对CUDA架构而言,主机端的内存可分为两种,一种是pageable memory,即可分页内存;另一种是pinned memory,即页锁定内存。
主机默认分配的是pageable memory,也就是说,根据操作系统的指示,主机虚拟内存(内存空间很小,所以内存只放部分数据,其余不重要的放在硬盘中,看成虚拟内存。)中的数据会对应到不同的物理位置。于是就会产生一种错觉,那就是虚拟内存具有很大的空间。
然而GPU无法安全地访问pageable memory中的数据,因为它无法控制操作系统去移动这些物理数据,所以当我们要把数据从主机的虚拟内存移动到显卡设备的显存中去时,CUDA驱动程序会首先分配临时的pinned memory,然后将主机数据复制并固定到临时pinned memory,由于此时GPU是知道pinned memory的物理内存地址的,所以它可以通过直接内存访问(Direct Memory Access,DMA)在主机和GPU之间快速复制数据。如下图所示:
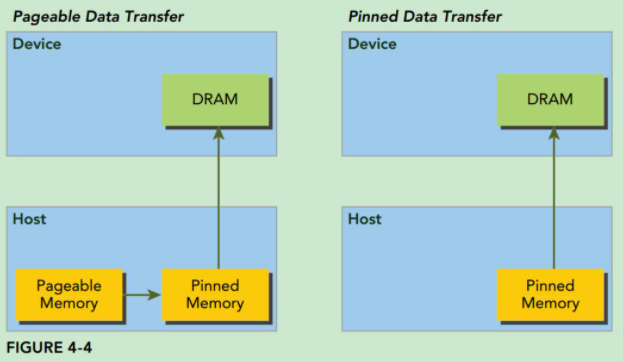
先比pageable memory,pinned memory的访问速度更快,实验对比,pinned memory的访问时间是前者的一半(0.0167043对比0.0214238);但缺点就是比pageable memory更消耗内存。使用pinned memory就会失去虚拟内存的功能,尤其是在应用程序中使用每个页锁定内存时都需要分配物理内存,而且这些内存不能交换到磁盘上。这将会导致系统内存会很快的被耗尽,因此应用程序在物理内存较少的机器上会运行失败,不仅如此,还会影响系统上其他应用程序的性能。
C++中,通过操作系统接口malloc()函数在主机上分配pageable memory,通过CUDA函数cudaHostAlloc()在主机上分配pinned memory
所以pytorch考虑到一般情况下内存都不够放数据的,所以的pinnned memory都默认设置为False。
参考资料:
https://www.cnblogs.com/biglucky/p/4305131.html
https://www.cnblogs.com/mtcnn/p/9411864.html
https://nanxiao.me/cuda-programming-note-13-pinned-memory/