1. 首先了解下0xFF
显然,这是个16进制数,FF为1111 1111,写完整的话就是0000 0000 0000 0000 0000 0000 1111 1111,一个32位的二进制(因为0xFF存储为int类型,而int为4byte,即32bit)
2. &0xFF
这个是对0xFF做了逻辑与的操作,即1&1->1,其他都是0。要知道,计算机存储数据是按照补码的形式存储的(也有说负数才是按照补码的形式存储,但其实正数的原码和补码是一样的,所以说二者均存储补码也没什么问题)
现在设想这样一个场景:byte a = -127;,而-127对应的补码是1000 0001(byte-8bit),将 byte 作为int类型向控制台输出的时候(printf("%d",a)),编译器做了一个符号扩充的处理,因为int类型是32位二进制数,所以byte扩充后的补码就是1111111111111111111111111 10000001(32位),这个32位二进制补码表示的十进制数也是-127。这说明符号扩充并不会影响当前对应的十进制数的值。但问题在于如果我们只是想要一个相同的补码呢?即将byte转换为int后,其结果仍然是0000...0000 1000 0001,那就需要用到&0xFF了,0xFF在高24位补零,从而做逻辑与操作后其结果为0000...0000 1000 0001,当然这个时候-127就不再是-127了,所以对于0xFF的运用要慎重考量。
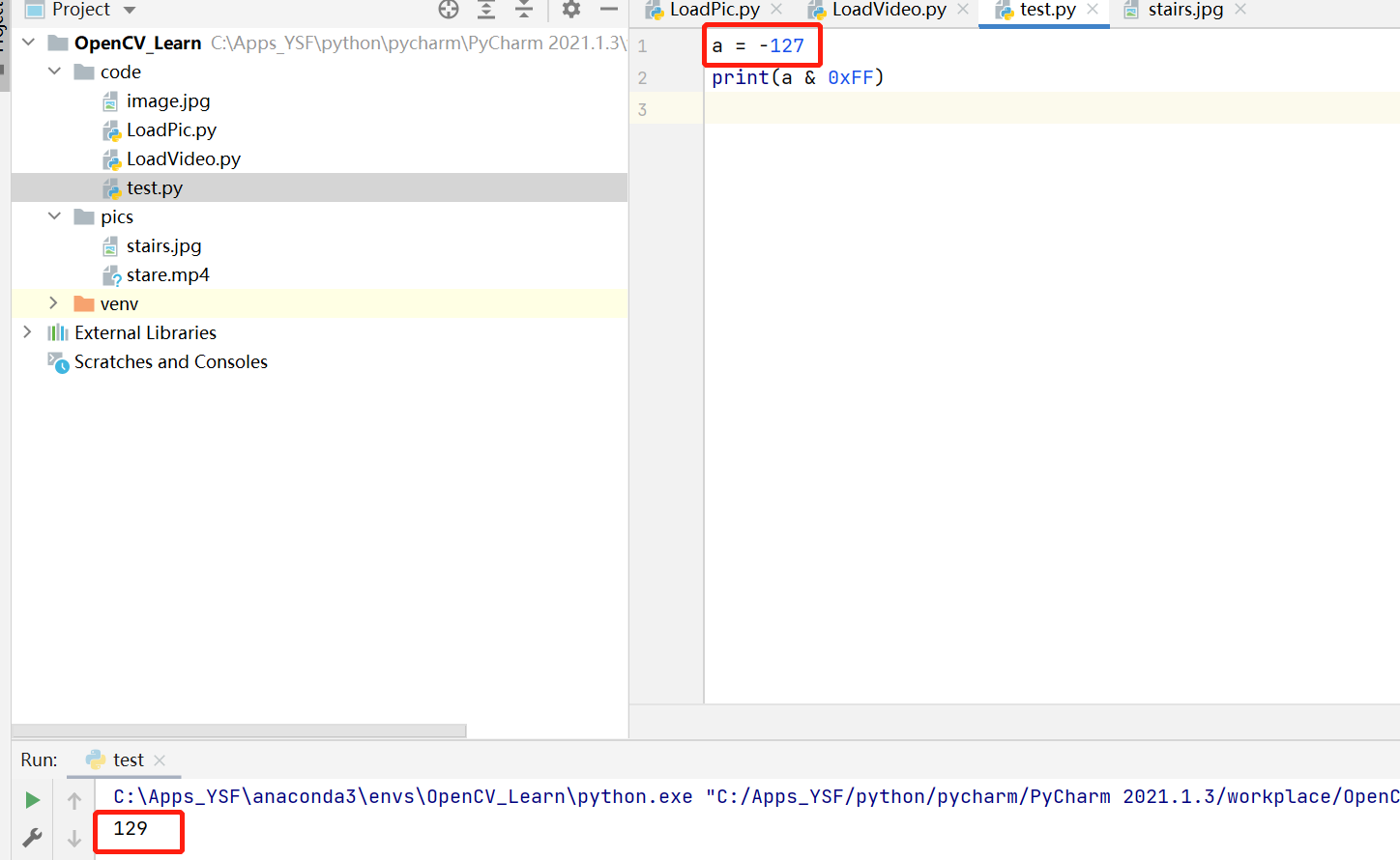
一般而言,在if cv2.waitkey(10) & 0xFF这里做的操作不是很有意义,因为这个我们键盘键入的按键值所对应的ascii码都是正数
3. cv2.waitkey(10) & 0xFF
此时这句话的意义就比较清楚了,cv2.waitkey(10)会返回在这个图片存在的10ms内根据按键值返回对应的ascii码(也有说Unicode码的,这个没有验证),然后和0xFF做逻辑与运算。由上文,这个运算在这里没有太大意义,其实指的是windows环境下无所谓,实际上在linux上使用waitkey有时会出现waitkey返回值超过了(0-255)的范围的现象。通过cv2.waitKey(1) & 0xFF运算,当waitkey返回值正常时 cv2.waitKey(1) = cv2.waitKey(1000) & 0xFF,当返回值不正常时,cv2.waitKey(1000) & 0xFF的范围仍不超过(0-255),就避免了一些奇奇怪怪的BUG。
Unicode和ascii:ASCII编码是1个字节,而Unicode编码通常是2个字节。.字母A用ASCII编码是十进制的65,二进制的01000001;而在Unicode中,只需要在前面补0,即为:00000000 01000001。
4. cv2.waitkey(10) & 0xFF = ord('s')
ord('s')返回s对应的ascii码,和左边进行比较,就知道是不是按下了's'从而做出下一步反馈
5. 等价写法
经验证,在windows下以下写法也是被接受的
# 正常写法 if cv2.waitKey(10) & 0xFF == ord('s'): break # 等价写法 cv2.waitKey(10) if cv2.waitKey() == ord('s'): break
6. 参考链接
(46条消息) cv2.waitKey的入门级理解_山上有强强的博客-CSDN博客_cv2.waitkey