| key | value |
|---|---|
| 名称 | Pre-training with Whole Word Masking for Chinese BERT |
| 一作 | 崔一鸣 |
| 单位 | 哈工大; 讯飞实验室 |
| 发表 | 技术报告 |
| 时间 | 2019.10 |
| 领域 | 预训练模型 |
| 主要贡献 | 将whole word masking方法用在中文预训练上 |
| 摘要 | Bidirectional Encoder Representations from Transformers (BERT) has shown marvelous improvements across various NLP tasks. Recently, an upgraded version of BERT has been released with Whole Word Masking (WWM), which mitigate the drawbacks of masking partial WordPiece tokens in pre-training BERT. In this technical report, we adapt whole word masking in Chinese text, that masking the whole word instead of masking Chinese characters, which could bring another challenge in Masked Language Model (MLM) pre-training task. The proposed models are verified on various NLP tasks, across sentence-level to document-level, including machine reading comprehension (CMRC 2018, DRCD, CJRC), natural language inference (XNLI), sentiment classification (ChnSentiCorp), sentence pair matching (LCQMC, BQ Corpus), and document classification (THUCNews). Experimental results on these datasets show that the whole word masking could bring another significant gain. Moreover, we also examine the effectiveness of the Chinese pre-trained models: BERT, ERNIE, BERTwwm, BERT-wwm-ext, RoBERTa-wwm-ext, and RoBERTa-wwm-ext-large. |
| 论文链接 | https://arxiv.org/pdf/1906.08101.pdf |
| 源码链接 | https://github.com/ymcui/Chinese-BERT-wwm |
Whole Word Masking(WWM)

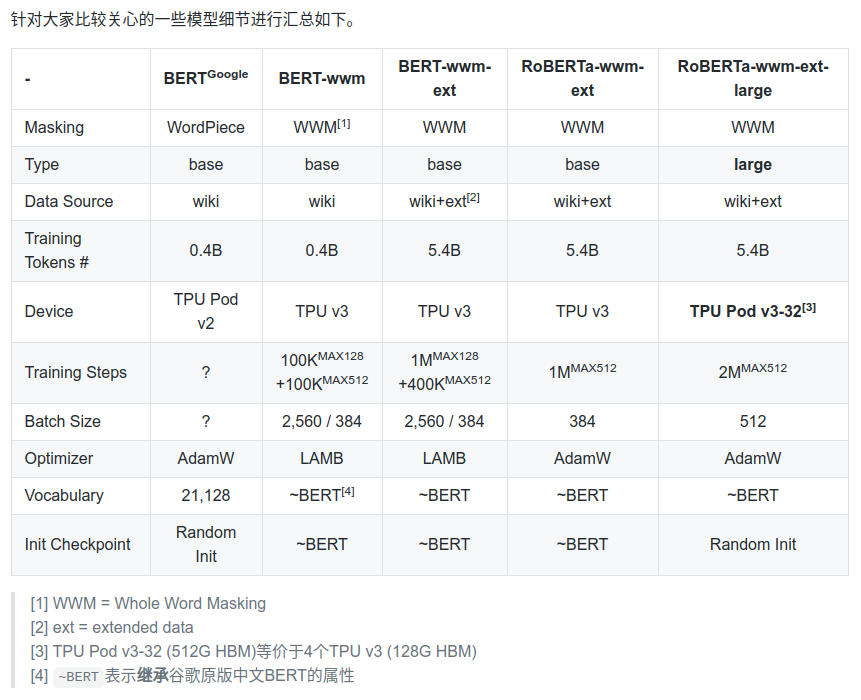
模型列表
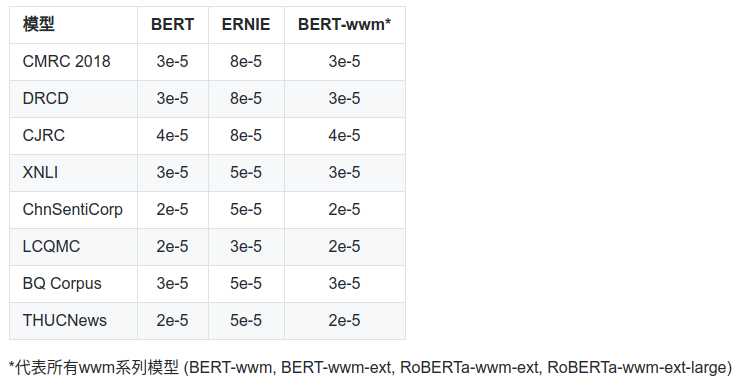
最佳学习率
论文给出的实践经验总结
- 初始学习率是非常重要的一个参数(不论是BERT还是其他模型),需要根据目标任务进行调整;
- ERNIE的最佳学习率和BERT/BERT-wwm相差较大,所以使用ERNIE时请务必调整学习率(基于以上实验结果,ERNIE需要的初始学习率较高);
- 由于BERT/BERT-wwm使用了维基百科数据进行训练,故它们对正式文本建模较好;而ERNIE使用了额外的百度贴吧、知道等网络数据,它对非正式文本(例如微博等)建模有优势;
- 在长文本建模任务上,例如阅读理解、文档分类,BERT和BERT-wwm的效果较好;
- 如果目标任务的数据和预训练模型的领域相差较大,请在自己的数据集上进一步做预训练;
- 如果要处理繁体中文数据,请使用BERT或者BERT-wwm。因为我们发现ERNIE的词表中几乎没有繁体中文;
虽然这是一篇技术报告,但是本文开源出来的预训练模型价值非常高,再加上一些中肯的实验技巧,它的重要性甚至超过普通的创新论文。