GBK进行解码,刚好对应。所以上面的程序在Windows终端环境下执行没任何问题。
解决Python2乱码终极大招
Python3已经不说了。str类型是Unicode这个万金油进行解码,不管他好吧。
Python2中其实可以在字符串前面加上 u 来指定这个str类型的解码方式使用 Unicode。
从执行.py脚本程序的角度来说如何解决乱码问题:
写和存使用
UTF-8标准。(为了能够查看和修改脚本代码,也是第一层解码的层面)
对于Python2来说使用 头文件指定编码为
UTF-8(到了第二层解码的层面了,为了能够执行脚本文件所以要这么做,Python3默认使用UTF-8所以不用说了)
对于Python2来说
str类型前面一律加上u。指定为Unicode对str类型进行解码操作 (第三层解码层面,为了让字符串能够支持显示更多的字符所以这么做。Python3默认就使用Unicode对str类型进行解码,所以只是针对Python2)
Python中的编码解码
编码解码应用场景
编码和解码不仅仅是让人类与计算机产生交互。它还能用于网络传输与本地保存上面。网络传输中是基于字节的传输(电信号8位一组,即1字节),而本地保存在硬盘上的也是基于字节的保存(block块,扇区)。所以编码解码还是挺重要的。
encode() 编码操作
Python中提供encode()方法进行编码操作。它会返回一个bytes类型,那么这个类型的数据就可以用于网络传输以及本地保存。这个先不管,看看用法。
>>> x = "hello,中国" >>> data = x.encode("utf-8") #指定编码格式为 utf-8 。大小写均可,不写 - 都可以 >>> data b'hello,xe4xb8xadxe5x9bxbd' >>> type(data) <class 'bytes'> # 可用于网络传输的 bytes类型 >>>
decode() 解码操作
有编码方法相应的就有解码方法。Python中使用decode()方法进行解码,一定要注意。以什么方式编码就以什么方式解码!!!否则会抛出异常
>>> data.decode("utf8") 'hello,中国' >>>
Python头文件详解
头文件与Linux平台运行脚本方式
在Python中,头文件是一种特定的语法。上面已经学习了指定Python解释器的解码格式(第二层解码),其实除此之外还有一个重要的头文件。
#!/usr/bin/env python3 # -*- coding:utf-8 -*-
这个头文件的意思是,如果你是Linux环境下运行该文件。则会去到环境变量中自己寻找Python3的解释器。因为在Linux平台下支持使用 sh ./ 来直接执行一个文件而不用使用python "path"的方式来执行。所以这个头文件就是使用 ./ 或者 sh 的方式来找Python解释器的意思。env代表在环境变量中找,所以使用该头文件你的Python解释器一定要添加环境变量才行。
如果没添加环境变量,也可以直接指定Python解释器的路径。
#!/usr/bin/python3 # -*- coding:utf-8 -*-
这个代表直接到该路径下去寻找Python3的解释器。相比之下更推荐使用第一种,因为它更加灵活,不是人人的Python解释器都放在这个路径下的。
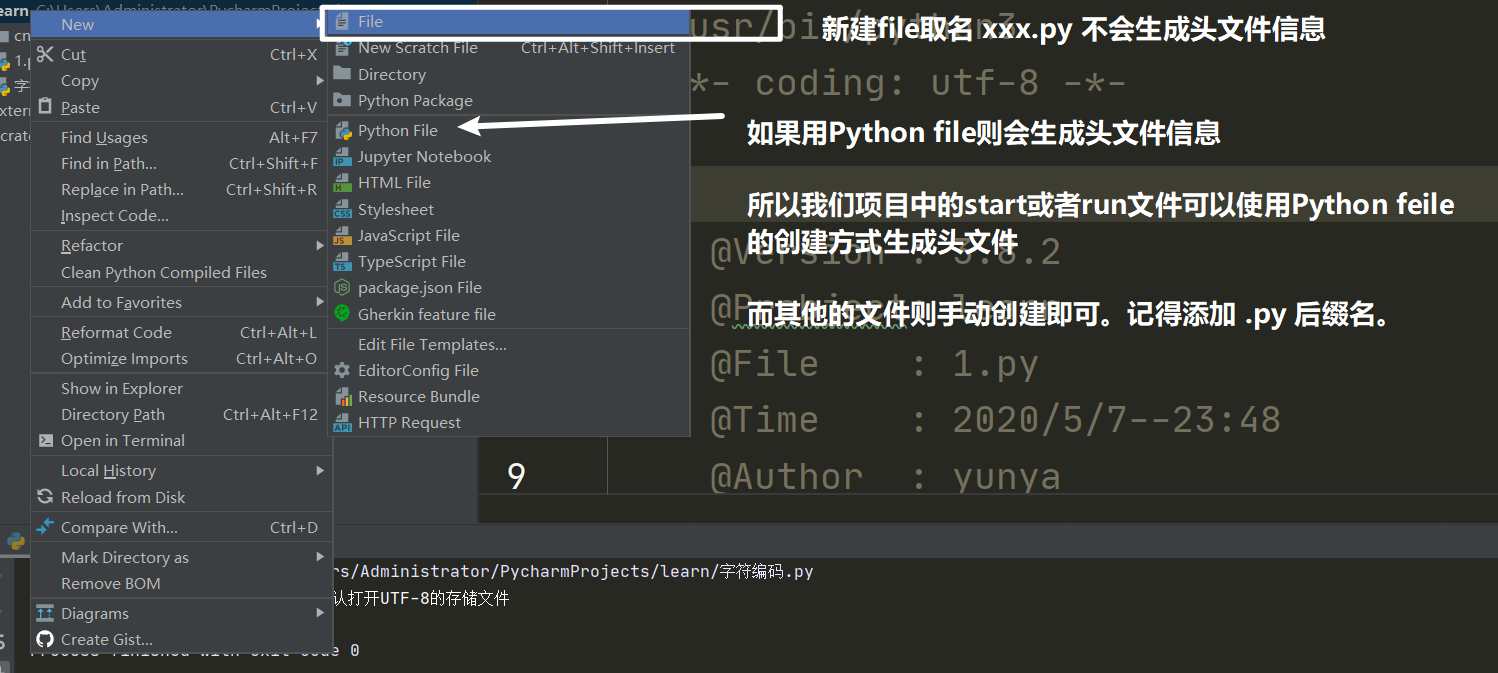
如何使用模板配置Python头文件
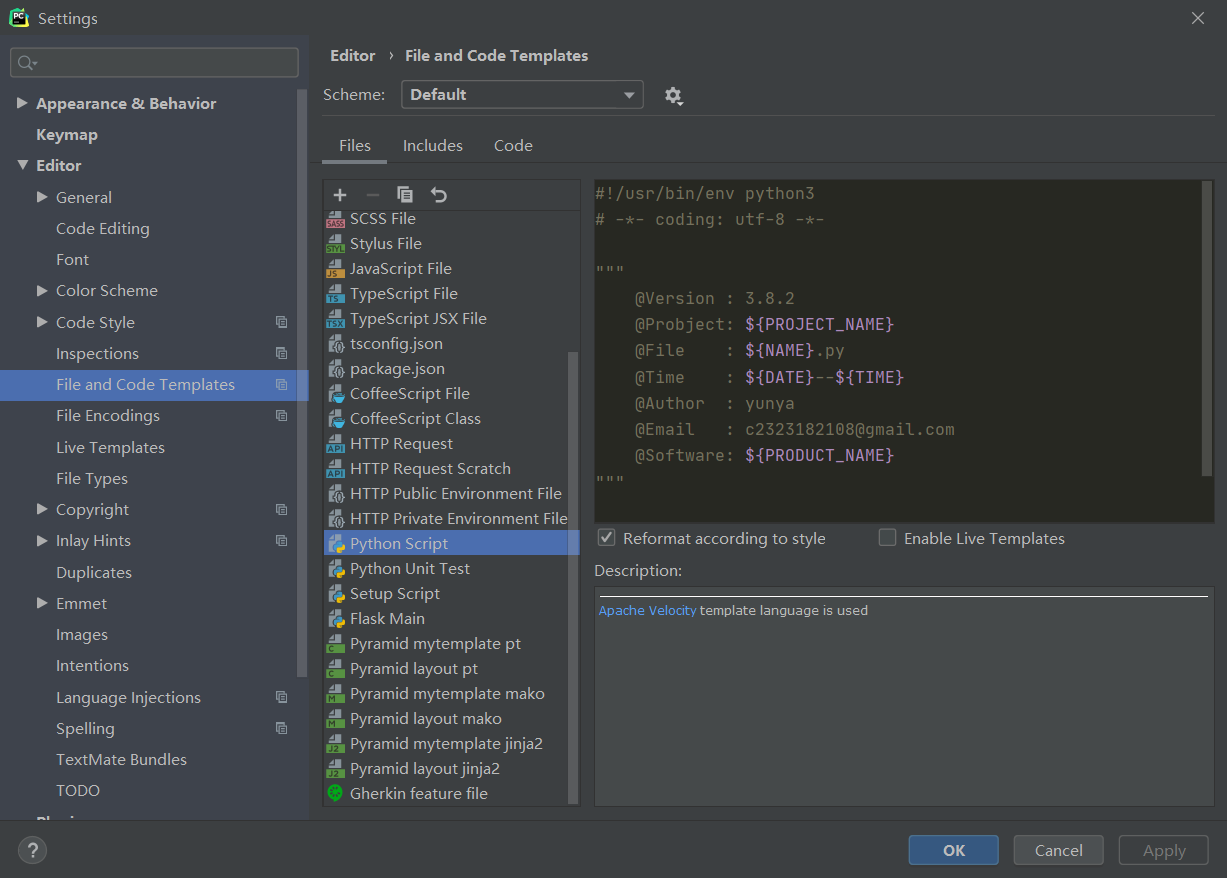
$ {PROJECT_NAME} - 当前项目的名称。
$ {NAME} - 在文件创建过程中在“新建文件”对话框中指定的新文件的名称。
$ {USER} - 当前用户的登录名。
$ {DATE} - 当前的系统日期。
$ {TIME} - 当前系统时间。
$ {PRODUCT_NAME} - 将在其中创建文件的IDE的名称。
头文件使用注意事项
注意,头文件只针对单个文件就是一个程序。把代码全部写到一个文件中可以这么做,但是项目中如果每一个文件都是写上这些 coding 啊,指定路径什么的都只是第一个start文件或者run文件起作用。其他的属于浪费,所以只需要在start文件或者run文件中指定一次就行。那么告诉你一个小妙招: