RNN
循环神经网络。像之前的CNN只能处理单独的输入,前一个输入与后一个输入没有关系。但例如NLP中,我们需要前后文的信息。所以RNN应运而生。
标准的RNN中,1)N input -- N output 2)权值共享,W、U、V每个都是一样的。
实际中,这一种结构无法解决所有问题。所以也有了以下变形:
1)输入序列 N,输出一个。例如文本情感分类
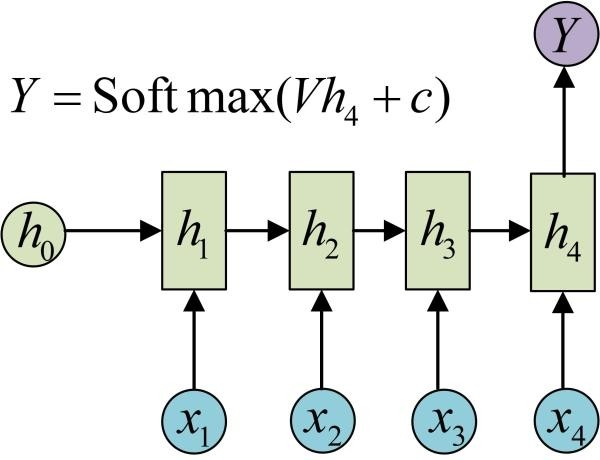
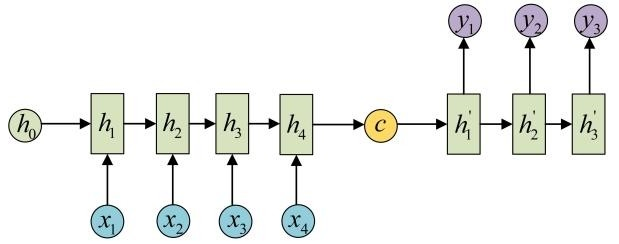
2)输入 序列M,输出序列N,不等长。
这种结构又叫做Encoder-Decoder,也可称为Seq2Seq模型。其结构原理是先编码后解码。左侧的RNN用来编码得到 C,再由右侧的RNN对 C 进行解码。
其中得到 C 的方法有很多种:
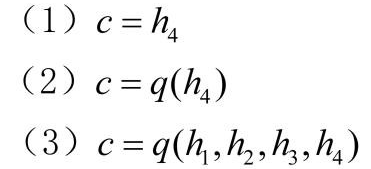
RNN的训练方法——BPTT
BPTT 即 Back-propagation through time 基于时间反向传播,本质还是BP算法,只不过要基于时间反向传播。
在最朴素的RNN,也即 N - N 的场景下:


其中 X 是输入序列,S 是状态序列(记忆),X 是输入序列, O 是输出序列。下文中 O 以 E 代替,因为参考的博客中写的是E,方便截图公式 :P
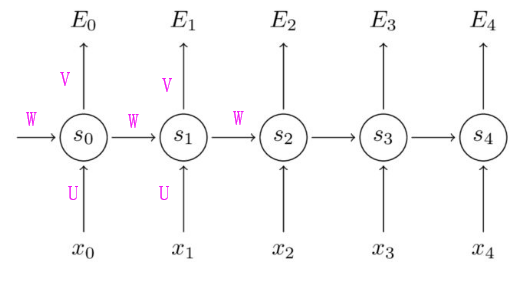
RNN的公式如下:
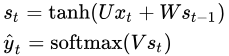
Z = V * St
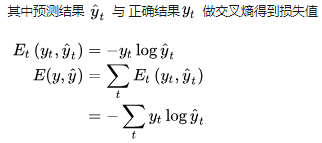
因为RNN中损失是累加的,所以总损失需要求和。
Just like we sum up the errors, we also sum up the gradients at each time step for one training example
例如:

以第 3 时刻为例,对 V 求导(最简单,因为只依赖当前时刻,求导到 Z 就结束了,没有到 S)。其中 Z3 = V * S3
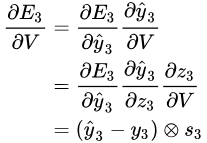
对 W 求导(与对 U 求导类似),他们都依赖于前面的时刻,因为需要经过 S:
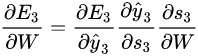
然而 S3 又依赖于前一时刻的 S2 和 W,不能把 S3 当成简单的常数看待,需要继续打开链式法则:
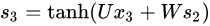
于是展开求和得:
 (将此处的 “3” 替代为 “t”,即为求 t 时刻的通用公式)
(将此处的 “3” 替代为 “t”,即为求 t 时刻的通用公式)
We sum up the contributions of each time step to the gradient. In other words, because
is used in every step up to the output we care about, we need to backpropagate gradients from
through the network all the way to
:
每个时间步长,W 都有贡献,所以 加和起来

和传统神经网络的主要区别就是,在RNN中,需要把每个时间步长的 W 加和起来。
在传统神经网络中,我们不会跨 layer 共享参数,所以求导时不需要做加和操作。
通俗来讲,BPTT其实就是在展开的RNN上进行传统的反向传播。
 是对 S 自己的连式法则,例如:
是对 S 自己的连式法则,例如: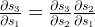
所以对 W 求导的公式可重写成:
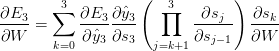
对 V 求导同理。
梯度消失
对于上面推导的公式:
其中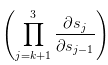 =
= 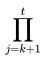
 =
= 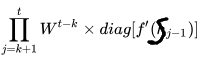
对于sigmoid函数来说,f ' 的值是一直小于 1 的。
当 W 矩阵最大特征值也小于 1 时, 随 t-k 越大,小于 1 的数不断连乘 梯度会越呈指数级衰减(vanishing gradient)。
梯度消失这一问题会导致我们无法判断 t 时刻 与 k 时刻 究竟是数据本身没有关联,还是由于梯度消失而导致我们无法捕捉到它们之间的关联。 换句话说,这也导致了我们只能学习到 附近的关系 而 无法学习到长时间依赖的关系。
梯度爆炸与梯度消息类似,当 W 矩阵的特征值大于1, 随时间越远,连乘后 该梯度将指数级增大。这会造成我们更新梯度时,一步迈的太大而越过了极值点。这会导致梯度极不稳定。
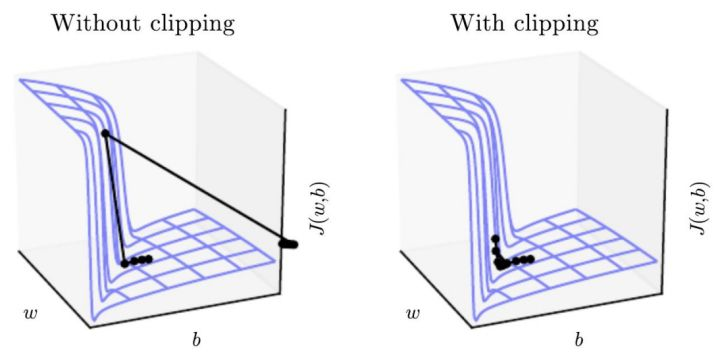
这一问题的简单解决方法是 gradient clipping。即当梯度大于某一阈值时,则在 SGD 的下一步更新时按比例缩小梯度值。即方向不变、缩小步长。
LSTM
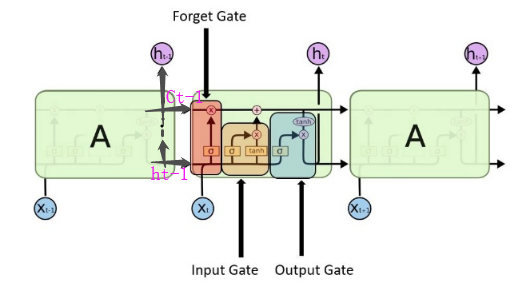
其中,ht-1 是上一轮的 output,Ct-1 是上一轮的state
每个门拆开看:
forget gate:保留哪些旧信息。ft 输出在 0 ~ 1 间。
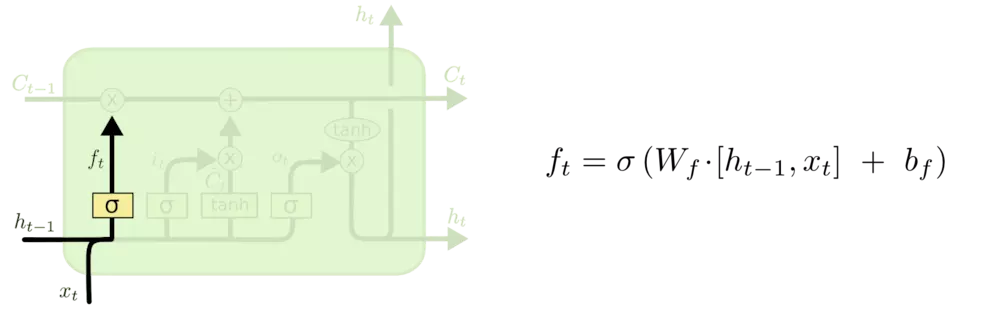
input gate:保留哪些新信息到state中
这里包含两个部分:
1)sigmoid 层 为“输入门层”, 决定什么信息将要更新,即 更新比例
2) tanh层产生新的更新候选值向量 Ct _hat,即 要更新的值
更新旧 state Ct-1 --> Ct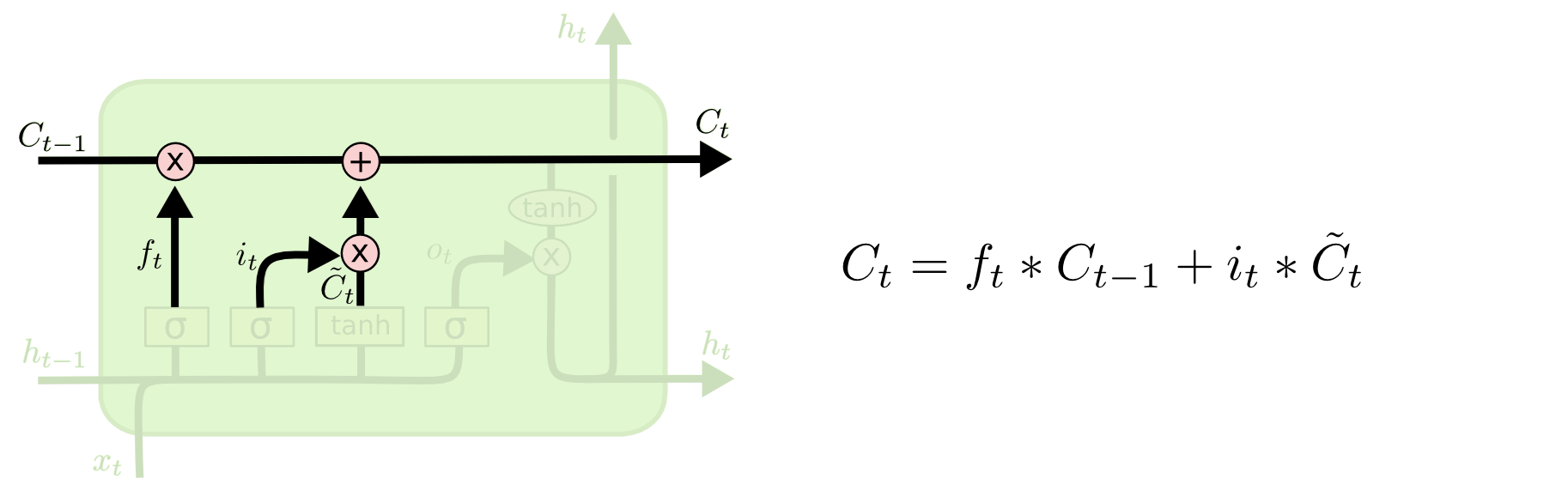
output gate:输出门决定最终输出什么值。这个值会基于 状态 Ct
先用一个sigmoid层来确定 输出比例,然后将 Ct 通过tanh处理(得到 -1 到 1 之间的值),并和sigmoid门的输出相乘,得到最终确定输出的部分。
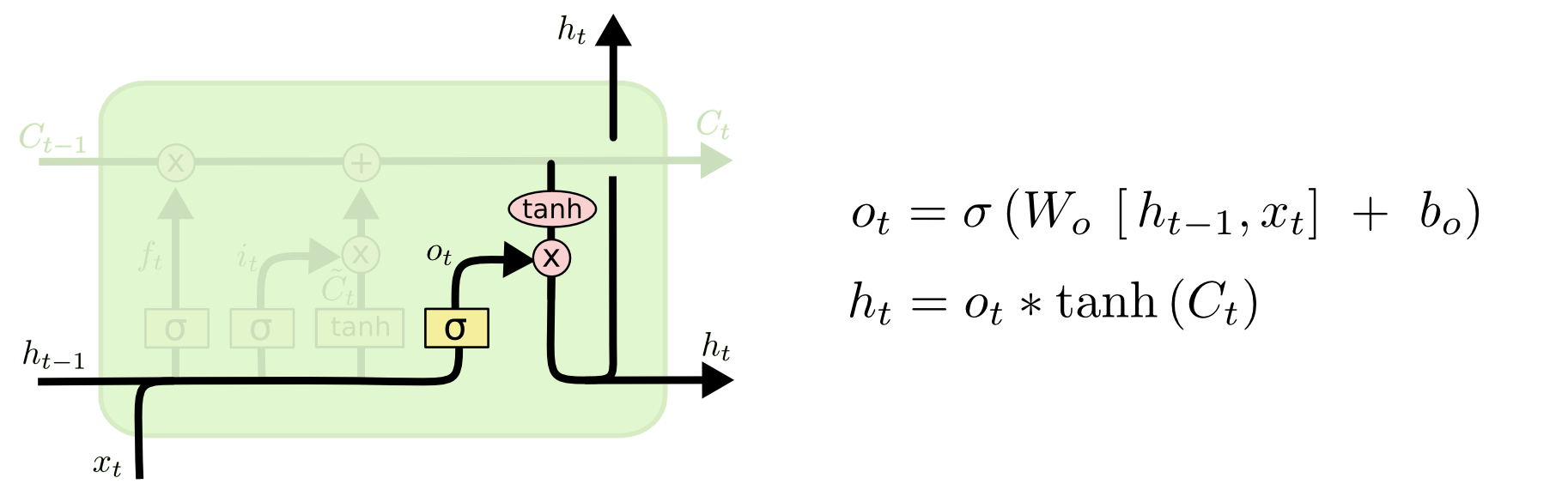
这三个门,功能上虽不同,但执行任务的操作上是相同的:都是用sigmoid函数作为比例选择工具,tanh函数作为变换工具。
LSTM为什么可以解决RNN中梯度消失的问题
因为把RNN中连乘,由forget gate转换变成了引入加号。乘法变成了加法,RNN中memory里的值总是被覆盖,而LSTM是memory和input相加,乘以一个数相加。除非forget gate被打开。
待详细补充
GRU
对LSTM的变体,将忘记门 和 输入门 合成了一个单一的 更新门。 通用还混合了 state 和 hidden state。最终模型比 LSTM 模型参数要少。

对比

参考摘录:
【1】https://zhuanlan.zhihu.com/p/30844905
【2】https://blog.csdn.net/zhaojc1995/article/details/80572098
【3】 http://www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/
【4】https://zhuanlan.zhihu.com/p/63557635