//2019.08.04
#线性回归算法基础入门(Linear Regression)
1、线性回归算法是一种非常典型的解决回归问题的监督学习算法,它具有以下几个特点:
(1)典型的回归算法,可以解决实际中的回归问题;
(2)思想简单,容易实现;
(3)是许多强大的非线性算法模型的基础;
(4)结果具有很好的可解释性;
(5)蕴含机器学习中的很多重要思想。
2、线性回归问题与分类问题的区别在于其标记结果的连续性和离散性,另外在数据点的图像分布上,分类问题的坐标轴都是样本数据的特征,而线性回归问题一定存在一个坐标轴是数据的标记(即结果值)
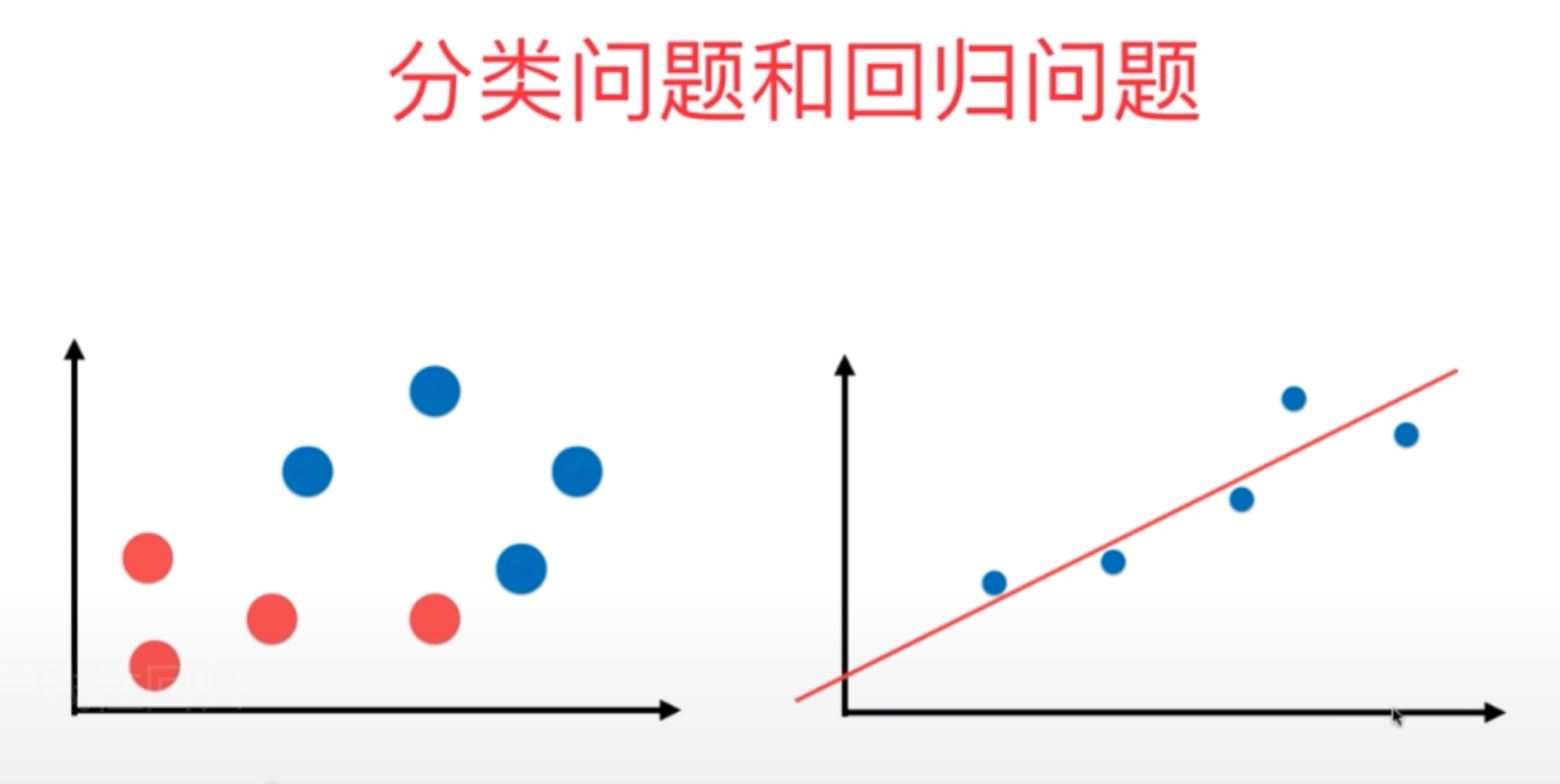
图1
3、简单线性回归问题:是指样本数据的特征只有一个时,其线性回归问题就成为简单线性回归问题。
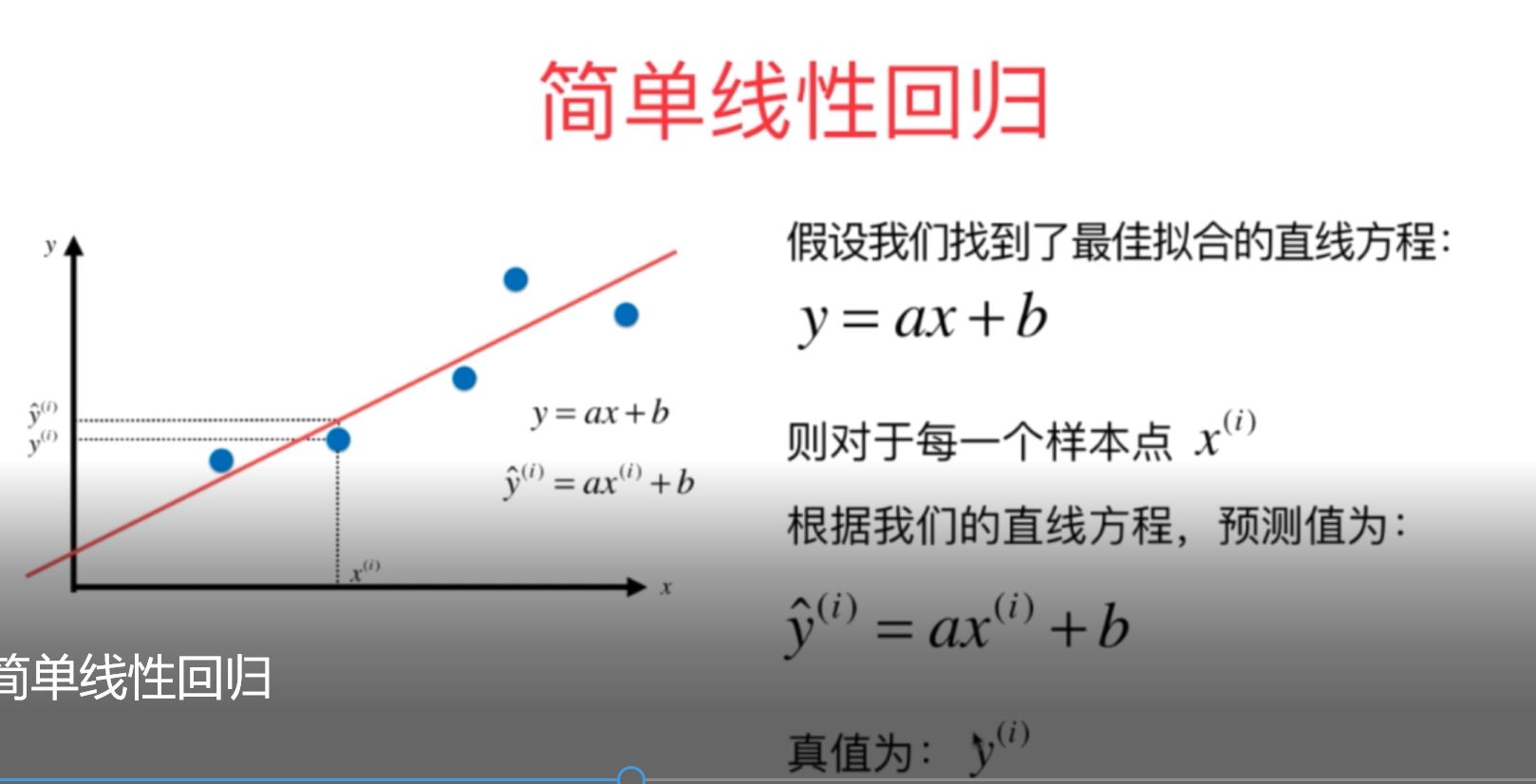
图2
4、对于近乎所有的含参数的机器学习回归算法,其具体的数学解决思路就是:通过分析具体的问题,确定问题中的损失函数或者效用函数;然后通过数学的解决思路,最优化损失函数或者效用函数,从而确定模型中所需要的各个参数大小,最终获得机器学习的模型。而在整体的这个问题解决中,最优化与凸优化原理均起着非常关键的作用。

图3
5、对于简单线性回归问题,即数据特征只有一个的基础数据集,要使得损失函数(这里是指真值与预测值之间误差的平方)最小,从而求得最优化的参数a和b,这个具体方法称为最小二乘法,利用最小二乘法,可以得到最佳的参数a和b的计算式,如下所示:

图4
6、在简单线性回归中,对于模型参数a和b的求取最后需要尽可能地化简为向量化之间的运算,向量化运算可以大幅度地降低整体运算的计算量,提高整体的运算效率。
向量化运算是机器学习算法中非常重要的思想,它是提高机器学习算法计算效率的非常有效的方法。

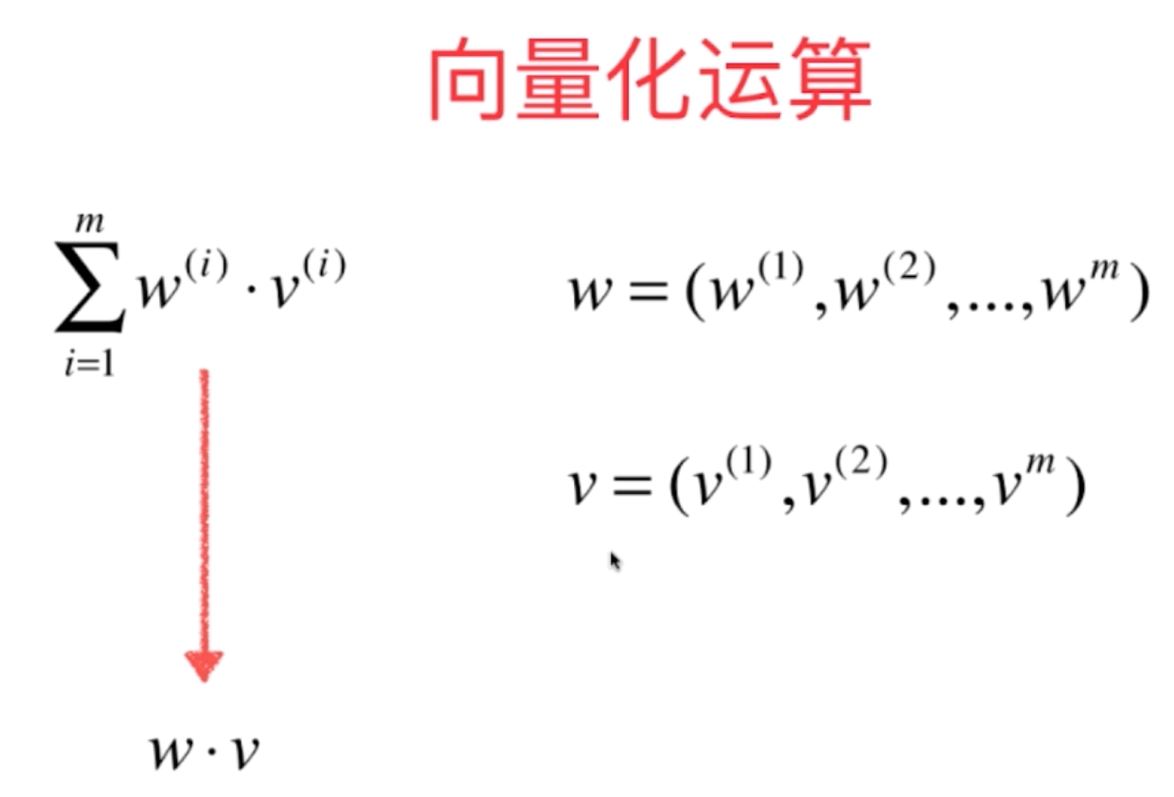 图5
图5
7、对于线性回归算法的评判标准主要有以下指标:
(1)MSE:均方误差

(2)RMSE:均方根误差

(3)MAE:平均绝对误差

图6
8、在scikitlearn中调用回归问题的三大指标的方法:
#利用sklearn里面的merics模块导出三大函数,直接进行调用计算
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
print(mean_squared_error(y_test,y_predict))
print(mean_absolute_error(y_test,y_predict))
9、对于不同的评价指标RMSE和MAE两者,它们都与原始数据的y的量纲是相同的,所以也常用来作为不同训练模型的评价指标。
对于这两个指标,由它们的表达式可知,RMSE中存在平方操作,将平方累加后再开方,这样的操作具有放大样本中较大误差的趋势,因此使得RMSE最小更加有意义,因为这样意味着样本中所存在的最大的误差值最小,而MAE主要是所有误差的平均值。
另外,对于我们训练优化的目标函数与RMSE中的函数组成一致,这样有利于使得测试数据中的目标函数值具有变小的趋势。综上所述,我们对于不同的训练模型应该尽可能使会更有意义。

图7
10、对于线性回归,其最好的评价指标是R2,并且sklearn中最终输出的准确度score(),其实际输出也就是所谓的R2,其计算方式如下:

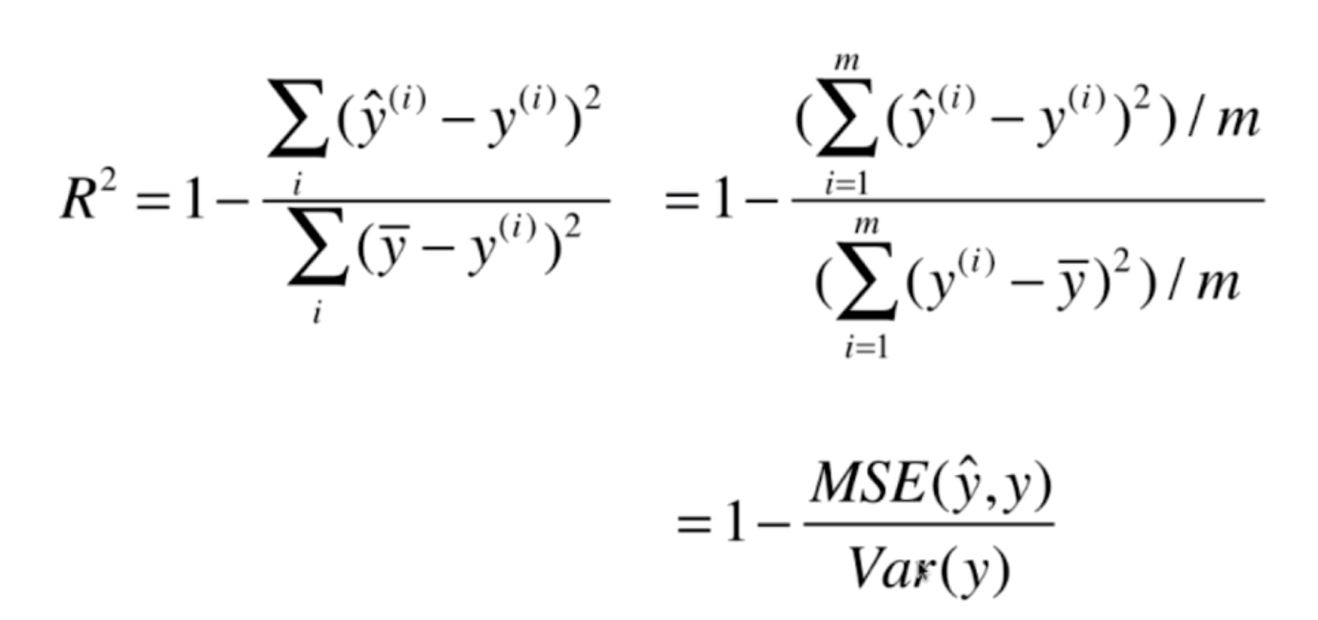
图8
根据R2的计算方式,可以知道不同的线性回归模型的准确度也可以将R2归类到0-1之间,并且随着R2增大,其训练模型的准确度也越来越高。

在sklearn中也可以直接进行调用输出上面的四个回归问题的评价指标MSE,RMSE,MAE以及R2,其实现代码如下:
#利用sklearn里面的merics模块导出三大函数,直接进行调用计算
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score #直接调用库函数进行输出R2
print(mean_squared_error(y_test,y_predict))
print(mean_absolute_error(y_test,y_predict))
print(r2_score(y_test,y_predict))
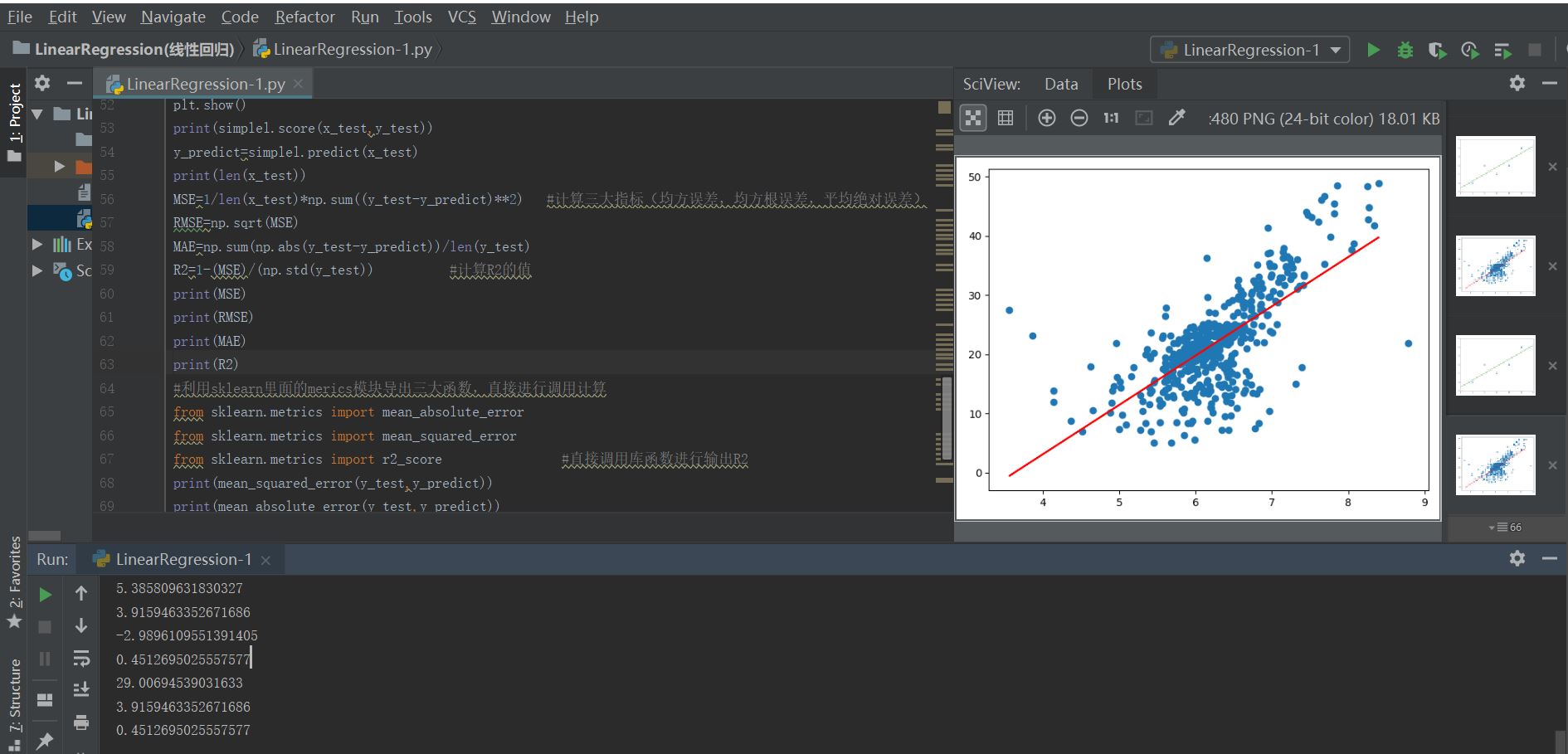
实现结果如下: