本文分为四个部分,
- 第一部分 概览:根据近年来的论文,总结学术界在中文分词这个任务上的研究方向和趋势
- 第二部分 paper解读:列举几个经典的论文,帮助快速了解它们的思路和模型
- 第三部分 中文分词开源的项目和语料
- 第四部分 中文分词的评估
概览
从近年来论文的内容和数量来看,中文分词感觉快成为一个已解决的任务,几个数据集上的F1都差不多达到了96到98的水平,不过如果结合跨领域、少样本、无监督,还是有一定的研究空间。
目前,分词的研究主要有以下几个大的方向:
- 多任务:将分词和POS Tagging、依存句法分析、命名实体识别进行花式组合做联合任务;
- 模型:使用最新的神经网络模型,比如(Diao et al. 2020)[1]提出的ZEN引入了BERT;(Huang et al. 2020)[2]在BERT的基础上做多准则学习,同时做了模型优化;
- 上下文特征:采用更加丰富的上下文特征,在character embedding的基础上,(Chen et al. 2015)[3]引入了bigram character embedding,(Zhou et al. 2017)[^Word_context]引入了word-context,(Wang et al. 2019)[4]加入了拼音、五笔输入的信息,(Tian et al. 2020)[5]考虑到了wordhood information;
- 多准则学习:分词的结果不是固定,根据不同的准则有不同的切分方法,比如(chen et al. 2017)[6]提出中文分词的对抗多准则学习拿到了ACL 2017杰出论文奖;
- 跨领域分词:如何尽量降低一个领域下通过监督学习得到的模型在另一个领域的性能下滑
paper解读
Adversarial Multi-Criteria Learning for Chinese Word Segmentation. Xinchi Chen. ACL 2017
本文来自复旦大学黄萱菁、邱锡鹏团队,荣获了ACL 2017杰出论文奖。贡献点有三:一是首次把多准则引入到分词任务中来,提出三种不同的共享-私有模型,共享层用来提取和准则无关的特征,私有层则用来抽取指定准则的特征;二是在此基础上引进对抗策略,保证共享层能够抽取到共有的、底层的、准则无关的特征;三是同时在八种分词准则(对应八个数据集,五个中文简体,三个中文繁体)上进行实验。
因为分词标准不同,不同数据集对同样的句子有不同的分法,所以每种数据集都对应一种准则。本文将每种准则都看成独立的任务,并在多任务框架下提出三种模型来做对比,又考虑到对抗策略在领域适应(domain adaption)上的成功,引入对抗策略。
1. 中文分词的通用神经模型
如下图所示,模型就是bilstm + crf。
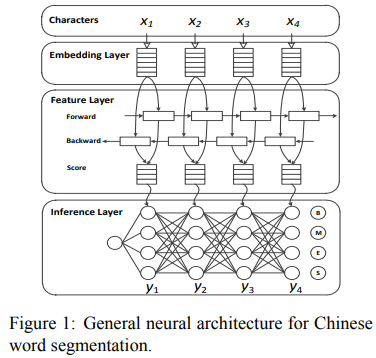
2. 中文分词的多准则学习
三个共享-私有模型如下图所示。
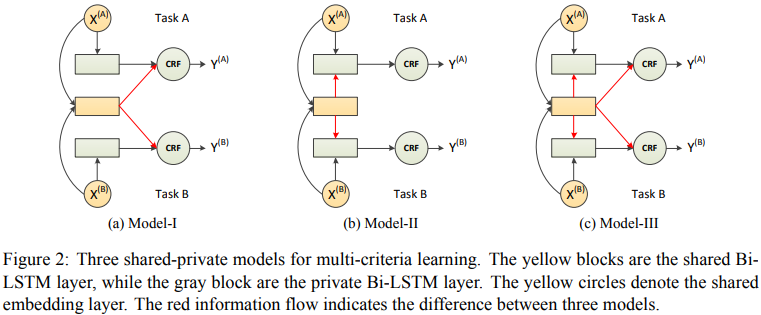
Model-I中共享层和私有层是并行的,二者的输出一起输入到CRF,Model-II把输入和共享层的输出一起输入私有层中,最终再由私有层传递到CRF层,Model-III在II的基础上,补充了共享层和crf层之间的连接。
模型的目标函数仍旧是极大似然,采用交叉熵作为损失函数。
3. 共享层融入对抗训练[7]
共享-私有模型将特征空间分成共享空间和私有空间,为了避免二者交叉,以Model-III为例,加入对抗训练来保证共享层与准则无关
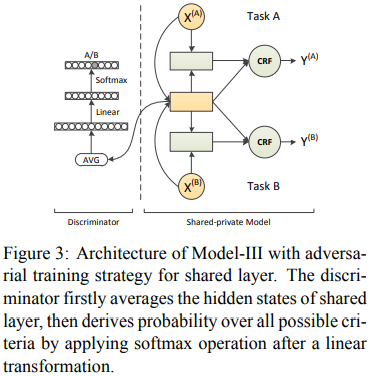
对抗训练首先会根据共享层的输出计算各个准则的预测概率,随后我们通过最大化预测准则概率分布的熵即可。
(1)计算共享层隐藏状态的平均值作为长度为n的句子X的共享特征
(2)准则预测:
其中(Theta^s)表示共享层的参数,(Theta^d)表示准则判别器的参数。
(3)判别器最大化交叉熵
(4)对抗损失
(5)总的损失函数
State-of-the-art Chinese Word Segmentation with Bi-LSTMs. Ji Ma. ACL 2018
本文是谷歌的一篇实验味较浓的论文,并且还是一如既往地追求简单且高效,其主要贡献有两点:一是实验,给bilstm引入三项深度学习技术(预训练嵌入、dropout、超参数调参),发现在很多数据集上超过了复杂的模型;二是,提出了一些guidance,通过对错误数据进行分析发现,超纲词对神经网络模型来说仍旧是一个挑战,并且大部分错误都无法通过修改模型来纠正,进一步的提高需要把更多的精力花在探索数据资源上。
1. 模型
模型就是bilstm,输入是每个字的子嵌入和词嵌入的拼接,但是和一般的bilstm相比,这里的stacking bilstm在前向和反向之间也会有连接。隐藏层单元256,标注模式采用BIES。
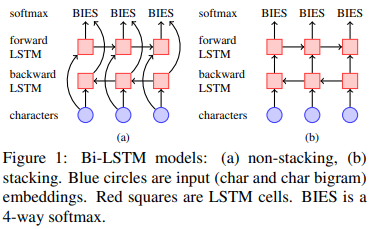
三项深度学习技术为:
- recurrent dropout
- hyperparameters: 使用SGD + momentum(超参数(mu = 0.95)),对梯度进行归一化从而保证最大为单元范数
- pretrained embeddings: 使用wang2vec[8]来训练character embedding和character-bigram embedding,zhou[9]也用了这个方法来训练词向量,同时也是本文主要参考的对象。
2. 实验
数据集是有四个:CTB 6.0、CTB 7.0、UD、SIGHAN 2005。
实验结果为:
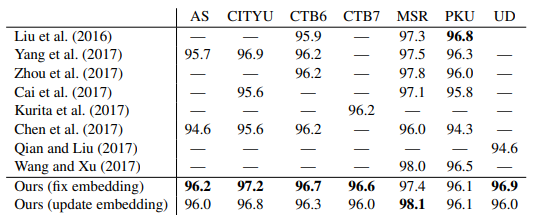
错误分析发现:三分之一是标注不一致导致,三分之二是超纲词。所以改模型基本没有很大的提升了,作者建议后面多花点心思在数据上。
3. 文章的一些其他知识点
神经网络用于学习嵌入和分词:
- Pei et al., 2014: Maxmargin tensor neural network for chinese word segmentation.
- Ma and Hinrichs, 2015: Accurate linear-time chinese word segmentation via embedding matching
- Zhang et al., 2016a: Transition-based neural word segmentation
- Liu et al., 2016: Exploring segment representations for neural segmentation models
- Cai et al., 2017: Fast and accurate neural word segmentation for chinese
- Wang and Xu, 2017: Convolutional neural network with word embeddings for chinese word segmentation
关于分词的语料
基于以上论文找到了一些关于分词的数据集:
- CTB 8.0(Chinese Treebank 8.0): 该数据集属于收费数据集,但是在国内某论坛上有提供免费下载,包含了分词、词性标注以及依存句法分析三个任务的标注数据。
- NLPCC 2016 Weibo Seg: 感谢复旦。
- SIGHAN 2005: 这个很好找,官网就有提供下载的链接,包含了AS、CityU、MSR和PKU四个数据集。
关于分词的度量方法
以下是pkuseg的度量方法:
1. 先将id形式的gold标签序列和pred标签序列转化成符号标签
2. 将两个符号标签序列转化成chunk序列(简单判断B前缀即可)
3. 根据gold chunk sequence生成集合gold_set,遍历pred chunk sequence,如果当前chunk存在于gold_set,correct加1
4. 准确率等于correct除以pred chunk sequence的长度,召回率等于correct除以gold chunk sequence的长度
ZEN: Pre-training Chinese Text Encoder Enhanced by N-gram Representations. Shizhe Diao. ACL 2020 ↩︎
Towards Fast and Accurate Neural Chinese Word Segmentation with Multi-Criteria Learnin. Weipeng Huang. COLING 2020 ↩︎
Long Short-Term Memory Neural Networks for Chinese Word Segmentation. Xinchi Chen. EMNLP 2015 ↩︎
Multiple Character Embeddings for Chinese Word Segmentation. Jingkang Wang. ACL 2019 ↩︎
Improving Chinese Word Segmentation with Wordhood Memory Networks. Yuanhe Tian. ACL 2020 ↩︎
Adversarial Multi-Criteria Learning for Chinese Word Segmentation. Xinchi Chen. ACL 2017 ↩︎
Generative Adversarial Nets. Ian Goodfellow. NIPS 2014 ↩︎
Two/too Simple Adaptations of Word2vec for Syntax Problems. Wang Ling. 2015 ↩︎
Word-context Character Embeddings for Chinese Word Segmentation. Hao Zhou. 2017 ↩︎