torch 深度学习(3)
前面我们已经完成对数据的预处理和模型的构建,那么接下来为了训练模型应该定义模型的损失函数,然后使用BP算法对模型参数进行调整
损失函数 Criterion
加载包
require 'torch'
require 'nn' -- 各种损失函数也是 'nn'这个模块里面的
设定命令行参数
if not opt then
print "==> processing options:"
cmd = torch.CmdLine()
cmd:text()
cmd:text('Options:')
cmd:text()
cmd:option('-loss','nll','type of loss function to minimize: nll | mse | margin')
-- nll: negative log-likelihood; mse:mean-square error; margin: margin loss(SVM 类似的最大间隔准则)
cmd:text()
opt=cmd:parse(arg or {})
model = nn. Sequential()
-- 这个model主要是为了能够使该损失函数文件能够单独运行,最后运行整个项目时,并不会执行到这里
end
定义损失函数
noutputs = 10 -- 这个主要是 mse 损失函数会用到
if opt.loss == 'margin' then
criterion = nn.MultiMarginCriterion()
elseif opt.loss == 'nll' then
-- 由于negative log-likelihood 计算需要输入是一种概率分布,所以需要对模型输出进行适当的归一化,一般可以使用 logsoftmax层
model:add(nn.LogSoftMax()) --注意这里输出的是向量,概率分布
criterion = nn.NLLCriterion()
elseif opt.loss = 'mse' then
-- 这个损失函数用于数据的拟合,而不是数据的分类,因为对于分类问题,只要分正确就可以,没必要非得和标号一致。而且对于分类问题,比如两类,可以标号为 1,2,也可以标号为3,4,拟合并没有实际意义。
-- 这里主要是顺便了解一下如何定义,并不会用到这个损失函数
criterion = nn.MSECriterion()
-- Compared to the other losses, MSE criterion needs a distribution as a target, instead of an index.
-- So we need to transform the entire label vectors:
if trainData then
-- convert training labels
local trsize = (#trainData.labels)[1]
local trlabels = torch.Tensor(trsize,noutputs)
trlabels:fill(-1)
for i=1,trsize then
trlabels[{i,trainData.labels[1]}] =1 -- 1表示属于该类
end
trainData.labels=trlabels
-- convert test labels
local tesize = testData.labels:size()[1]
local telabels = torch.Tensor(tesize,noutputs):fill(-1)
for i=1,tesize do
telabels[{{i},{testData.labels[i]}}]=1
end
testData.labels=telabels
end
else
error('unknown -loss')
end
print ('损失函数为')
print (criterion)
可以发现损失函数的定义很简单,都是一句话的事,只是在调用对应的损失函数时要注意损失函数的输入输出形式。更多的损失函数定义和使用方法见torch/nn/Criterions
模型的训练
加载模块
require 'torch'
require 'xlua' -- 主要用于显示进度条
require 'optim' -- 包含各种优化算法,以及混淆矩阵
预定义命令行
if not opt then
print '==> processiing options:'
cmd=torch.CmdLine()
cmd:text()
cmd:text('options:')
cmd:text()
cmd:option('-save','results','subdirectory to save/log experiments in') --结果保存路径
cmd:option('-visualize',false,'visualize input data and weights during training')
cmd:option('-plot',false,'live plot') -- 这两个参数可以参见optim/Logger的用法
-- 下面的几个参数就是关于优化函数和对应参数的了
cmd:option('-optimization','SGD','optimization method: SGD | ASGD | CG | LBFGS')
-- 分别是随机梯度下降法、平均梯度下降法、共轭梯度法、线性BFGS搜索方法
cmd:option('-learningRate',1e-3,'learning rate at t=0') -- 步长
cmd:option('-batchSize',1,'mini-batch size (1 = pure stochastic)') -- 批量梯度下降法的大小,当大小为1时就是随机梯度下降法
cmd:option('-weightDecay',0,'weight decay (SGD only)') -- 正则项系数衰减速度
cmd:option('-momentum',0,'momentum (SGD only)') --惯性系数
cmd:option('-t0',1, 'start averaging at t0 (ASGD only) in nb of epochs)
cmd:option('-maxIter',2,'maximum nb of iterations for CG and LBFGS') --最大迭代次数,CG和LBFGS使用
cmd:text()
end
这里要说明下。传统的随机梯度下降法,一般就是 ,其中
,其中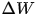 是上一步的梯度,
是上一步的梯度,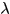 是学习速率,就是步长,步长太大容易导致震荡,步长太小容易导致收敛较慢且可能掉进局部最优点,所以,一般算法开始时会有相对大一点的步长,然后步长会逐步衰减。
是学习速率,就是步长,步长太大容易导致震荡,步长太小容易导致收敛较慢且可能掉进局部最优点,所以,一般算法开始时会有相对大一点的步长,然后步长会逐步衰减。
为了使BP算法有更好的收敛性能,可以在权值的更新过程中引入“惯性项”,也就是上一次的梯度方向和这一次梯度方向的合成方向作为新的搜索方向,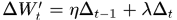 ,这里的惯性系数
,这里的惯性系数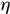 就是参数momentum
就是参数momentum
正则项主要是为了防止模型过拟合,控制模型的复杂度。
定义了一些分析工具
classes = {'1','2','3','4','5','6','7','8','9','0'}
confusion = optim.ConfusionMatrix(classes) -- 定义混淆矩阵用于评价模型性能,后续计算正确率,召回率等
trainLogger = optim.Logger(paths.concat(opt.save,'train.log'))
testLogger = optim.Logger(paths.concat(opt.save,'test.log'))
-- 创建了两个记录器,保存训练日志和测试日志
混淆矩阵参见混淆矩阵,optim里面的ConfusionMatrix 主要使用到的有三个量 一个是 valid,也就是召回率 TPR(True Positive Rate), 一个是 unionValid,这个值是召回率和正确率的一个综合值 unionValid = M(t,t)/(行和+列和-M(t,t)),M(t,t)表示矩阵对角线的第t个值
最后一个就是整体的评价指标 totalValid = sum(diag(M))/sum(M(:))
开始训练
if model then
parameters,gradParameters = model:getParameters()
end
注意 torch中模型参数更新方式有两种,一种直接调用函数updateParameters(learningRate)更新,另一种就要手工更新,即parameters:add(-learningRate,gradParameters),具体请参看torch/nn/overview
接下来定义训练函数
function train()
epoch = epoch or 1
-- 所有样本循环的次数
local time = sys.clock() -- 当前时间
shuffle =torch.randperm(trsize) -- 将样本次序随机排列permutation
for t=1,trsize,opt.batchSize do --批处理,批梯度下降
xlua.progress(t,trainData:size()) --进度条
inputs={} --存储该批次的输入
targets ={} -- 存储该批次的真实标签
for i=t,math.min(t+opt.batchSize-1,trainData:size()) do --min操作是处理不能整分的情况
local input = trainData.data[shuffle[i]]:double()
local target = trainData.labels[shuffle[i]]
table.insert(inputs,input)
table.inset(targets,target)
end
-- 定义局部函数,这个函数作为优化函数的接口函数
local feval = function(x)
if x~=parameters then
parameters:copy(x)
end
gradParameters:zero() -- 每一次更新过程都要清零梯度
local f=0 -- 累积误差
for i=1,#inputs do
local output = model:forward(inputs[i])
local err = criterion:forward(output,targets[i]) -- 前向计算
f=f+err -- 累积误差
local df_do = criterion:backward(output,targets[i]) -- 反向计算损失层梯度
model:backward(inputs[i],df_do) -- 反向计算梯度,这里的梯度已将保存到gradParameters中,下面会解释为什么
local _, indice = torch.sort(output,true)
confusion:add(indices[1],targets[i])
-- 更新混淆矩阵,参数分别为预测值和真实值,add操作是在混淆矩阵的[真实值][预测值]位置加1
-- ==Note==需要注意的是,教程上这里代码错了,他没有对output进行排序,而是直接将output放入confusion的更新参数中,但是output是一个向量,那样会导致得到的矩阵只有一行更新。。。我排查了好久。。。
end
gradParamters:div(#inputs)
f=f/#inputs
-- 因为是批处理,所以这里应该计算均值
return f, gradParameters
end
-- feval 这个函数的形式可以参见优化方法的定义,下面有链接
-- 开始优化
if opt.optimization == 'CG' then
config = config or {maxiter = opt.maxIter}
optim.cg(feval,parameters,config)
elseif opt.optimization == 'SGD' then
config =config or {learning = opt.learningRate,
weightDecay = opt.weightDecay,
learningRateDecay = 5e-7} --最后一个参数是步长的衰减速率
optim.sgd(feval,parameters,config)
elseif opt.optimization=='LBFGS' then
config =config or {learning = opt.learningRate,
maxIter =opt.maxIter,
nCorrection = 10}
optim.lbfgs(feval,parameters,config)
elseif opt.optimization=='ASGD' then
config = config or {eta0 = opt.learningRate, t0 = trsize*opt.t0}
_,_,average = optim.asgd(feval,parameters,config)
else
error ('unknown -optimization method')
end
end
-- 这里关于各种优化函数的原型请参考[1]
-- 遍历一次进行记录
time =sys.clock()-time --时间
time =time/trainData:size() -- 平均时间
print(confusion) --这里显示了混淆矩阵
-- confusion:zero() --混淆矩阵清零为了下一次遍历 注意!文档中这句话也放错了位置,因为还没log不能清空,应该放到后面
trainLogger:add{['% mean class accuracy (train set)'] = confusion.totalValid*100} -- 这个地方保存的是 accuracy
if opt.plot then
trainLogger:style{['% mean class accuracy (train set)']='-'}
trainLogger.plot() -- 绘制随着迭代进行,结果的变化趋势图
end
confusion:zero() --混淆矩阵清零为了下一次遍历 应该放到这里
local filename = paths.concat(opt.save,'model.net')
os.excute('mkdir -p ' .. sys.dirname(filename)) --创建文件
torch.save(filename,model) --在新文件中保存模型
epoch =epoch+1
end
这里稍微有点难以理解的是,每一次计算梯度,梯度是怎么更新的呢?我们并没有显示的见到梯度是如何更新的。
这主要是因为 'parameters,gradParameters = model:getParameters()'这个函数其实返回的是指针,然后在优化函数中对参数进行了更新,比如我们看看 sgd中有部分代码
...
x:add(-clr,state.deltaParameters)
else
x:add(-clr,dfdx)
end
这里x就是 我们调用时输入的parameters指针,dfdx就是调用的函数feval返回的gradParameters指针。
另外 'model:backward(inputs[i],df_do)'函数内部修改了gradParamters上的值,因为指针传递,所以没有返回值。
补充一点 epoch,batchSize和iteration关系
随机梯度法是将所有的样本一次送到模型中进行训练,那么后输入的样本调整了模型后并不能保证之前的样本获得的结果仍然很好,这时候就要重复的输入样本,让系统慢慢慢慢的收敛到对所有的样本都能有一个较好的结果。
而1个epoch就等于将所有的训练集中的样本训练一次
1个batchSize是每次进行梯度更新所采用的样本的个数,如果batchsize=1的话就是最简单的随机梯度下降法,batchSize=#{训练集},那么就是梯度下降法
1个iteration 等于使用batchsize个样本训练一次
实验结果
这里就不给结果了,等下一节,学习了如何测试数据,同时给出模型训练结果,和测试结果的变化。