https://www.biaodianfu.com/time-series-forecasting-with-arima-in-python.html
https://www.biaodianfu.com/arima-p-d-q.html
https://blog.csdn.net/qifeidemumu/article/details/88761964?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param
基于时间序列分析的趋势预测算法,主体采用ARIMA差分自回归移动平均模型,ARIMA算法模型主体包括三大部分:AR,I以及MA模型。其中,每一个模型部分都拥有一个相关的模型参数—ARIMA(p,d,q)。算法的基本原理是将非平稳时间序列转化为平稳时间序列然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。
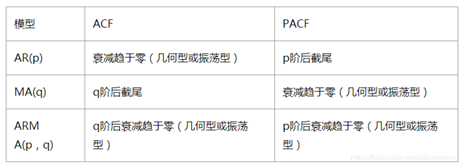
在ARIMA(p,d,q)整体模型中,AR是自回归模型,对应的模型参数p为自回归项数;I为差分模型,对应的模型参数d为使之成为平稳时间序列所做的差分次数(阶数);MA为滑动平均模型,q为滑动平均项数。在实际进行算法模型的构建时,可以根据ACF自相关系数图决定q的取值,PACF偏自相关系数图决定p的取值。
1. 自回归模型(AR)
AR模型是为了建立起当前数据特征值与过去历史值之间的关系,实现用变量自身的历史时间数据对自身进行一定的时间周期预测,自回归模型必须满足平稳性的要求,并且必须具有自相关性,自相关系数小于0.5则不适用
p阶自回归过程的公式定义:
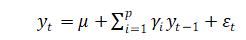
其中,为当前的值,是常数项,p是阶数,是自相关系数,是误差,前几天值的大小。
2. I差分模型
I差分模型主要是为了对原始数据进行不同书数目阶次的差分处理,使得原始数据转变为时间维度上的平稳序列,为后续建立AR和MA算法模型奠定基础。一般情况下,采用差分阶数最多的是一阶或者两阶。
3. 移动平均模型(MA)
移动平均模型关注的是自回归模型中的误差项的累加,移动平均法能有效地消除预测中的随机波动
q阶移动平均过程的公式定义:

4. ARIMA算法模型的pq参数的确定
PACF,是指偏自相关函数,剔除了中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的干扰之后x(t-k)对x(t)影响的相关程度,可以通过PACF的分布图来选择出p值的最优值大小。
ACF,自相关函数反映了同一序列在不同时序的取值之间的相关性。x(t)同时还会受到中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的影响而这k-1个随机变量又都和x(t-k)具有相关关系,所以自相关系数p(k)里实际掺杂了其他变量对x(t)与x(t-k)的影响,可以通过它的分布图来选择出最佳的模型q参数。
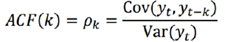
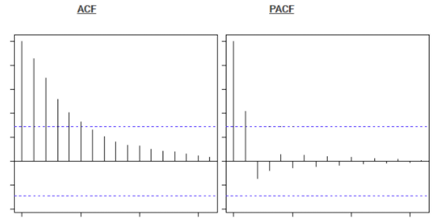
图6.1 ACF图与PACF图
综上,其具体的确定原则如下表所示:
表6-1 ARIMA模型pq参数的确定原则
5. ARIMA算法的具体步骤
① 时间序列可视化;
② 序列平稳化处理(进行d阶差分处理);
③ 绘制ACF与PACF图,寻找ARIMA模型最优p和q参数;
④ 建立ARIMA模型;
⑤ 进行指定周期时间内数据的预测。
6.算法构建与性能测试
针对过程测试PDL_AM的port1空间位置(光频为190.65)数据,选取时间区间为2020年8月1日到8月16日,构建ARIMA时间序列预测算法模型。
1.数据平稳化处理
针对原始数据,首先要进行数据的平稳化处理,经过测试,可以得到原始数据进过一阶差分之后即可实现数据的平稳化,即ARIMA模型的I部分的阶数d为1,下图分别为原始数据和原始数据经过1阶差分之后的数据趋势变化曲线:
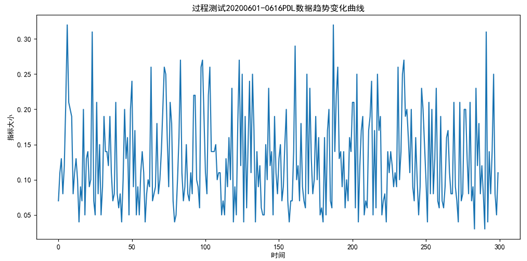
图6.2 过程测试原始数据变化趋势曲线

图6.3 过程测试原始数据一阶差分变化趋势曲线
2. 绘制一阶差分数据的自相关图和偏相关图
绘制出一阶差分处理完的PDL数据的自相关图和偏相关图,如下图所示:
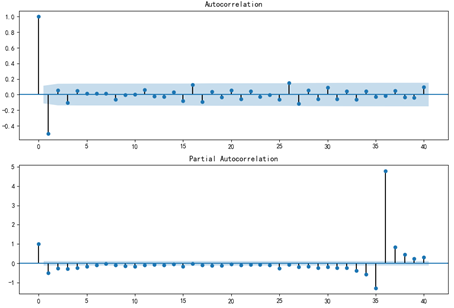
图6.4 一阶差分数据的自相关图与偏相关图
根据自相关图和偏相关图可以得到ARMA模型的最佳p和q参数分别为1和1(原因是滞后1阶之后其相关系数趋于0)
- 构建ARIMA算法模型
指定p=1,q=1,d=1,构建ARIMA时间趋势变化算法模型,并进行模型的拟合和诊断,得到以下的模型诊断输出图:

图6.5 模型诊断输出图
(1)右上角的红色KDE线和黄色N(0,1)线非常的接近,它表明残差是服从正态分布的。
(2)左下角的QQ分位图表明,从N(0,1)的标准正态分布抽取的样本,残差(蓝点)的有序分布服从线性趋势。 同样,这是一个强烈的迹象表明,残差是正态分布。
(3)随着时间的推移(左上图)残差不会显示任何明显的季节性,似乎是白噪声。这通过右下角的自相关(即相关图)证实了这一点,它表明时间序列的残差与其自身的滞后版本有很低的相关性。
4. 验证构建的模型
使用原始数据进行ARIMA算法模型的验证,将序号200-300之间的100个数据的真实值与算法模型的预测值做出来如下图所示:
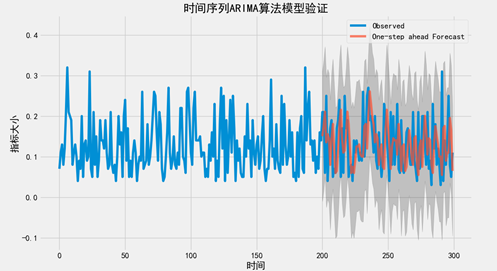
图6.6 过程测试ARIMA算法模型验证
可有得到算法模型根据前面数据的预测值与真实值的,MSE(均方差)为0.01,说明算法模型具有较好的趋势预测性能。
5. 趋势预测
使用建立起的ARIMA模型对后续三天指标值的变化进行预测,得到了未来三天2020年8月17-8月19日的21条预测结果(每天平均测试7个数据),具体变化如下所示:
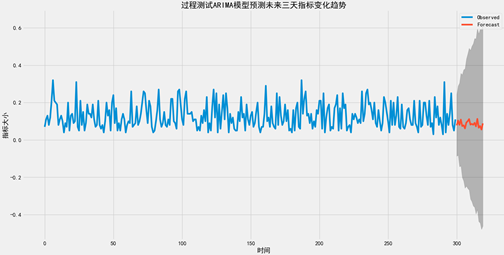
图6.7 过程测试PDL指标数据未来三天趋势预测图
源代码:
第一种算法实现:
import itertools
import pandas as pd
import matplotlib
matplotlib.use("TkAGG")
import matplotlib.pyplot as plt
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
data = sm.datasets.co2.load_pandas().data
data = data['co2'].resample('MS').mean()
data = data.fillna(data.bfill())
print(data.head())
data.plot(figsize=(12, 6))
plt.show()
print(data.shape)
plt.rcParams["font.sans-serif"]=["SimHei"]
plt.rcParams["axes.unicode_minus"]=False
data1=pd.read_excel("过程测试_033GRR10L4105623_20200601-20200708_PDL_AM_异常检测分类结果.xlsx")
i=500
newdata=data1["p1"][:300]
# newdata.index=data1["start_time"][:300]
newdata.index=range(len(newdata))
newdata.plot(figsize=(12, 6))
plt.title("过程测试20200601-0616PDL数据趋势变化曲线")
plt.xlabel("时间")
plt.ylabel("指标大小")
plt.show()
#2.下面我们先对非平稳时间序列进行时间序列的差分,找出适合的差分次数d的值:
fig = plt.figure(figsize=(12, 8))
ax1 = fig.add_subplot(111)
diff1 = newdata.diff(1)
diff1.plot(ax=ax1)
plt.title("过程测试20200601-0616PDL数据一阶差分曲线")
plt.xlabel("时间")
plt.ylabel("指标大小")
plt.show()
#这里是做了1阶差分,可以看出时间序列的均值和方差基本平稳,不过还是可以比较一下二阶差分的效果:
#这里进行二阶差分
fig = plt.figure(figsize=(12, 8))
ax2 = fig.add_subplot(111)
diff2 = newdata.diff(2)
diff2.plot(ax=ax2)
plt.title("过程测试20200601-0616PDL数据二阶差分曲线")
plt.xlabel("时间")
plt.ylabel("指标大小")
plt.show()
#由下图可以看出来一阶跟二阶的差分差别不是很大,所以可以把差分次数d设置为1,上面的一阶和二阶程序我们注释掉
plt.show()
#这里我们使用一阶差分的时间序列
# Define the p, d and q parameters to take any value between 0 and 2
p = d = q = range(0, 2)
# Generate all different combinations of p, q and q triplets
pdq = list(itertools.product(p, d, q))
print(pdq)
# Generate all different combinations of seasonal p, q and q triplets
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print(seasonal_pdq)
'''
import warnings
warnings.filterwarnings("ignore") # specify to ignore warning messages
best_results=1e10
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
model = sm.tsa.statespace.SARIMAX(newdata, order=param, seasonal_order=param_seasonal,enforce_stationarity=False, enforce_invertibility=False)
results = model.fit()
print('ARIMA{}x{} - AIC:{}'.format(param, param_seasonal, results.aic))
if best_results>results.aic:
best_results=results.aic
best_pdq=param
best_pdqs=param_seasonal
except:
continue
print("最好的参数组合为:",best_pdq,best_pdqs)
'''
model = sm.tsa.statespace.SARIMAX(newdata, order=(1,2,1), seasonal_order=(1, 1, 1, 12),enforce_stationarity=False, enforce_invertibility=False)
results = model.fit()
print(results.summary().tables[1])
results.plot_diagnostics(figsize=(12, 12))
plt.show()
pred = results.get_prediction(start=newdata.index[200], dynamic=False)
pred_ci = pred.conf_int()
ax =newdata.plot(label='Observed', figsize=(12, 6))
pred.predicted_mean.plot(ax=ax, label='One-step ahead Forecast', alpha=.7)
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('时间')
ax.set_ylabel('指标大小')
plt.title("过程测试ARIMA时间序列预测模型验证")
plt.legend()
plt.show()
#直接输出相应的MSE,比较对应函数的趋势分析
data_forecasted = pred.predicted_mean
data_truth = newdata[200:]
print(data_forecasted,len(data_forecasted))
print(data_truth,len(data_truth))
plt.plot(range(len(data_forecasted)-1),data_forecasted[1:],"r")
plt.plot(range(len(data_truth)),data_truth,"b")
plt.show()
# Compute the mean square error
mse = ((data_forecasted - data_truth) ** 2).mean()
print('The Mean Squared Error of our forecasts is {}'.format(round(mse, 2)))
'''
#使用动态预测的方法进行数据的预测与变化
pred_dynamic = results.get_prediction(start=pd.to_datetime(newdata.index[450]), dynamic=True, full_results=True)
pred_dynamic_ci = pred_dynamic.conf_int()
ax = newdata.plot(label='Observed', figsize=(12, 6))
pred_dynamic.predicted_mean.plot(label='Dynamic Forecast', ax=ax)
ax.fill_between(pred_dynamic_ci.index,
pred_dynamic_ci.iloc[:, 0],
pred_dynamic_ci.iloc[:, 1], color='k', alpha=.25)
ax.fill_betweenx(ax.get_ylim(),pd.to_datetime(newdata.index[450]), newdata.index[-1],
alpha=.1, zorder=-1)
ax.set_xlabel('Date')
ax.set_ylabel('CO2 Levels')
plt.legend()
plt.show()
data_forecasted = pred_dynamic.predicted_mean
data_truth = newdata[450:]
print(data_forecasted,len(data_forecasted))
print(data_truth,len(data_truth))
# Compute the mean square error
mse = ((data_forecasted - data_truth) ** 2).mean()
print('The Mean Squared Error of our forecasts is {}'.format(round(mse, 2)))
plt.plot(range(len(data_forecasted)),data_forecasted,"r")
plt.plot(range(len(data_truth)),data_truth,"b")
plt.show()
'''
# Get forecast 500 steps ahead in future
# model = sm.tsa.statespace.SARIMAX(newdata, order=(1,2,1), seasonal_order=(1,1,1,12), enforce_stationarity=False, enforce_invertibility=False)
#results = model.fit()
pred_uc = results.get_forecast(steps=20)
print(pred_uc.predicted_mean)
# Get confidence intervals of forecasts
pred_ci = pred_uc.conf_int()
plt.figure()
plt.plot(newdata)
plt.plot(pred_uc.predicted_mean)
plt.show()
ax = newdata.plot(label='Observed', figsize=(12, 6))
#plt.show()
pred_uc.predicted_mean.plot(ax=ax,label='Forecast')
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.25)
ax.set_xlabel('时间')
ax.set_ylabel('指标大小')
plt.title("过程测试ARIMA模型预测未来三天指标变化趋势")
plt.legend()
plt.show()
第二种算法实现:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.tsa.arima_model import ARMA
from statsmodels.graphics.tsaplots import acf,pacf,plot_acf,plot_pacf
from statsmodels.graphics.api import qqplot
plt.rcParams["font.sans-serif"]=["SimHei"]
plt.rcParams["axes.unicode_minus"]=False
# 1.创建数据
data = [5922, 5308, 5546, 5975, 2704, 1767, 4111, 5542, 4726, 5866, 6183, 3199, 1471, 1325, 6618, 6644, 5337, 7064, 2912, 1456, 4705, 4579, 4990, 4331, 4481, 1813, 1258, 4383, 5451, 5169, 5362, 6259, 3743, 2268, 5397, 5821, 6115, 6631, 6474, 4134, 2728, 5753, 7130, 7860, 6991, 7499, 5301, 2808, 6755, 6658, 7644, 6472, 8680, 6366, 5252, 8223, 8181, 10548, 11823, 14640, 9873, 6613, 14415, 13204, 14982, 9690, 10693, 8276, 4519, 7865, 8137, 10022, 7646, 8749, 5246, 4736, 9705, 7501, 9587, 10078, 9732, 6986, 4385, 8451, 9815, 10894, 10287, 9666, 6072, 5418]
data = pd.Series(data)
data.index = pd.Index(sm.tsa.datetools.dates_from_range('1901','1990'))
data.plot(figsize=(12,8))
plt.show()
#
# data1=pd.read_excel("过程测试_033GRR10L4105623_20200601-20200708_PDL_AM_异常检测分类结果.xlsx")
# i=500
# data=data1["p1"][:300]
# data.index=range(len(data))
# #data.index = pd.Index(sm.tsa.datetools.dates_from_range('1691','1990'))
# data.plot(figsize=(12, 6))
# plt.title("过程测试20200601-0616PDL数据趋势变化曲线")
# plt.xlabel("时间")
# plt.ylabel("指标大小")
# plt.show()
#2.下面我们先对非平稳时间序列进行时间序列的差分,找出适合的差分次数d的值:
fig = plt.figure(figsize=(12, 8))
ax1 = fig.add_subplot(111)
diff1 = data.diff(1)
diff1.plot(ax=ax1)
plt.title("过程测试20200601-0616PDL数据一阶差分曲线")
plt.xlabel("时间")
plt.ylabel("指标大小")
#这里是做了1阶差分,可以看出时间序列的均值和方差基本平稳,不过还是可以比较一下二阶差分的效果:
#这里进行二阶差分
fig = plt.figure(figsize=(12, 8))
ax2 = fig.add_subplot(111)
diff2 = data.diff(2)
diff2.plot(ax=ax2)
#由下图可以看出来一阶跟二阶的差分差别不是很大,所以可以把差分次数d设置为1,上面的一阶和二阶程序我们注释掉
plt.show()
#这里我们使用一阶差分的时间序列
data = data.diff(1)
data.dropna(inplace=True)
#加上这一步,不然后面画出的acf和pacf图会是一条直线
#第一步:先检查平稳序列的自相关图和偏自相关图
fig = plt.figure(figsize=(12, 8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(data,lags=40,ax=ax1)
#lags 表示滞后的阶数
#第二步:下面分别得到acf 图和pacf 图
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(data, lags=40,ax=ax2)
plt.show()
#由上图可知,我们可以分别用ARMA(0,1)模型、ARMA(7,0)模型、ARMA(7,1)模型等来拟合找出最佳模型:
#第三步:找出最佳模型ARMA
arma_mod1 = sm.tsa.ARMA(data,(7,0)).fit()
print(arma_mod1.aic, arma_mod1.bic, arma_mod1.hqic)
# arma_mod2 = sm.tsa.ARMA(data,(0,1)).fit()
# print(arma_mod2.aic, arma_mod2.bic, arma_mod2.hqic)
# arma_mod3 = sm.tsa.ARMA(data,(7,1)).fit()
# print(arma_mod3.aic, arma_mod3.bic, arma_mod3.hqic)
# arma_mod4 = sm.tsa.ARMA(data,(8,0)).fit()
# print(arma_mod4.aic, arma_mod4.bic, arma_mod4.hqic)
#由上面可以看出ARMA(7,0)模型最佳
#由上面可以看出ARMA(7,0)模型最佳
#第四步:进行模型检验
#首先对ARMA(7,0)模型所产生的残差做自相关图
resid = arma_mod1.resid
#一定要加上这个变量赋值语句,不然会报错resid is not defined
fig = plt.figure(figsize=(12, 8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(resid.values.squeeze(),lags=40,ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(resid, lags=40,ax=ax2)
plt.show()
#接着做德宾-沃森(D-W)检验
print(sm.stats.durbin_watson(arma_mod1.resid.values))
#得出来结果是不存在自相关性的
#再观察是否符合正态分布,这里用qq图
fig = plt.figure(figsize=(12,8))
ax = fig.add_subplot(111)
fig = qqplot(resid, line='q',ax=ax, fit=True)
plt.show()
# #最后用Ljung-Box检验:检验的结果就是看最后一列前十二行的检验概率(一般观察滞后1~12阶),
# #如果检验概率小于给定的显著性水平,比如0.05、0.10等就拒绝原假设,其原假设是相关系数为零。
# #就结果来看,如果取显著性水平为0.05,那么相关系数与零没有显著差异,即为白噪声序列。
r,q,p = sm.tsa.acf(resid.values.squeeze(),qstat=True)
data1 = np.c_[range(1,41), r[1:], q, p]
table= pd.DataFrame(data1, columns=[ 'lag','AC','Q','Prob(>Q)'])
print(table.set_index('lag'))
#第五步:模型预测,对未来十年进行预测
predict_y =arma_mod1.predict('1990', '2000', dynamic=True)
#print(predict_y)
fig, ax = plt.subplots(figsize=(12,8))
ax = data['1901':].plot(ax=ax)
predict_y.plot(ax=ax)
plt.show()