数据可视化
- 什么是数据可视化
- Matplotlib的用法
- 金融学图表
- 保存图表
1、什么是数据可视化
数据可视化在量化分析当中是一个非常关键的辅助工具,往往我们需要通过可视化技术,对我们的数据进行更清晰的展示,这样也能帮助我们理解交易、理解数据。通过数据的可视化也可以更快速的发现量化投资中的一些问题,更有利于分析并解决它们。接下来我们主要使用的可视化工具包叫做——Matplotlib,它是一个强大的Python绘图和数据可视化的工具包。
2、Matplotlib的用法
2.1、一维数据集
安装方式:
pip install matplotlib
引用方法:
import matplotlib.pyplot as plt
在matplotlib库当中,整个图像为一个figure对象,在figure对象中可以包含一个或者多个axes,每个axes(ax)对象都是一个拥有自己坐标系统的绘图区域。

plt.plot() # 绘图函数
plt.show() # 显示图像
在jupyter notebook中不执行这条语句也是可以将图形展示出来
import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
np.random.seed(1000)
y = np.random.standard_normal(20) # 生成正态分布的随机数
x = range(len(y))
plt.plot(x,y)
执行结果:
plot函数会注意我们传递进来的ndarray对象,在这种情况下,就不需要提供X参数了,如果只提供Y值,plot就会以索引作为对应的X值。最终的输出会和上面是一样的。
plt.plot(y)
运行结果:
通过刚才的演示可以发现,我们可以简单的向matplotlib函数传递Numpy ndarray对象,函数是能够解释数据结构以简化绘图工作,但是要注意,不要传递太大或者太过复杂的数组。
2.1.1、plot函数
一般来说,默认绘图样式肯定是不能满足报表、出版等一系列典型要求的,所以说我们就需要想办法修改图像的样式,因此在plot函数当中就有着大量的自定义样式的方法。
绘制折线图
- 线型linestyle(-,-.,--,..)
- 点型marker(v,^,s,*,H,+,X,D,O,...)
- 颜色color(b,g,r,y,k,w,...)
plt.plot([0,3,9,15,30],linestyle = '-.',color = 'r',marker = 'o')

图像标注
| 方法 | 描述 |
|---|---|
| plt.title() | 设置图像标题 |
| plt.xlabel() | 设置x轴名称 |
| plt.ylabel() | 设置y轴名称 |
| plt.xlim() | 设置x轴范围 |
| plt.ylim() | 设置y轴范围 |
| plt.xticks() | 设置x轴刻度 |
| plt.yticks() | 设置y轴刻度 |
| plt.legend() | 设置曲线图例 |
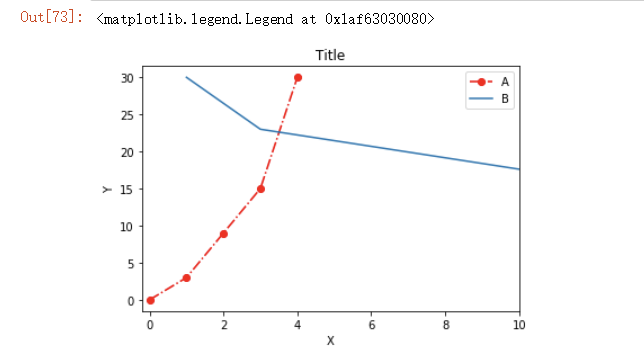
plt.plot([0,3,9,15,30],linestyle = '-.',color = 'r',marker = 'o',label="A")
plt.plot([1,3,16,23,30],[30,23,13,25,30],label='B')
plt.title("Title") # 标题
plt.xlabel('X') # x轴名称
plt.ylabel('Y') # y轴名称
plt.xticks(np.arange(0,30,2)) # x轴刻度
plt.xlim(-0.2,10,2) # x轴范围
plt.legend() # 曲线图例
运行图例:
axis函数
plt.plot(y.cumsum())
plt.grid(True)
plt.axis('image')
运行结果:
 接下来主要介绍axis函数的一些参数:
接下来主要介绍axis函数的一些参数:
| 参数 | 描述 |
|---|---|
| Empty | 返回当前坐标轴限值 |
| off | 关闭坐标轴线和标签 |
| equal | 使用等刻度 |
| scaled | 通过尺寸变化平衡刻度 |
| tight | 使所有数据可见(缩小限值) |
| image | 使所有数据可见(使用数据限值) |
| [xmin,xmax,ymin,ymax] | 将设置限制为给定的(一组)值 |
2.2、二维数据集
一维数据绘图只能说是一种特例,一般来说,数据集包含多个单独的子集。这些数据的处理也是同样遵循matplotlib处理一维数据时的原则。但是,这种情况会出现一些其他的问题,例如,两个数据集它们可能会有不同的刻度,无法用相同的y或者x轴刻度进行绘制,还有可能希望以不同的方式可视化两组不同的数据,例如,一组数据使用线图,另一组使用柱状图。
接下来,首先生成一个二维样本数据。
np.random.seed(2000)
y = np.random.standard_normal((20,2)).cumsum(axis=0)
以上代码生成的是一个包含标准正态分布随机数的20*2的ndarray数组,如下:
array([[ 1.73673761, 1.89791391],
[-0.37003581, 1.74900181],
[ 0.21302575, -0.51023122],
[ 0.35026529, -1.21144444],
[-0.27051479, -1.6910642 ],
[ 0.93922398, -2.76624806],
[ 1.74614319, -3.05703153],
[ 1.52519555, -3.22618757],
[ 2.62602999, -3.14367705],
[ 2.6216544 , -4.8662353 ],
[ 3.67921082, -7.38414811],
[ 1.7685707 , -6.07769276],
[ 2.19296834, -6.54686084],
[ 1.18689581, -7.46878388],
[ 1.81330034, -7.11160718],
[ 1.79458178, -6.89043591],
[ 2.49318589, -6.05592589],
[ 0.82754806, -8.95736573],
[ 0.77890953, -9.00274406],
[ 2.25424343, -9.51643749]])
将这样的二维数组传递给plot函数,他将自动把包含的数据解释为单独的数据集。
plt.figure(figsize=(7,4))
plt.plot(y,lw=1.5)
plt.plot(y,"rd")
plt.axis('tight')
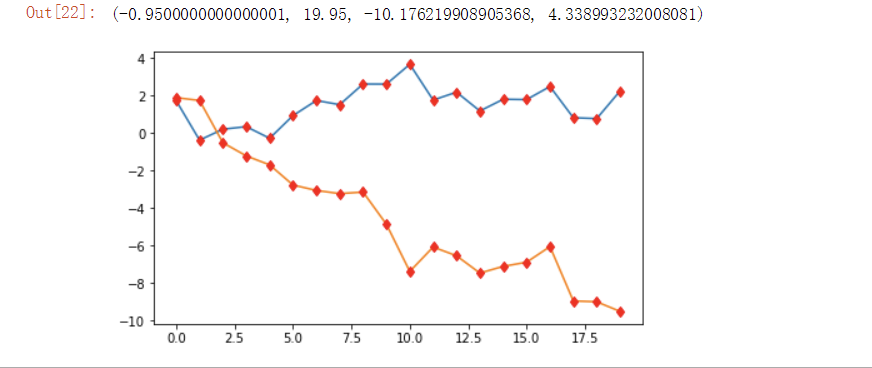
像这种数据肯定就是看的一头乱麻,所以说我们需要将它进一步做一下注释,为了让我们能更好的理解图表。
plt.figure(figsize=(7,4))
# 分别为两条数据添加图例
plt.plot(y[:,0],lw=1.5,label='1st')
plt.plot(y[:,1],lw=1.5,label='2nd')
plt.plot(y,"rd")
plt.grid(True) # 网格设置
plt.legend(loc=0) # 图例标签位置设置
plt.axis('tight')
plt.xlabel('index')
plt.ylabel('value')
plt.title('test1')
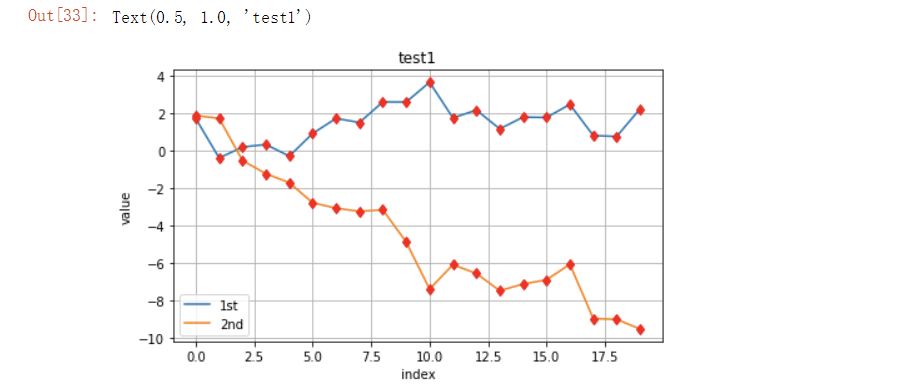
通过刚才的操作我们也能够发现,虽然我们传进的是一个ndarray数组,但是它是一个二维数组,所以我们要想将数据全部展示出来就可以使用上面那种方式,但是上面的数据刻度都是相差无几的,如果说某一维的数据非常大,而另外一维的则都是一些小数据,那要怎么办呢。
首先先来看看会造成什么样的结果:
y[:,0] = y[:,0] * 100
plt.figure(figsize=(7,4))
plt.plot(y[:,0],lw=1.5,label='1st')
plt.plot(y[:,1],lw=1.5,label='2nd')
plt.plot(y,"rd")
plt.grid(True) # 网格设置
plt.legend(loc=0) # 图例标签位置设置
plt.axis("tight")
plt.xlabel('index')
plt.ylabel('value')
plt.title("test2")
运行结果:
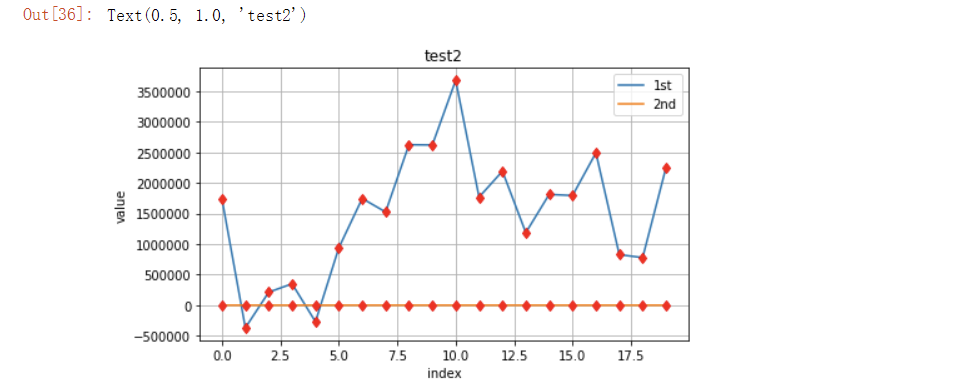
第一个数据由于数据量大,所以在这么大的刻度上依然可以将数据显示比较好辨认,而第二个数据就会因为这个原因看起来像一条直线,我们已经不能通过图像观察它的数据效果。
处理方式:
- 使用两个y轴(一左一右)
- 使用两个子图
首先先来看第一种方法:
fig,ax1 = plt.subplots()
# 第一组数据
plt.plot(y[:,0],lw=1.5,label='1st')
plt.plot(y[:,0],"rd")
plt.grid(True) # 网格设置
plt.legend(loc=8) # 图例标签位置设置
plt.axis("tight")
plt.xlabel('index')
plt.ylabel('value 1st')
# 第二组数据
ax2 = ax1.twinx()
plt.plot(y[:,1],'g',lw=1.5,label='2nd')
plt.plot(y[:,1],'bd')
plt.legend(loc=0)
plt.ylabel("value 2nd")
plt.title("test3")
运行结果:
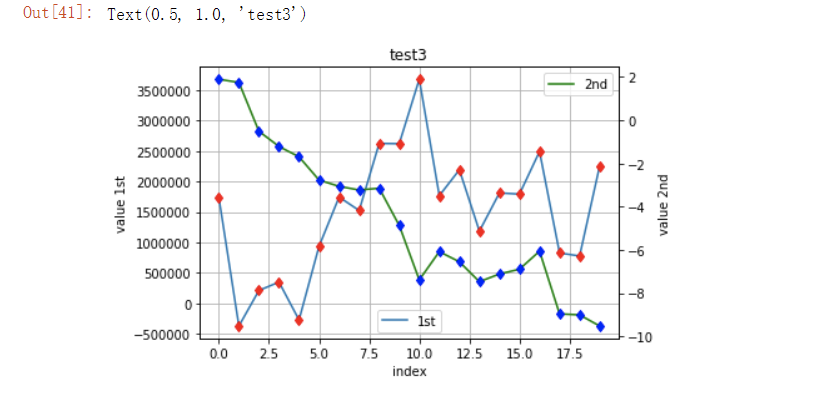
这是通过在一张图上通过不同的刻度来展示不同的数据。
第二种方式:
plt.figure(figsize=(7,5))
plt.subplot(211) # 指定子图位置,三个参数:行数、列数、子图编号
plt.plot(y[:,0],lw=1.5,label='1st')
plt.plot(y[:,0],"rd")
plt.grid(True) # 网格设置
plt.legend(loc=0) # 图例标签位置设置
plt.axis("tight")
plt.ylabel('value')
plt.title("test4")
plt.subplot(212)
plt.plot(y[:,1],'g',lw=1.5,label='2nd')
plt.plot(y[:,1],'rd')
plt.grid(True) # 网格设置
plt.legend(loc=0) # 图例标签位置设置
plt.axis("tight")
plt.xlabel('index')
plt.ylabel('value')
运行结果:

以上操作都是通过折线图来实现的,但是在matplotlib当中还支持很多种类型的图像。
2.3、plt对象支持的图类型
| 函数 | 说明 |
|---|---|
| plt.plot(x,y,fmt) | 坐标系 |
| plt.boxplot(data,notch,position) | 箱型图 |
| plt.bar(left,height,width,bottom) | 柱状图 |
| plt.barh(width,bottom,left,height) | 横向柱状图 |
| plt.polar(theta,r) | 极坐标系 |
| plt.pie(data,explode) | 饼图 |
| plt.psd(x,NFFT=256,pad_to,Fs) | 功率谱密度图 |
| plt.specgram(x,NFFT=256,pad_to,F) | 谱图 |
| plt.cohere(x,y,NFFT=256,Fs) | X-Y相关性函数 |
| plt.scatter(x,y) | 散点图 |
| plt.step(x,y,where) | 步阶图 |
| plt.hist(x,bins,normed) | 直方图 |
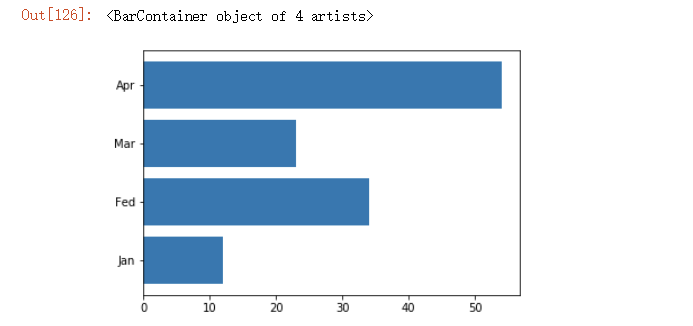
2.3.1、柱状图
# 柱状图
data = [12,34,23,54]
labels = ['Jan','Fed','Mar','Apr']
plt.xticks([0,1,2,3],labels) # 设置x轴刻度
plt.bar([0,1,2,3],data)
# 横向柱状图
data = [12,34,23,54]
labels = ['Jan','Fed','Mar','Apr']
plt.yticks([0,1,2,3],labels)
plt.barh([0,1,2,3],data)
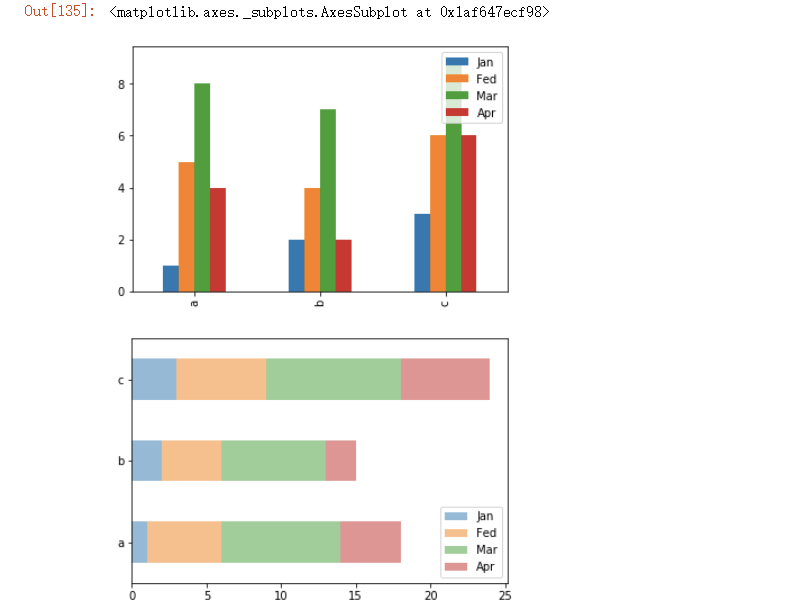
# DataFrame数组图
df = pd.DataFrame({
'Jan':pd.Series([1,2,3],index=['a','b','c']),
'Fed':pd.Series([4,5,6],index=['b','a','c']),
'Mar':pd.Series([7,8,9],index=['b','a','c']),
'Apr':pd.Series([2,4,6],index=['b','a','c'])
})
df.plot.bar() # 水平柱状图,将每一行中的值分组到并排的柱子中的一组
df.plot.barh(stacked=True,alpha=0.5) # 横向柱状图,将每一行的值堆积到一起
2.3.2、饼图
# 饼图
plt.pie([10,20,30,40],labels=list('abcd'),autopct="%.2f%%",explode=[0.1,0,0,0]) # 饼图
plt.axis("equal")
plt.show()

2.3.3、散点图
对于二维绘图,线图和点图可能是金融学中的最重要的,刚才在上面线图已经有过简单接触,接下来主要介绍的就是点图了,这种图表类型可用于绘制一个金融时间序列的收益和另一个时间序列收益的对比。
y = np.random.standard_normal((1000,2)) # 生成正态分布的二维随机数组
c = np.random.randint(0,10,len(y))
plt.figure(figsize=(7,5))
plt.scatter(y[:,0],y[:,1],c=c,marker='o') # 通过scatter函数加入第三维数据
plt.colorbar() # 通过彩条对不用演示数据进行描述
plt.grid(True)
plt.xlabel('1st')
plt.ylabel('2nd')
plt.title("test5")
运行结果:
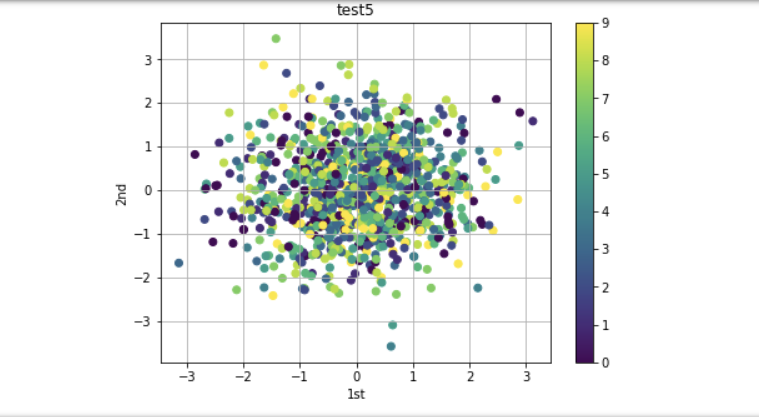
2.3.4、直方图
plt.figure(figsize=(7,4))
plt.hist(y,label=['1st','2nd'],bins=25)
plt.grid(True) # 网格设置
plt.legend(loc=0) # 图例标签位置设置
plt.axis("tight")
plt.xlabel('index')
plt.ylabel('frequency')
plt.title("test6")
运行结果:

直方图是金融应用当中比较常用的图表类型,接下来主要介绍一下plt.hist的使用方法以及它的参数说明
plt.hist(
['x', 'bins=None', 'range=None', 'density=None', 'weights=None', 'cumulative=False', 'bottom=None', "histtype='bar'", "align='mid'", "orientation='vertical'", 'rwidth=None', 'log=False', 'color=None', 'label=None', 'stacked=False', 'normed=None', '*', 'data=None', '**kwargs'],
)
| 参数 | 描述 |
|---|---|
| x | 列表对象,ndarray对象 |
| bins | 数据组(bin)数 |
| range | 数据组的上界和下界 |
| normed | 规范化为整数1 |
| weights | x轴上每个值的权重 |
| cumulative | 每个数据组包含较低组别的计数 |
| histtype | 选项:bar,barstacked,step,stepfilled |
| align | 选项:left,mid,right |
| orientation | 选项:horizontal,vertical |
| rwidth | 条块的相对宽度 |
| log | 对数刻度 |
| color | 每个数据集的颜色 |
| label | 标签所用的字符串或者字符串序列 |
| stacked | 堆叠多个数据集 |
2.3.5、箱型图
箱型图可以简洁地概述数据集的特性,可以很容易的比较多个数据集。
fig,ax = plt.subplots(figsize=(7,4))
plt.boxplot(y)
plt.grid(True)
plt.setp(ax,xticklabels=['1st','2nd'])
plt.xlabel('data set')
plt.ylabel("value")
plt.title("test7")
运行结果:

2.3.6、补充:绘制数学函数
以图形的方式说明某个下限和上限之间函数图像下方区域的面积,简而言之就是,从下限到上限之间函数积分值
# 第一步:定义求取积分的函数
def func(x):
return 0.5 * np.exp(x) + 1 # 指数函数
# 第二步:定义积分区间,生成必须得数值
a, b = 0.5 , 1.5
x = np.linspace(0,2)
y = func(x)
# 第三步:绘制函数图像
fig, ax = plt.subplots(figsize=(7,5))
plt.plot(x,y,'b',linewidth=2)
plt.ylim(ymin=0)
# 第四步:使用Polygon函数生成阴影部分,表示积分面积
Ix = np.linspace(a, b)
Iy = func(Ix)
verts = [(a,0)] + list(zip(Ix, Iy)) + [(b, 0)]
poly = plt.Polygon(verts,facecolor='0.7',edgecolor='0.5')
ax.add_patch(poly)
# 第五步:使用plt.text和plt.figtext在图表上添加数学公式和一些坐标轴标签
plt.text(0.5 * (a + b),1,r"$int_a^b f(x)mathrm{d}x$",horizontalalignment='center',fontsize=20)
plt.figtext(0.9, 0.075, "$x$")
plt.figtext(0.075,0.9,"$f(x)$")
# 第六步:设置刻度标签以及添加网格
ax.set_xticks((a, b))
ax.set_xticklabels(('$a$', '$b$'))
ax.set_yticks([func(a), func(b)])
ax.set_yticklabels(('$f(a)$', '$f(b)$'))
plt.grid(True)
运行结果:

3、金融学图表
3.1、烛柱图
以上绘制出来的数据都是一些常用的数据图像,但是在金融行业会有一些独有的图像,之前在matplotlib当中还提供了少量的特殊金融图表,这些图表,就例如烛柱图,主要是用于可视化历史股价数据或者类似的金融时间序列。
现在这个方法已经独立出来自成一个模块了*mpl_finance*
anaconda中mpl_finance安装方式:
将https://github.com/matplotlib/mpl_finance/archive/master.zip下载到本地
在anaconda环境中运行命令:pip install 本地路径/mpl_finance-master.zip
调用方式:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import mpl_finance as mpf
import tushare as ts
import pandas as pd
from matplotlib.pylab import date2num
from dateutil.parser import parse
import numpy as np
import matplotlib.dates as mdate
data = ts.get_k_data('000001') # 获取平安的k线数据
data_of = data[:60] # 只取前60份数据
fig, ax = plt.subplots(figsize=(15, 7))
__colorup__ = "r"
__colordown__ = "g"
# 图表显示中文
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
qutotes = []
for index, (d, o, c, h, l) in enumerate(
zip(data_of.date, data_of.open, data_of.close,
data_of.high, data_of.low)):
# 时间需要通过date2num转换为浮点型
d = date2num(parse(d))
# 日期,开盘,收盘,最高,最低组成tuple对象val
val = (d, o, c, h, l)
# 加val加入qutotes
qutotes.append(val)
# 使用mpf.candlestick_ochl进行蜡烛绘制,ochl代表:open,close,high,low
mpf.candlestick_ochl(ax, qutotes, width=0.8, colorup=__colorup__,colordown=__colordown__)
#设置x轴为时间格式,否则x轴显示的将是类似于‘736268’这样的转码后的数字格式
ax.xaxis.set_major_formatter(mdate.DateFormatter('%Y-%m-%d'))
plt.xticks(pd.date_range('2016-08-01','2016-11-30',freq='W'),rotation=60)
plt.grid(True) # 网格设置
plt.title("k线图")
ax.autoscale_view()
ax.xaxis_date()
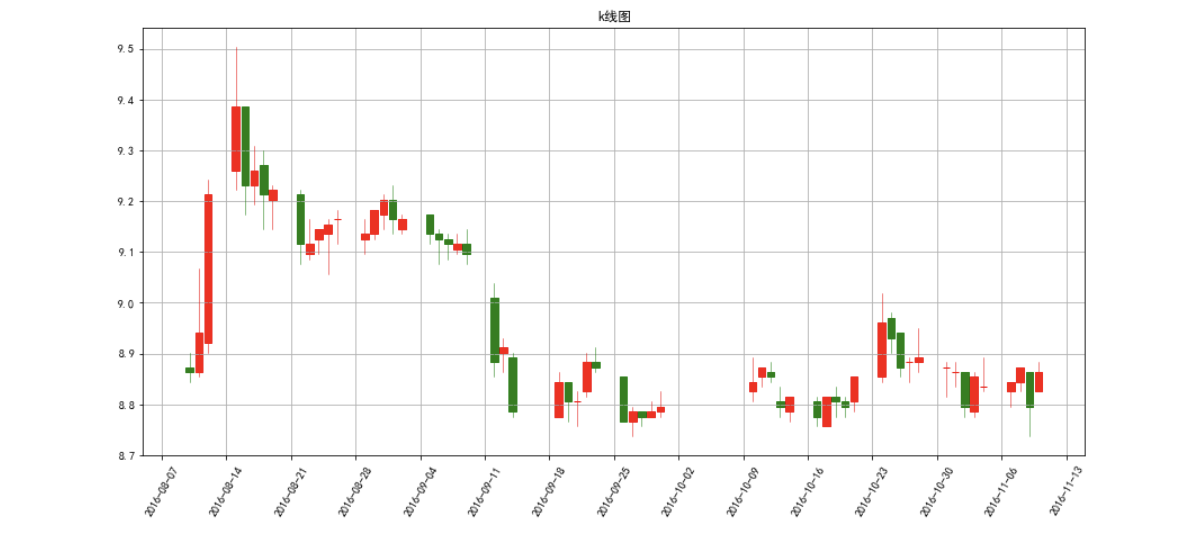
3.2、3D绘图
对于金融行业来说,用上3D绘图的场景并不是很多,但是有一个波动率平面还是需要简单介绍一下,它可以同时展示许多到期日和行权价的隐含波动率,接下来手动生成一个虚拟的类似波动率平面的图表:
# 根据两个1维ndarray对象转换为一个二维数组
strike = np.linspace(50,150,24)
ttm = np.linspace(0.5,2.5,24)
strike,ttm = np.meshgrid(strike,ttm)
# 产生一组虚假的隐含波动率
iv = (strike - 100) ** 2/ (100 * strike) / ttm
# 生成波动率图表
fig = plt.figure(figsize=(9,6))
ax = fig.gca(projection='3d')
surf = ax.plot_surface(strike, ttm, iv, rstride=2, cstride=2, cmap=plt.cm.coolwarm, linewidth=0.5, antialiased=True)
ax.set_xlabel('strike')
ax.set_ylabel('time_to_maturity')
ax.set_zlabel('implied volatility')
fig.colorbar(surf,shrink=0.5,aspect=5)
运行结果:
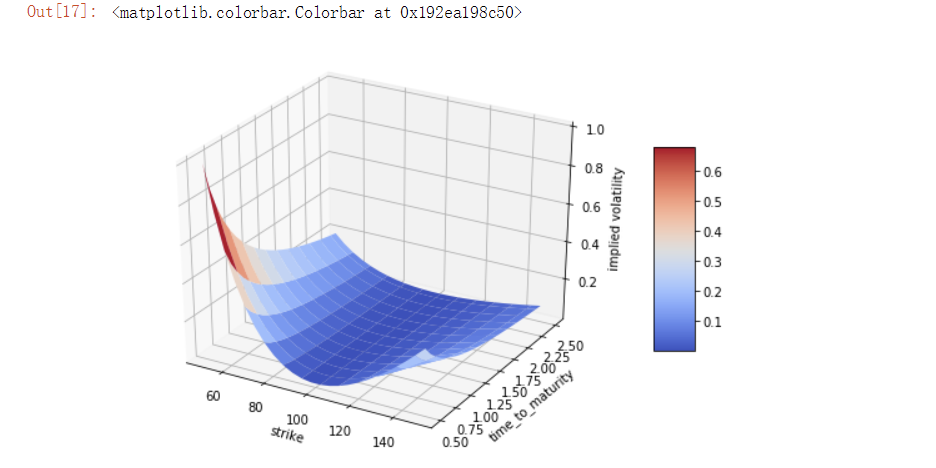
接下来主要介绍一下*plot_surface*函数的不同参数
| 参数 | 描述 |
|---|---|
| X,Y,Z | 2D数组形式的数据值 |
| rstride | 数组行距(步长大小) |
| cstride | 数组列距(步长大小) |
| color | 曲面块颜色 |
| cmap | 曲面块颜色映射 |
| facecolors | 单独曲面块表面颜色 |
| norm | 将值映射为颜色的Normalize实例 |
| vmin | 映射的最小值 |
| vmax | 映射的最大值 |
转换视角
fig = plt.figure(figsize=(8,5))
ax = fig.add_subplot(111, projection='3d')
ax.view_init(30, 60) # 通过view_init函数设置不同的视角
ax.scatter(strike, ttm, iv, zdir='z', s=25, c='b', marker='o')
ax.set_xlabel('strike')
ax.set_ylabel('time_to_maturity')
ax.set_zlabel('implied volatility')
运行结果:
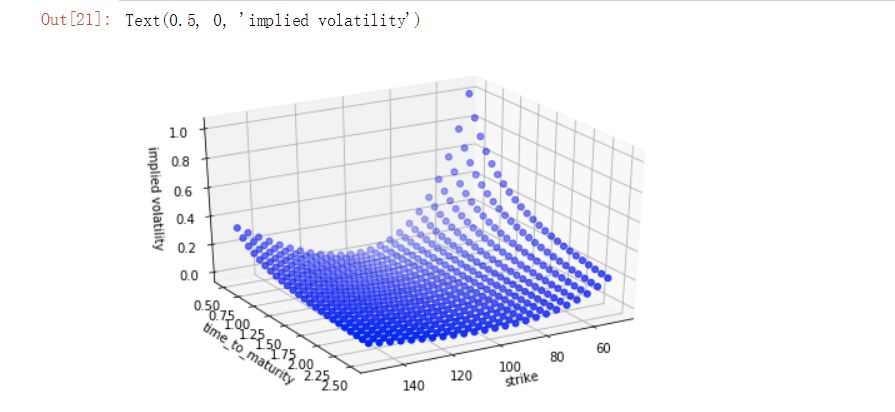
4、保存图表到文件
plt.savafig('文件名.拓展名')
文件类型是通过文件扩展名推断出来的。因此,如果你使用的是.pdf,就会得到一个PDF文件。
plt.savefig('123.pdf')
savefig并非一定要写入磁盘,也可以写入任何文件型的对象,比如BytesIO:
from io import BytesIO
buffer = BytesIO()
plt.savefig(buffer)
plot_data = buffer.getvalue()
| 参数 | 说明 | |
|---|---|---|
| fname | 含有文件路径的字符串或者Python的文件型对象。 | |
| dpi | 图像分辨率,默认为100 | |
| format | 显示设置文件格式("png","jpg","pdf","svg","ps",...) | |
| facecolor、edgecolor | 背景色,默认为"W"(白色) | |
| bbox_inches | 图表需要保存的部分。设置为”tight“,则尝试剪除图表周围空白部分 |