前言
事务处理是DBMS中最关键的技术,对SQLite也一样,它涉及到并发控制,以及故障恢复等等。在数据库中使用事务可以保证数据的统一和完整性,同时也可以提高效率。假设需要在一张表内一次插入20个人的名字才算是操作成功,那么在不使用事务的情况下,如果插入过程中出现异常或者在插入过程中出现一些其他数据库操作的话,就很有可能影响了操作的完整性。所以事务可以很好地解决这样的情况,首先事务是可以把启动事务过程中的所有操作视为事务的过程。等到所有过程执行完毕后,我们可以根据操作是否成功来决定事务是否进行提交或者回滚。提交事务后会一次性把所有数据提交到数据库,如果回滚了事务就会放弃这次的操作,而对原来表的数据不进行更改。
SQLite中分别以BEGIN、COMMIT和ROLLBACK启动、提交和回滚事务。见如下示例:
@try{ char *errorMsg; if (sqlite3_exec(_database, "BEGIN", NULL, NULL, &errorMsg)==SQLITE_OK) { NSLog(@”启动事务成功”); sqlite3_free(errorMsg); sqlite3_stmt *statement; if (sqlite3_prepare_v2(_database, [@"insert into persons(name) values(?);" UTF8String], -1, &statement, NULL)==SQLITE_OK) { //绑定参数 const char *text=[@”张三” cStringUsingEncoding:NSUTF8StringEncoding]; sqlite3_bind_text(statement, index, text, strlen(text), SQLITE_STATIC); if (sqlite3_step(statement)!=SQLITE_DONE) { sqlite3_finalize(statement); } } if (sqlite3_exec(_database, "COMMIT", NULL, NULL, &errorMsg)==SQLITE_OK) { NSLog(@”提交事务成功”); } sqlite3_free(errorMsg); }
else{ sqlite3_free(errorMsg); } } @catch(NSException *e){ char *errorMsg; if (sqlite3_exec(_database, "ROLLBACK", NULL, NULL, &errorMsg)==SQLITE_OK) { NSLog(@”回滚事务成功”); } sqlite3_free(errorMsg); } @finally{ }
在SQLite中,如果没有为当前的SQL命令(SELECT除外)显示的指定事务,那么SQLite会自动为该操作添加一个隐式的事务,以保证该操作的原子性和一致性。当然,SQLite也支持显示的事务,其语法与大多数关系型数据库相比基本相同。见如下示例:
sqlite> BEGIN TRANSACTION; sqlite> INSERT INTO testtable VALUES(1); sqlite> INSERT INTO testtable VALUES(2); sqlite> COMMIT TRANSACTION; --显示事务被提交,数据表中的数据也发生了变化。 sqlite> SELECT COUNT(*) FROM testtable; COUNT(*) ---------- 2 sqlite> BEGIN TRANSACTION; sqlite> INSERT INTO testtable VALUES(1); sqlite> ROLLBACK TRANSACTION; --显示事务被回滚,数据表中的数据没有发生变化。 sqlite> SELECT COUNT(*) FROM testtable; COUNT(*) ---------- 2
Page Cache之事务处理——SQLite原子提交的实现
下面通过具体示例来分析SQLite原子提交的实现(基于Version 3.3.6的代码):
CREATE TABLE episodes( id integer primary key,name text, cid int); insert into episodes(name,cid) values("cat",1); --插入一条记录
它经过编译器处理后生成的虚拟机代码如下:
sqlite> explain insert into episodes(name,cid) values("cat",1); 0|Trace|0|0|0|explain insert into episodes(name,cid) values("cat",1);|00| 1|Goto|0|12|0||00| 2|SetNumColumns|0|3|0||00| 3|OpenWrite|0|2|0||00| 4|NewRowid|0|2|0||00| 5|Null|0|3|0||00| 6|String8|0|4|0|cat|00| 7|Integer|1|5|0||00| 8|MakeRecord|3|3|6|dad|00| 9|Insert|0|6|2|episodes|0b| 10|Close|0|0|0||00| 11|Halt|0|0|0||00| 12|Transaction|0|1|0||00| 13|VerifyCookie|0|1|0||00| 14|Transaction|1|1|0||00| 15|VerifyCookie|1|0|0||00| 16|TableLock|0|2|1|episodes|00| 17|Goto|0|2|0||00|
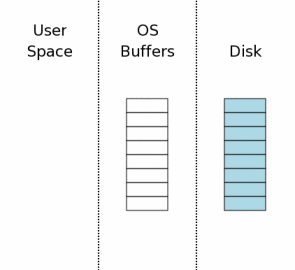
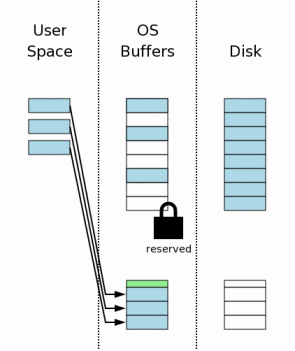
1、初始状态(Initial State)
当一个数据库连接第一次打开时,状态如图所示。图中最右边(“Disk”标注)表示保存在存储设备中的内容。每个方框代表一个扇区。蓝色的块表示这个扇区保存了原始数据。图中中间区域是操作系统的磁盘缓冲区。开始的时候,这些缓存是还没有被使用,因此这些方框是空白的。图中左边区域显示SQLite用户进程的内存。因为这个数据库连接刚刚打开,所以还没有任何数据记录被读入,所以这些内存也是空的。
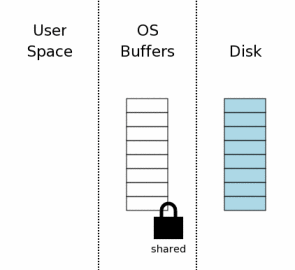
2、获取读锁(Acquiring A Read Lock)
在SQLite写数据库之前,它必须先从数据库中读取相关信息。比如,在插入新的数据时,SQLite会先从sqlite_master表中读取数据库模式(相当于数据字典),以便编译器对INSERT语句进行分析,确定数据插入的位置。
在进行读操作之前,必须先获取数据库的共享锁(shared lock),共享锁允许两个或更多的连接在同一时刻读取数据库。但是共享锁不允许其它连接对数据库进行写操作。
shared lock存在于操作系统磁盘缓存,而不是磁盘本身。文件锁的本质只是操作系统的内核数据结构,当操作系统崩溃或掉电时,这些内核数据也会随之消失。
3、读取数据
一旦得到shared lock,就可以进行读操作。如图所示,数据先由OS从磁盘读取到OS缓存,然后再由OS移到用户进程空间。一般来说,数据库文件分为很多页,而一次读操作只读取一小部分页面。如图,从8个页面读取3个页面。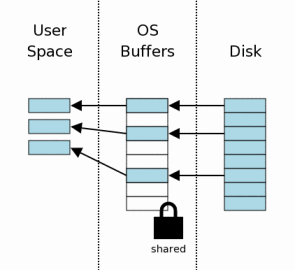
4、获取Reserved Lock
在对数据进行修改操作之前,先要获取数据库文件的Reserved Lock,Reserved Lock和shared lock的相似之处在于,它们都允许其它进程对数据库文件进行读操作。Reserved Lock和Shared Lock可以共存,但是只能是一个Reserved Lock和多个Shared Lock——多个Reserved Lock不能共存。所以,在同一时刻,只能进行一个写操作。
Reserved Lock意味着当前进程(连接)想修改数据库文件,但是还没开始修改操作,所以其它的进程可以读数据库,但不能写数据库。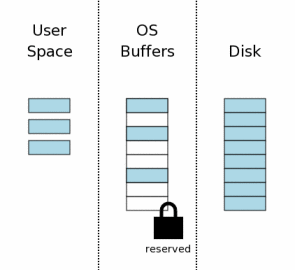
5、创建恢复日志(Creating A Rollback Journal File)
在对数据库进行写操作之前,SQLite先要创建一个单独的日志文件,然后把要修改的页面的原始数据写入日志。回滚日志包含一个日志头(图中的绿色)——记录数据库文件的原始大小。所以即使数据库文件大小改变了,我们仍知道数据库的原始大小。
从OS的角度来看,当一个文件创建时,大多数OS(Windows、Linux、Mac OS X)不会向磁盘写入数据,新创建的文件此时位于磁盘缓存中,之后才会真正写入磁盘。如图,日志文件位于OS磁盘缓存中,而不是位于磁盘。
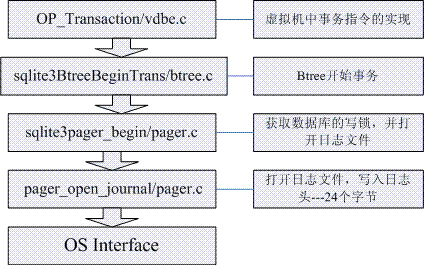
以上5步的实现代码:
//事务指令的实现 //p1为数据库文件的索引号--0为main database;1为temporary tables使用的文件 //p2不为0,一个写事务开始 case OP_Transaction: { //数据库的索引号 int i = pOp->p1; //指向数据库对应的btree Btree *pBt; assert( i>=0 && i<db->nDb ); assert( (p->btreeMask & (1<<i))!=0 ); //设置btree指针 pBt = db->aDb[i].pBt; if( pBt ){ //从这里btree开始事务,主要给文件加锁,并设置btree事务状态 rc = sqlite3BtreeBeginTrans(pBt, pOp->p2); if( rc==SQLITE_BUSY ){ p->pc = pc; p->rc = rc = SQLITE_BUSY; goto vdbe_return; } if( rc!=SQLITE_OK && rc!=SQLITE_READONLY /* && rc!=SQLITE_BUSY */ ){ goto abort_due_to_error; } } break; } //开始一个事务,如果第二个参数不为0,则一个写事务开始,否则是一个读事务 //如果wrflag>=2,一个exclusive事务开始,此时别的连接不能访问数据库 int sqlite3BtreeBeginTrans(Btree *p, int wrflag){ BtShared *pBt = p->pBt; int rc = SQLITE_OK; btreeIntegrity(p); /* If the btree is already in a write-transaction, or it ** is already in a read-transaction and a read-transaction ** is requested, this is a no-op. */ //如果b-tree处于一个写事务;或者处于一个读事务,一个读事务又请求,则返回SQLITE_OK if( p->inTrans==TRANS_WRITE || (p->inTrans==TRANS_READ && !wrflag) ){ return SQLITE_OK; } /* Write transactions are not possible on a read-only database */ //写事务不能访问只读数据库 if( pBt->readOnly && wrflag ){ return SQLITE_READONLY; } /* If another database handle has already opened a write transaction ** on this shared-btree structure and a second write transaction is ** requested, return SQLITE_BUSY. */ //如果数据库已存在一个写事务,则该写事务请求时返回SQLITE_BUSY if( pBt->inTransaction==TRANS_WRITE && wrflag ){ return SQLITE_BUSY; } do { //如果数据库对应btree的第一个页面还没读进内存 //则把该页面读进内存,数据库也相应的加read lock if( pBt->pPage1==0 ){ //加read lock,并读页面到内存 rc = lockBtree(pBt); } if( rc==SQLITE_OK && wrflag ){ //对数据库文件加RESERVED_LOCK锁 rc = sqlite3pager_begin(pBt->pPage1->aData, wrflag>1); if( rc==SQLITE_OK ){ rc = newDatabase(pBt); } } if( rc==SQLITE_OK ){ if( wrflag ) pBt->inStmt = 0; }else{ unlockBtreeIfUnused(pBt); } }while( rc==SQLITE_BUSY && pBt->inTransaction==TRANS_NONE && sqlite3InvokeBusyHandler(pBt->pBusyHandler) ); if( rc==SQLITE_OK ){ if( p->inTrans==TRANS_NONE ){ //btree的事务数加1 pBt->nTransaction++; } //设置btree事务状态 p->inTrans = (wrflag?TRANS_WRITE:TRANS_READ); if( p->inTrans>pBt->inTransaction ){ pBt->inTransaction = p->inTrans; } } btreeIntegrity(p); return rc; }
/* **获取数据库的写锁,发生以下情况时去除写锁: ** * sqlite3pager_commit() is called. ** * sqlite3pager_rollback() is called. ** * sqlite3pager_close() is called. ** * sqlite3pager_unref() is called to on every outstanding page. **pData指向数据库的打开的页面,此时并不修改,仅仅只是获取 **相应的pager,检查它是否处于read-lock状态 **如果打开的不是临时文件,则打开日志文件. **如果数据库已经处于写状态,则do nothing */ int sqlite3pager_begin(void *pData, int exFlag){ PgHdr *pPg = DATA_TO_PGHDR(pData); Pager *pPager = pPg->pPager; int rc = SQLITE_OK; assert( pPg->nRef>0 ); assert( pPager->state!=PAGER_UNLOCK ); //pager已经处于share状态 if( pPager->state==PAGER_SHARED ){ assert( pPager->aInJournal==0 ); if( MEMDB ){ pPager->state = PAGER_EXCLUSIVE; pPager->origDbSize = pPager->dbSize; }else{ //对文件加 RESERVED_LOCK rc = sqlite3OsLock(pPager->fd, RESERVED_LOCK); if( rc==SQLITE_OK ){ //设置pager的状态 pPager->state = PAGER_RESERVED; if( exFlag ){ rc = pager_wait_on_lock(pPager, EXCLUSIVE_LOCK); } } if( rc!=SQLITE_OK ){ return rc; } pPager->dirtyCache = 0; TRACE2("TRANSACTION %d ", PAGERID(pPager)); //使用日志,不是临时文件,则打开日志文件 if( pPager->useJournal && !pPager->tempFile ){ //为pager打开日志文件,pager应该处于RESERVED或EXCLUSIVE状态 //会向日志文件写入header rc = pager_open_journal(pPager); } } } return rc; }
//创建日志文件,pager应该处于RESERVED或EXCLUSIVE状态 static int pager_open_journal(Pager *pPager){ int rc; assert( !MEMDB ); assert( pPager->state>=PAGER_RESERVED ); assert( pPager->journalOpen==0 ); assert( pPager->useJournal ); assert( pPager->aInJournal==0 ); sqlite3pager_pagecount(pPager); //日志文件页面位图 pPager->aInJournal = sqliteMalloc( pPager->dbSize/8 + 1 ); if( pPager->aInJournal==0 ){ rc = SQLITE_NOMEM; goto failed_to_open_journal; } //打开日志文件 rc = sqlite3OsOpenExclusive(pPager->zJournal, &pPager->jfd, pPager->tempFile); //日志文件的位置指针 pPager->journalOff = 0; pPager->setMaster = 0; pPager->journalHdr = 0; if( rc!=SQLITE_OK ){ goto failed_to_open_journal; } /*一般来说,OS此时创建的文件位于磁盘缓存,并没有实际 **存在于磁盘,下面三个操作就是为了把结果写入磁盘,而对于 **windows系统来说,并没有提供相应API,所以实际上没有意义. */ //fullSync操作对windows没有意义 sqlite3OsSetFullSync(pPager->jfd, pPager->full_fsync); sqlite3OsSetFullSync(pPager->fd, pPager->full_fsync); /* Attempt to open a file descriptor for the directory that contains a file. **This file descriptor can be used to fsync() the directory **in order to make sure the creation of a new file is actually written to disk. */ sqlite3OsOpenDirectory(pPager->jfd, pPager->zDirectory); pPager->journalOpen = 1; pPager->journalStarted = 0; pPager->needSync = 0; pPager->alwaysRollback = 0; pPager->nRec = 0; if( pPager->errCode ){ rc = pPager->errCode; goto failed_to_open_journal; } pPager->origDbSize = pPager->dbSize; //写入日志文件的header--24个字节 rc = writeJournalHdr(pPager); if( pPager->stmtAutoopen && rc==SQLITE_OK ){ rc = sqlite3pager_stmt_begin(pPager); } if( rc!=SQLITE_OK && rc!=SQLITE_NOMEM ){ rc = pager_unwritelock(pPager); if( rc==SQLITE_OK ){ rc = SQLITE_FULL; } } return rc; failed_to_open_journal: sqliteFree(pPager->aInJournal); pPager->aInJournal = 0; if( rc==SQLITE_NOMEM ){ /* If this was a malloc() failure, then we will not be closing the pager ** file. So delete any journal file we may have just created. Otherwise, ** the system will get confused, we have a read-lock on the file and a ** mysterious journal has appeared in the filesystem. */ sqlite3OsDelete(pPager->zJournal); }else{ sqlite3OsUnlock(pPager->fd, NO_LOCK); pPager->state = PAGER_UNLOCK; } return rc; } /*写入日志文件头 **journal header的格式如下: ** - 8 bytes: 标志日志文件的魔数 ** - 4 bytes: 日志文件中记录数 ** - 4 bytes: Random number used for page hash. ** - 4 bytes: 原来数据库的大小(kb) ** - 4 bytes: 扇区大小512byte */ static int writeJournalHdr(Pager *pPager){ //日志文件头 char zHeader[sizeof(aJournalMagic)+16]; int rc = seekJournalHdr(pPager); if( rc ) return rc; pPager->journalHdr = pPager->journalOff; if( pPager->stmtHdrOff==0 ){ pPager->stmtHdrOff = pPager->journalHdr; } //设置文件指针指向header之后 pPager->journalOff += JOURNAL_HDR_SZ(pPager); /* FIX ME: ** ** Possibly for a pager not in no-sync mode, the journal magic should not ** be written until nRec is filled in as part of next syncJournal(). ** ** Actually maybe the whole journal header should be delayed until that ** point. Think about this. */ memcpy(zHeader, aJournalMagic, sizeof(aJournalMagic)); /* The nRec Field. 0xFFFFFFFF for no-sync journals. */ put32bits(&zHeader[sizeof(aJournalMagic)], pPager->noSync ? 0xffffffff : 0); /* The random check-hash initialiser */ sqlite3Randomness(sizeof(pPager->cksumInit), &pPager->cksumInit); put32bits(&zHeader[sizeof(aJournalMagic)+4], pPager->cksumInit); /* The initial database size */ put32bits(&zHeader[sizeof(aJournalMagic)+8], pPager->dbSize); /* The assumed sector size for this process */ put32bits(&zHeader[sizeof(aJournalMagic)+12], pPager->sectorSize); //写入文件头 rc = sqlite3OsWrite(pPager->jfd, zHeader, sizeof(zHeader)); /* The journal header has been written successfully. Seek the journal ** file descriptor to the end of the journal header sector. */ if( rc==SQLITE_OK ){ rc = sqlite3OsSeek(pPager->jfd, pPager->journalOff-1); if( rc==SQLITE_OK ){ rc = sqlite3OsWrite(pPager->jfd, "�00", 1); } } return rc; }
其实现过程如下图所示:
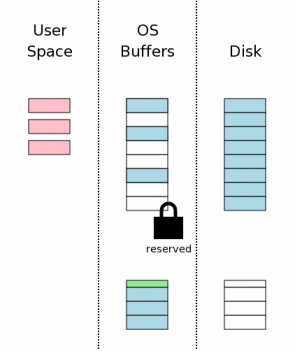
6、修改位于用户进程空间的页面(Changing Database Pages In User Space)
页面的原始数据写入日志之后,就可以修改页面了——位于用户进程空间。每个数据库连接都有自己私有的空间,所以页面的变化只对该连接可见,而对其它连接的数据仍然是磁盘缓存中的数据。从这里可以明白一件事:一个进程在修改页面数据的同时,其它进程可以继续进行读操作。图中的红色表示修改的页面。
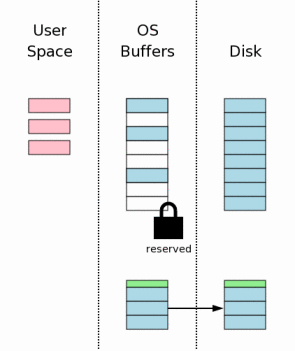
7、日志文件刷入磁盘(Flushing The Rollback Journal File To Mass Storage)
接下来把日志文件的内容刷入磁盘,这对于数据库从意外中恢复来说是至关重要的一步。而且这通常也是一个耗时的操作,因为磁盘I/O速度很慢。
这个步骤不只把日志文件刷入磁盘那么简单,它的实现实际上分成两步:首先把日志文件的内容刷入磁盘(即页面数据);然后把日志文件中页面的数目写入日志文件头,再把header刷入磁盘(这一过程在代码中清晰可见)。
代码如下:
/* **Sync日志文件,保证所有的脏页面写入磁盘日志文件 */ static int syncJournal(Pager *pPager){ PgHdr *pPg; int rc = SQLITE_OK; /* Sync the journal before modifying the main database ** (assuming there is a journal and it needs to be synced.) */ if( pPager->needSync ){ if( !pPager->tempFile ){ assert( pPager->journalOpen ); /* assert( !pPager->noSync ); // noSync might be set if synchronous ** was turned off after the transaction was started. Ticket #615 */ #ifndef NDEBUG { /* Make sure the pPager->nRec counter we are keeping agrees ** with the nRec computed from the size of the journal file. */ i64 jSz; rc = sqlite3OsFileSize(pPager->jfd, &jSz); if( rc!=0 ) return rc; assert( pPager->journalOff==jSz ); } #endif { /* Write the nRec value into the journal file header. If in ** full-synchronous mode, sync the journal first. This ensures that ** all data has really hit the disk before nRec is updated to mark ** it as a candidate for rollback. */ if( pPager->fullSync ){ TRACE2("SYNC journal of %d ", PAGERID(pPager)); //首先保证脏页面中所有的数据都已经写入日志文件 rc = sqlite3OsSync(pPager->jfd, 0); if( rc!=0 ) return rc; } rc = sqlite3OsSeek(pPager->jfd, pPager->journalHdr + sizeof(aJournalMagic)); if( rc ) return rc; //页面的数目写入日志文件 rc = write32bits(pPager->jfd, pPager->nRec); if( rc ) return rc; rc = sqlite3OsSeek(pPager->jfd, pPager->journalOff); if( rc ) return rc; } TRACE2("SYNC journal of %d ", PAGERID(pPager)); rc = sqlite3OsSync(pPager->jfd, pPager->full_fsync); if( rc!=0 ) return rc; pPager->journalStarted = 1; } pPager->needSync = 0; /* Erase the needSync flag from every page. */ //清除needSync标志位 for(pPg=pPager->pAll; pPg; pPg=pPg->pNextAll){ pPg->needSync = 0; } pPager->pFirstSynced = pPager->pFirst; } #ifndef NDEBUG /* If the Pager.needSync flag is clear then the PgHdr.needSync ** flag must also be clear for all pages. Verify that this ** invariant is true. */ else{ for(pPg=pPager->pAll; pPg; pPg=pPg->pNextAll){ assert( pPg->needSync==0 ); } assert( pPager->pFirstSynced==pPager->pFirst ); } #endif return rc; }
8、获取排斥锁(Obtaining An Exclusive Lock)
在对数据库文件进行修改之前(注:这里不是内存中的页面),我们必须得到数据库文件的排斥锁(Exclusive Lock)。得到排斥锁的过程可分为两步:首先得到Pending lock;然后Pending lock升级到exclusive lock。
Pending lock允许其它已经存在的Shared lock继续读数据库文件,但是不允许产生新的shared lock,这样做目的是为了防止写操作发生饿死情况。一旦所有的shared lock完成操作,则pending lock升级到exclusive lock。
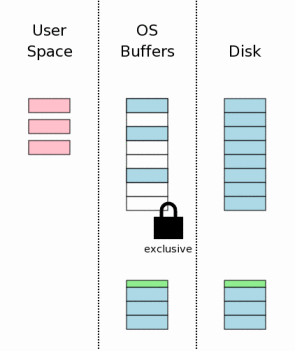
9、修改的页面写入文件(Writing Changes To The Database File)
一旦得到exclusive lock,其它的进程就不能进行读操作,此时就可以把修改的页面写回数据库文件,但是通常OS都把结果暂时保存到磁盘缓存中,直到某个时刻才会真正把结果写入磁盘。
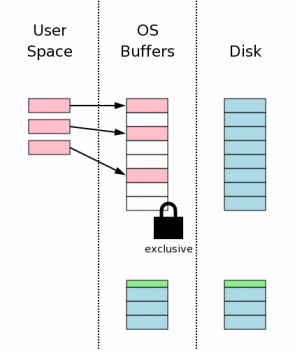
以上2步的实现代码:
//把所有的脏页面写入数据库 //到这里开始获取EXCLUSIVEQ锁,并将页面写回操作系统文件 static int pager_write_pagelist(PgHdr *pList){ Pager *pPager; int rc; if( pList==0 ) return SQLITE_OK; pPager = pList->pPager; /* At this point there may be either a RESERVED or EXCLUSIVE lock on the ** database file. If there is already an EXCLUSIVE lock, the following ** calls to sqlite3OsLock() are no-ops. ** ** Moving the lock from RESERVED to EXCLUSIVE actually involves going ** through an intermediate state PENDING. A PENDING lock prevents new ** readers from attaching to the database but is unsufficient for us to ** write. The idea of a PENDING lock is to prevent new readers from ** coming in while we wait for existing readers to clear. ** ** While the pager is in the RESERVED state, the original database file ** is unchanged and we can rollback without having to playback the ** journal into the original database file. Once we transition to ** EXCLUSIVE, it means the database file has been changed and any rollback ** will require a journal playback. */ //加EXCLUSIVE_LOCK锁 rc = pager_wait_on_lock(pPager, EXCLUSIVE_LOCK); if( rc!=SQLITE_OK ){ return rc; } while( pList ){ assert( pList->dirty ); rc = sqlite3OsSeek(pPager->fd, (pList->pgno-1)*(i64)pPager->pageSize); if( rc ) return rc; /* If there are dirty pages in the page cache with page numbers greater ** than Pager.dbSize, this means sqlite3pager_truncate() was called to ** make the file smaller (presumably by auto-vacuum code). Do not write ** any such pages to the file. */ if( pList->pgno<=pPager->dbSize ){ char *pData = CODEC2(pPager, PGHDR_TO_DATA(pList), pList->pgno, 6); TRACE3("STORE %d page %d ", PAGERID(pPager), pList->pgno); //写入文件 rc = sqlite3OsWrite(pPager->fd, pData, pPager->pageSize); TEST_INCR(pPager->nWrite); } #ifndef NDEBUG else{ TRACE3("NOSTORE %d page %d ", PAGERID(pPager), pList->pgno); } #endif if( rc ) return rc; //设置dirty pList->dirty = 0; #ifdef SQLITE_CHECK_PAGES pList->pageHash = pager_pagehash(pList); #endif //指向下一个脏页面 pList = pList->pDirty; } return SQLITE_OK; }
10、修改结果刷入存储设备(Flushing Changes To Mass Storage)
为了保证修改结果真正写入磁盘,这一步必不可少。对于数据库存的完整性,这一步也是关键的一步。由于要进行实际的I/O操作,所以和第7步一样,将花费较多的时间。
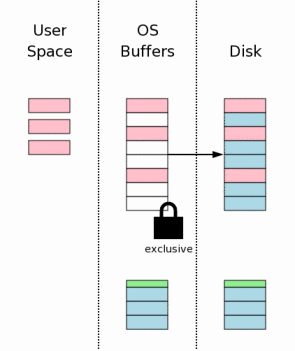
以上几步实现代码如下(以上几步是在函数sqlite3BtreeSync()--btree.c中调用的):
//同步btree对应的数据库文件 //该函数返回之后,只需要提交写事务,删除日志文件 int sqlite3BtreeSync(Btree *p, const char *zMaster){ int rc = SQLITE_OK; if( p->inTrans==TRANS_WRITE ){ BtShared *pBt = p->pBt; Pgno nTrunc = 0; #ifndef SQLITE_OMIT_AUTOVACUUM if( pBt->autoVacuum ){ rc = autoVacuumCommit(pBt, &nTrunc); if( rc!=SQLITE_OK ){ return rc; } } #endif //调用pager进行sync rc = sqlite3pager_sync(pBt->pPager, zMaster, nTrunc); } return rc; } //把pager所有脏页面写回文件 int sqlite3pager_sync(Pager *pPager, const char *zMaster, Pgno nTrunc){ int rc = SQLITE_OK; TRACE4("DATABASE SYNC: File=%s zMaster=%s nTrunc=%d ", pPager->zFilename, zMaster, nTrunc); /* If this is an in-memory db, or no pages have been written to, or this ** function has already been called, it is a no-op. */ //pager不处于PAGER_SYNCED状态,dirtyCache为1, //则进行sync操作 if( pPager->state!=PAGER_SYNCED && !MEMDB && pPager->dirtyCache ){ PgHdr *pPg; assert( pPager->journalOpen ); /* If a master journal file name has already been written to the ** journal file, then no sync is required. This happens when it is ** written, then the process fails to upgrade from a RESERVED to an ** EXCLUSIVE lock. The next time the process tries to commit the ** transaction the m-j name will have already been written. */ if( !pPager->setMaster ){ //pager修改计数 rc = pager_incr_changecounter(pPager); if( rc!=SQLITE_OK ) goto sync_exit; #ifndef SQLITE_OMIT_AUTOVACUUM if( nTrunc!=0 ){ /* If this transaction has made the database smaller, then all pages ** being discarded by the truncation must be written to the journal ** file. */ Pgno i; void *pPage; int iSkip = PAGER_MJ_PGNO(pPager); for( i=nTrunc+1; i<=pPager->origDbSize; i++ ){ if( !(pPager->aInJournal[i/8] & (1<<(i&7))) && i!=iSkip ){ rc = sqlite3pager_get(pPager, i, &pPage); if( rc!=SQLITE_OK ) goto sync_exit; rc = sqlite3pager_write(pPage); sqlite3pager_unref(pPage); if( rc!=SQLITE_OK ) goto sync_exit; } } } #endif rc = writeMasterJournal(pPager, zMaster); if( rc!=SQLITE_OK ) goto sync_exit; //sync日志文件 rc = syncJournal(pPager); if( rc!=SQLITE_OK ) goto sync_exit; } #ifndef SQLITE_OMIT_AUTOVACUUM if( nTrunc!=0 ){ rc = sqlite3pager_truncate(pPager, nTrunc); if( rc!=SQLITE_OK ) goto sync_exit; } #endif /* Write all dirty pages to the database file */ pPg = pager_get_all_dirty_pages(pPager); //把所有脏页面写回操作系统文件 rc = pager_write_pagelist(pPg); if( rc!=SQLITE_OK ) goto sync_exit; /* Sync the database file. */ //sync数据库文件 if( !pPager->noSync ){ rc = sqlite3OsSync(pPager->fd, 0); } pPager->state = PAGER_SYNCED; }else if( MEMDB && nTrunc!=0 ){ rc = sqlite3pager_truncate(pPager, nTrunc); } sync_exit: return rc; }
接下来的过程如下图所示:
11、删除日志文件(Deleting The Rollback Journal)
一旦更改写入设备,日志文件将会被删除,这是事务真正提交的时刻。如果在这之前系统发生崩溃,就会进行恢复处理,使得数据库和没发生改变一样;如果在这之后系统发生崩溃,表明所有的更改都已经写入磁盘。SQLite就是根据日志存在情况决定是否对数据库进行恢复处理。删除文件本质上不是一个原子操作,但是从用户进程的角度来看是一个原子操作,所以一个事务看起来是一个原子操作。
在许多系统中,删除文件也是一个高代价的操作。作为优化,SQLite可以配置成把日志文件的长度截为0或者把日志文件头清零。
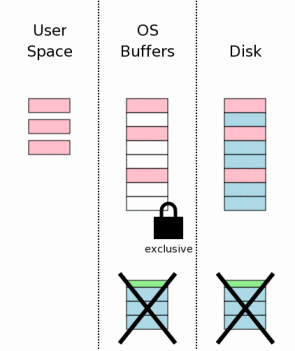
12、释放锁(Releasing The Lock)
作为原子提交的最后一步,释放排斥锁使得其它进程可以开始访问数据库。
下图中,我们指明了当锁被释放的时候用户空间所拥有的信息已经被清空了。对于老版本的SQLite可以这么认为,但最新的SQLite会保存些用户空间的缓存不会被清空,可能下一个事务开始的时候,这些数据刚好可以用上。重新利用这些内存要比再次从操作系统磁盘缓存或者硬盘中读取轻松和快捷得多。在再次使用这些数据之前,我们必须先取得一个共享锁,同时我们还不得不去检查一下,保证还没有其他进程在我们拥有共享锁之前对数据库文件进行了修改。数据库文件的第一页中有一个计数器,数据库文件每做一次修改,这个计数器就会增长一下。我们可以通过检查这个计数器就可得知是否有其他进程修改过数据库文件。如果数据库文件已经被修改过了,那么用户内存空间的缓存就不得不清空,并重新读入。大多数情况下,这种情况不大会发生,因此用户空间的内存缓存将是有效的,这对于性能提高来说作用是显著的。
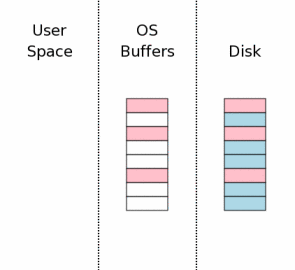
以上2步(以上2步是在sqlite3BtreeCommit()--btree.c函数中实现的)代码如下:
//提交事务,至此一个事务完成.主要做两件事: //删除日志文件,释放数据库文件的写锁 int sqlite3BtreeCommit(Btree *p){ BtShared *pBt = p->pBt; btreeIntegrity(p); /* If the handle has a write-transaction open, commit the shared-btrees ** transaction and set the shared state to TRANS_READ. */ if( p->inTrans==TRANS_WRITE ){ int rc; assert( pBt->inTransaction==TRANS_WRITE ); assert( pBt->nTransaction>0 ); //调用pager,提交事务 rc = sqlite3pager_commit(pBt->pPager); if( rc!=SQLITE_OK ){ return rc; } pBt->inTransaction = TRANS_READ; pBt->inStmt = 0; } unlockAllTables(p); /* If the handle has any kind of transaction open, decrement the transaction ** count of the shared btree. If the transaction count reaches 0, set ** the shared state to TRANS_NONE. The unlockBtreeIfUnused() call below ** will unlock the pager. */ if( p->inTrans!=TRANS_NONE ){ pBt->nTransaction--; if( 0==pBt->nTransaction ){ pBt->inTransaction = TRANS_NONE; } } } //提交事务,主要调用pager_unwritelock()函数 int sqlite3pager_commit(Pager *pPager){ int rc; PgHdr *pPg; if( pPager->errCode ){ return pPager->errCode; } if( pPager->state<PAGER_RESERVED ){ return SQLITE_ERROR; } TRACE2("COMMIT %d ", PAGERID(pPager)); if( MEMDB ){ pPg = pager_get_all_dirty_pages(pPager); while( pPg ){ clearHistory(PGHDR_TO_HIST(pPg, pPager)); pPg->dirty = 0; pPg->inJournal = 0; pPg->inStmt = 0; pPg->needSync = 0; pPg->pPrevStmt = pPg->pNextStmt = 0; pPg = pPg->pDirty; } pPager->pDirty = 0; #ifndef NDEBUG for(pPg=pPager->pAll; pPg; pPg=pPg->pNextAll){ PgHistory *pHist = PGHDR_TO_HIST(pPg, pPager); assert( !pPg->alwaysRollback ); assert( !pHist->pOrig ); assert( !pHist->pStmt ); } #endif pPager->pStmt = 0; pPager->state = PAGER_SHARED; return SQLITE_OK; } if( pPager->dirtyCache==0 ){ /* Exit early (without doing the time-consuming sqlite3OsSync() calls) ** if there have been no changes to the database file. */ assert( pPager->needSync==0 ); rc = pager_unwritelock(pPager); pPager->dbSize = -1; return rc; } assert( pPager->journalOpen ); rc = sqlite3pager_sync(pPager, 0, 0); //删除文件,释放写锁 if( rc==SQLITE_OK ){ rc = pager_unwritelock(pPager); pPager->dbSize = -1; } return rc; } //对数据库加read lock,删除日志文件 static int pager_unwritelock(Pager *pPager){ PgHdr *pPg; int rc; assert( !MEMDB ); if( pPager->state<PAGER_RESERVED ){ return SQLITE_OK; } sqlite3pager_stmt_commit(pPager); if( pPager->stmtOpen ){ sqlite3OsClose(&pPager->stfd); pPager->stmtOpen = 0; } if( pPager->journalOpen ){ //关闭日志文件 sqlite3OsClose(&pPager->jfd); pPager->journalOpen = 0; //删除日志文件 sqlite3OsDelete(pPager->zJournal); sqliteFree( pPager->aInJournal ); pPager->aInJournal = 0; for(pPg=pPager->pAll; pPg; pPg=pPg->pNextAll){ pPg->inJournal = 0; pPg->dirty = 0; pPg->needSync = 0; #ifdef SQLITE_CHECK_PAGES pPg->pageHash = pager_pagehash(pPg); #endif } pPager->pDirty = 0; pPager->dirtyCache = 0; pPager->nRec = 0; }else{ assert( pPager->aInJournal==0 ); assert( pPager->dirtyCache==0 || pPager->useJournal==0 ); } //释放写锁,加读锁 rc = sqlite3OsUnlock(pPager->fd, SHARED_LOCK); pPager->state = PAGER_SHARED; pPager->origDbSize = 0; pPager->setMaster = 0; pPager->needSync = 0; pPager->pFirstSynced = pPager->pFirst; return rc; }
下图可进一步描述该过程:
其中sqlite3BtreeSync()和sqlite3BtreeCommit()是如何被调用的?
一般来说,事务提交方式为自动提交的话,在虚拟机中的OP_Halt指令实现提交事务,相关代码如下:
//虚拟机停机指令 case OP_Halt: { /* no-push */ p->pTos = pTos; p->rc = pOp->p1; p->pc = pc; p->errorAction = pOp->p2; if( pOp->p3 ){ sqlite3SetString(&p->zErrMsg, pOp->p3, (char*)0); } //设置虚拟机状态SQLITE_MAGIC_RUN 为 SQLITE_MAGIC_HALT, //并提交事务 rc = sqlite3VdbeHalt(p); assert( rc==SQLITE_BUSY || rc==SQLITE_OK ); if( rc==SQLITE_BUSY ){ p->rc = SQLITE_BUSY; return SQLITE_BUSY; } return p->rc ? SQLITE_ERROR : SQLITE_DONE; } //当虚拟机要停机时,调用该函数,如果VDBE改变了数据库且为自动 //提交模式,则提交这些改变 int sqlite3VdbeHalt(Vdbe *p){ sqlite3 *db = p->db; int i; int (*xFunc)(Btree *pBt) = 0; /* Function to call on each btree backend */ int isSpecialError; /* Set to true if SQLITE_NOMEM or IOERR */ /* This function contains the logic that determines if a statement or ** transaction will be committed or rolled back as a result of the ** execution of this virtual machine. ** ** Special errors: ** ** If an SQLITE_NOMEM error has occured in a statement that writes to ** the database, then either a statement or transaction must be rolled ** back to ensure the tree-structures are in a consistent state. A ** statement transaction is rolled back if one is open, otherwise the ** entire transaction must be rolled back. ** ** If an SQLITE_IOERR error has occured in a statement that writes to ** the database, then the entire transaction must be rolled back. The ** I/O error may have caused garbage to be written to the journal ** file. Were the transaction to continue and eventually be rolled ** back that garbage might end up in the database file. ** ** In both of the above cases, the Vdbe.errorAction variable is ** ignored. If the sqlite3.autoCommit flag is false and a transaction ** is rolled back, it will be set to true. ** ** Other errors: ** ** No error: ** */ if( sqlite3MallocFailed() ){ p->rc = SQLITE_NOMEM; } if( p->magic!=VDBE_MAGIC_RUN ){ /* Already halted. Nothing to do. */ assert( p->magic==VDBE_MAGIC_HALT ); return SQLITE_OK; } //释放虚拟机中所有的游标 closeAllCursors(p); checkActiveVdbeCnt(db); /* No commit or rollback needed if the program never started */ if( p->pc>=0 ){ /* Check for one of the special errors - SQLITE_NOMEM or SQLITE_IOERR */ isSpecialError = ((p->rc==SQLITE_NOMEM || p->rc==SQLITE_IOERR)?1:0); if( isSpecialError ){ /* This loop does static analysis of the query to see which of the ** following three categories it falls into: ** ** Read-only ** Query with statement journal ** Query without statement journal ** ** We could do something more elegant than this static analysis (i.e. ** store the type of query as part of the compliation phase), but ** handling malloc() or IO failure is a fairly obscure edge case so ** this is probably easier. Todo: Might be an opportunity to reduce ** code size a very small amount though */ int isReadOnly = 1; int isStatement = 0; assert(p->aOp || p->nOp==0); for(i=0; i<p->nOp; i++){ switch( p->aOp[i].opcode ){ case OP_Transaction: isReadOnly = 0; break; case OP_Statement: isStatement = 1; break; } } /* If the query was read-only, we need do no rollback at all. Otherwise, ** proceed with the special handling. */ if( !isReadOnly ){ if( p->rc==SQLITE_NOMEM && isStatement ){ xFunc = sqlite3BtreeRollbackStmt; }else{ /* We are forced to roll back the active transaction. Before doing ** so, abort any other statements this handle currently has active. */ sqlite3AbortOtherActiveVdbes(db, p); sqlite3RollbackAll(db); db->autoCommit = 1; } } } /* If the auto-commit flag is set and this is the only active vdbe, then ** we do either a commit or rollback of the current transaction. ** ** Note: This block also runs if one of the special errors handled ** above has occured. */ //如果自动提交事务,则提交事务 if( db->autoCommit && db->activeVdbeCnt==1 ){ if( p->rc==SQLITE_OK || (p->errorAction==OE_Fail && !isSpecialError) ){ /* The auto-commit flag is true, and the vdbe program was ** successful or hit an 'OR FAIL' constraint. This means a commit ** is required. */ //提交事务 int rc = vdbeCommit(db); if( rc==SQLITE_BUSY ){ return SQLITE_BUSY; }else if( rc!=SQLITE_OK ){ p->rc = rc; sqlite3RollbackAll(db); }else{ sqlite3CommitInternalChanges(db); } }else{ sqlite3RollbackAll(db); } }else if( !xFunc ){ if( p->rc==SQLITE_OK || p->errorAction==OE_Fail ){ xFunc = sqlite3BtreeCommitStmt; }else if( p->errorAction==OE_Abort ){ xFunc = sqlite3BtreeRollbackStmt; }else{ sqlite3AbortOtherActiveVdbes(db, p); sqlite3RollbackAll(db); db->autoCommit = 1; } } /* If xFunc is not NULL, then it is one of sqlite3BtreeRollbackStmt or ** sqlite3BtreeCommitStmt. Call it once on each backend. If an error occurs ** and the return code is still SQLITE_OK, set the return code to the new ** error value. */ assert(!xFunc || xFunc==sqlite3BtreeCommitStmt || xFunc==sqlite3BtreeRollbackStmt ); for(i=0; xFunc && i<db->nDb; i++){ int rc; Btree *pBt = db->aDb[i].pBt; if( pBt ){ rc = xFunc(pBt); if( rc && (p->rc==SQLITE_OK || p->rc==SQLITE_CONSTRAINT) ){ p->rc = rc; sqlite3SetString(&p->zErrMsg, 0); } } } /* If this was an INSERT, UPDATE or DELETE and the statement was committed, ** set the change counter. */ if( p->changeCntOn && p->pc>=0 ){ if( !xFunc || xFunc==sqlite3BtreeCommitStmt ){ sqlite3VdbeSetChanges(db, p->nChange); }else{ sqlite3VdbeSetChanges(db, 0); } p->nChange = 0; } /* Rollback or commit any schema changes that occurred. */ if( p->rc!=SQLITE_OK && db->flags&SQLITE_InternChanges ){ sqlite3ResetInternalSchema(db, 0); db->flags = (db->flags | SQLITE_InternChanges); } } /* We have successfully halted and closed the VM. Record this fact. */ if( p->pc>=0 ){ db->activeVdbeCnt--; } p->magic = VDBE_MAGIC_HALT; checkActiveVdbeCnt(db); return SQLITE_OK; } //提交事务,主要调用: //sqlite3BtreeSync()--同步btree, sqlite3BtreeCommit()---提交事务 static int vdbeCommit(sqlite3 *db){ int i; int nTrans = 0; /* Number of databases with an active write-transaction */ int rc = SQLITE_OK; int needXcommit = 0; for(i=0; i<db->nDb; i++){ Btree *pBt = db->aDb[i].pBt; if( pBt && sqlite3BtreeIsInTrans(pBt) ){ needXcommit = 1; if( i!=1 ) nTrans++; } } /* If there are any write-transactions at all, invoke the commit hook */ if( needXcommit && db->xCommitCallback ){ sqlite3SafetyOff(db); rc = db->xCommitCallback(db->pCommitArg); sqlite3SafetyOn(db); if( rc ){ return SQLITE_CONSTRAINT; } } /* The simple case - no more than one database file (not counting the ** TEMP database) has a transaction active. There is no need for the ** master-journal. ** ** If the return value of sqlite3BtreeGetFilename() is a zero length ** string, it means the main database is :memory:. In that case we do ** not support atomic multi-file commits, so use the simple case then ** too. */ //简单的情况,只有一个数据库文件,不需要master-journal if( 0==strlen(sqlite3BtreeGetFilename(db->aDb[0].pBt)) || nTrans<=1 ){ for(i=0; rc==SQLITE_OK && i<db->nDb; i++){ Btree *pBt = db->aDb[i].pBt; if( pBt ){ //同步btree rc = sqlite3BtreeSync(pBt, 0); } } /* Do the commit only if all databases successfully synced */ //commite事务 if( rc==SQLITE_OK ){ for(i=0; i<db->nDb; i++){ Btree *pBt = db->aDb[i].pBt; if( pBt ){ sqlite3BtreeCommit(pBt); } } } } /* The complex case - There is a multi-file write-transaction active. ** This requires a master journal file to ensure the transaction is ** committed atomicly. */ #ifndef SQLITE_OMIT_DISKIO else{ int needSync = 0; char *zMaster = 0; /* File-name for the master journal */ char const *zMainFile = sqlite3BtreeGetFilename(db->aDb[0].pBt); OsFile *master = 0; /* Select a master journal file name */ do { u32 random; sqliteFree(zMaster); sqlite3Randomness(sizeof(random), &random); zMaster = sqlite3MPrintf("%s-mj%08X", zMainFile, random&0x7fffffff); if( !zMaster ){ return SQLITE_NOMEM; } }while( sqlite3OsFileExists(zMaster) ); /* Open the master journal. */ rc = sqlite3OsOpenExclusive(zMaster, &master, 0); if( rc!=SQLITE_OK ){ sqliteFree(zMaster); return rc; } /* Write the name of each database file in the transaction into the new ** master journal file. If an error occurs at this point close ** and delete the master journal file. All the individual journal files ** still have 'null' as the master journal pointer, so they will roll ** back independently if a failure occurs. */ for(i=0; i<db->nDb; i++){ Btree *pBt = db->aDb[i].pBt; if( i==1 ) continue; /* Ignore the TEMP database */ if( pBt && sqlite3BtreeIsInTrans(pBt) ){ char const *zFile = sqlite3BtreeGetJournalname(pBt); if( zFile[0]==0 ) continue; /* Ignore :memory: databases */ if( !needSync && !sqlite3BtreeSyncDisabled(pBt) ){ needSync = 1; } rc = sqlite3OsWrite(master, zFile, strlen(zFile)+1); if( rc!=SQLITE_OK ){ sqlite3OsClose(&master); sqlite3OsDelete(zMaster); sqliteFree(zMaster); return rc; } } } /* Sync the master journal file. Before doing this, open the directory ** the master journal file is store in so that it gets synced too. */ zMainFile = sqlite3BtreeGetDirname(db->aDb[0].pBt); rc = sqlite3OsOpenDirectory(master, zMainFile); if( rc!=SQLITE_OK || (needSync && (rc=sqlite3OsSync(master,0))!=SQLITE_OK) ){ sqlite3OsClose(&master); sqlite3OsDelete(zMaster); sqliteFree(zMaster); return rc; } /* Sync all the db files involved in the transaction. The same call ** sets the master journal pointer in each individual journal. If ** an error occurs here, do not delete the master journal file. ** ** If the error occurs during the first call to sqlite3BtreeSync(), ** then there is a chance that the master journal file will be ** orphaned. But we cannot delete it, in case the master journal ** file name was written into the journal file before the failure ** occured. */ for(i=0; i<db->nDb; i++){ Btree *pBt = db->aDb[i].pBt; if( pBt && sqlite3BtreeIsInTrans(pBt) ){ rc = sqlite3BtreeSync(pBt, zMaster); if( rc!=SQLITE_OK ){ sqlite3OsClose(&master); sqliteFree(zMaster); return rc; } } } sqlite3OsClose(&master); /* Delete the master journal file. This commits the transaction. After ** doing this the directory is synced again before any individual ** transaction files are deleted. */ rc = sqlite3OsDelete(zMaster); assert( rc==SQLITE_OK ); sqliteFree(zMaster); zMaster = 0; rc = sqlite3OsSyncDirectory(zMainFile); if( rc!=SQLITE_OK ){ /* This is not good. The master journal file has been deleted, but ** the directory sync failed. There is no completely safe course of ** action from here. The individual journals contain the name of the ** master journal file, but there is no way of knowing if that ** master journal exists now or if it will exist after the operating ** system crash that may follow the fsync() failure. */ return rc; } /* All files and directories have already been synced, so the following ** calls to sqlite3BtreeCommit() are only closing files and deleting ** journals. If something goes wrong while this is happening we don't ** really care. The integrity of the transaction is already guaranteed, ** but some stray 'cold' journals may be lying around. Returning an ** error code won't help matters. */ for(i=0; i<db->nDb; i++){ Btree *pBt = db->aDb[i].pBt; if( pBt ){ sqlite3BtreeCommit(pBt); } } } #endif return rc; }
Page Cache之并发控制
pager层是SQLite实现最为核心的模块,它具有四大功能:I/O、页面缓存、并发控制和日志恢复。而这些功能不仅是上层Btree的基础,而且对系统的性能和健壮性有至关重要的影响。其中并发控制和日志恢复是事务处理实现的基础。SQLite并发控制的机制非常简单——即封锁机制;另外,它的查询优化机制也非常简单——基于索引。这一切使得整个SQLite的实现变得简单,同时变得很小,保证其运行速度非常快,所以特别适合嵌入式设备。SQLite是基于锁来实现并发控制的,其锁机制实现得非常简单而巧妙。
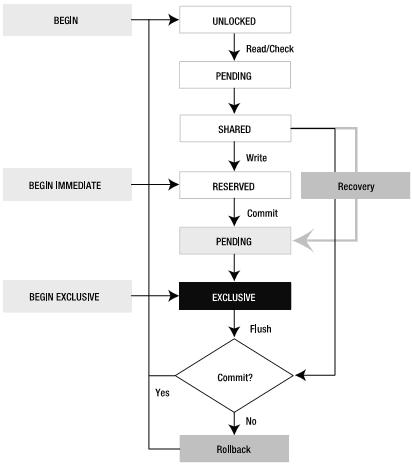
SQLite的并发控制机制是采用加锁的方式,实现简单,也非常巧妙,如下图所示:
1、RESERVED LOCK
RESERVED锁意味着进程将要对数据库进行写操作。某一时刻只能有一个RESERVED Lock,但是RESERVED锁和SHARED锁可以共存,而且可以对数据库加新的SHARED锁。
为什么要用RESERVED锁?
主要是出于并发性的考虑。由于SQLite只有库级排斥锁(EXCLUSIVE LOCK),如果写事务一开始就上EXCLUSIVE锁,然后再进行实际的数据更新,写磁盘操作,这会使得并发性大大降低。而SQLite一旦得到数据库的RESERVED锁,就可以对缓存中的数据进行修改,而与此同时,其它进程可以继续进行读操作。直到真正需要写磁盘时才对数据库加EXCLUSIVE锁。
2、PENDING LOCK
PENDING LOCK意味着进程已经完成缓存中的数据修改,并想立即将更新写入磁盘。它将等待此时已经存在的读锁事务完成,但是不允许对数据库加新的SHARED LOCK(这与RESERVED LOCK相区别)。
为什么要有PENDING LOCK?
主要是为了防止出现写饿死的情况。由于写事务先要获取RESERVED LOCK,所以可能一直产生新的SHARED LOCK,使得写事务发生饿死的情况。
3、加锁机制的具体实现
SQLite在pager层获取锁的函数如下:
//获取一个文件的锁,如果忙则重复该操作, //直到busy回调函数返回flase,或者成功获得锁 static int pager_wait_on_lock(Pager *pPager, int locktype){ int rc; assert( PAGER_SHARED==SHARED_LOCK ); assert( PAGER_RESERVED==RESERVED_LOCK ); assert( PAGER_EXCLUSIVE==EXCLUSIVE_LOCK ); if( pPager->state>=locktype ){ rc = SQLITE_OK; }else{ //重复直到获得锁 do { rc = sqlite3OsLock(pPager->fd, locktype); }while( rc==SQLITE_BUSY && sqlite3InvokeBusyHandler(pPager->pBusyHandler) ); if( rc==SQLITE_OK ){ //设置pager的状态 pPager->state = locktype; } } return rc; }
Windows下具体的实现如下:
static int winLock(OsFile *id, int locktype){ int rc = SQLITE_OK; /* Return code from subroutines */ int res = 1; /* Result of a windows lock call */ int newLocktype; /* Set id->locktype to this value before exiting */ int gotPendingLock = 0;/* True if we acquired a PENDING lock this time */ winFile *pFile = (winFile*)id; assert( pFile!=0 ); TRACE5("LOCK %d %d was %d(%d) ", pFile->h, locktype, pFile->locktype, pFile->sharedLockByte); /* If there is already a lock of this type or more restrictive on the ** OsFile, do nothing. Don't use the end_lock: exit path, as ** sqlite3OsEnterMutex() hasn't been called yet. */ //当前的锁>=locktype,则返回 if( pFile->locktype>=locktype ){ return SQLITE_OK; } /* Make sure the locking sequence is correct */ assert( pFile->locktype!=NO_LOCK || locktype==SHARED_LOCK ); assert( locktype!=PENDING_LOCK ); assert( locktype!=RESERVED_LOCK || pFile->locktype==SHARED_LOCK ); /* Lock the PENDING_LOCK byte if we need to acquire a PENDING lock or ** a SHARED lock. If we are acquiring a SHARED lock, the acquisition of ** the PENDING_LOCK byte is temporary. */ newLocktype = pFile->locktype; /*两种情况: (1)如果当前文件处于无锁状态(获取读锁--读事务 **和写事务在最初阶段都要经历的阶段), **(2)处于RESERVED_LOCK,且请求的锁为EXCLUSIVE_LOCK(写事务) **则对执行加PENDING_LOCK */ /////////////////////(1)/////////////////// if( pFile->locktype==NO_LOCK || (locktype==EXCLUSIVE_LOCK && pFile->locktype==RESERVED_LOCK) ){ int cnt = 3; //加pending锁 while( cnt-->0 && (res = LockFile(pFile->h, PENDING_BYTE, 0, 1, 0))==0 ){ /* Try 3 times to get the pending lock. The pending lock might be ** held by another reader process who will release it momentarily. */ TRACE2("could not get a PENDING lock. cnt=%d ", cnt); Sleep(1); } //设置为gotPendingLock为1,使和在后面要释放PENDING锁 gotPendingLock = res; } /* Acquire a shared lock */ /*获取shared lock **此时,事务应该持有PENDING锁,而PENDING锁作为事务从UNLOCKED到 **SHARED_LOCKED的一个过渡,所以事务由PENDING->SHARED **此时,实际上锁处于两个状态:PENDING和SHARED, **直到后面释放PENDING锁后,才真正处于SHARED状态 */ ////////////////(2)///////////////////////////////////// if( locktype==SHARED_LOCK && res ){ assert( pFile->locktype==NO_LOCK ); res = getReadLock(pFile); if( res ){ newLocktype = SHARED_LOCK; } } /* Acquire a RESERVED lock */ /*获取RESERVED **此时事务持有SHARED_LOCK,变化过程为SHARED->RESERVED。 **RESERVED锁的作用就是为了提高系统的并发性能 */ ////////////////////////(3)///////////////////////////////// if( locktype==RESERVED_LOCK && res ){ assert( pFile->locktype==SHARED_LOCK ); //加RESERVED锁 res = LockFile(pFile->h, RESERVED_BYTE, 0, 1, 0); if( res ){ newLocktype = RESERVED_LOCK; } } /* Acquire a PENDING lock */ /*获取PENDING锁 **此时事务持有RESERVED_LOCK,且事务申请EXCLUSIVE_LOCK **变化过程为:RESERVED->PENDING。 **PENDING状态只是唯一的作用就是防止写饿死. **读事务不会执行该代码,但是写事务会执行该代码, **执行该代码后gotPendingLock设为0,后面就不会释放PENDING锁。 */ //////////////////////////////(4)//////////////////////////////// if( locktype==EXCLUSIVE_LOCK && res ){ //这里没有实际的加锁操作,只是把锁的状态改为PENDING状态 newLocktype = PENDING_LOCK; //设置了gotPendingLock,后面就不会释放PENDING锁了, //相当于加了PENDING锁,实际上是在开始处加的PENDING锁 gotPendingLock = 0; } /* Acquire an EXCLUSIVE lock */ /*获取EXCLUSIVE锁 **当一个事务执行该代码时,它应该满足以下条件: **(1)锁的状态为:PENDING (2)是一个写事务 **变化过程:PENDING->EXCLUSIVE */ /////////////////////////(5)/////////////////////////////////////////// if( locktype==EXCLUSIVE_LOCK && res ){ assert( pFile->locktype>=SHARED_LOCK ); res = unlockReadLock(pFile); TRACE2("unreadlock = %d ", res); res = LockFile(pFile->h, SHARED_FIRST, 0, SHARED_SIZE, 0); if( res ){ newLocktype = EXCLUSIVE_LOCK; }else{ TRACE2("error-code = %d ", GetLastError()); } } /* If we are holding a PENDING lock that ought to be released, then ** release it now. */ /*此时事务在第2步中获得PENDING锁,它将申请SHARED_LOCK(第3步,和图形相对照), **而在之前它已经获取了PENDING锁, **所以在这里它需要释放PENDING锁,此时锁的变化为:PENDING->SHARED */ //////////////////////////(6)///////////////////////////////////// if( gotPendingLock && locktype==SHARED_LOCK ){ UnlockFile(pFile->h, PENDING_BYTE, 0, 1, 0); } /* Update the state of the lock has held in the file descriptor then ** return the appropriate result code. */ if( res ){ rc = SQLITE_OK; }else{ TRACE4("LOCK FAILED %d trying for %d but got %d ", pFile->h, locktype, newLocktype); rc = SQLITE_BUSY; } //在这里设置文件锁的状态 pFile->locktype = newLocktype; return rc; }
在几个关键的部位标记数字。
(I)对于一个读事务会的完整经过:
语句序列:(1)——>(2)——>(6)
相应的状态真正的变化过程为:UNLOCKED→PENDING(1)→PENDING、SHARED(2)→SHARED(6)→UNLOCKED
(II)对于一个写事务完整经过:
第一阶段:
语句序列:(1)——>(2)——>(6)
状态变化:UNLOCKED→PENDING(1)→PENDING、SHARED(2)→SHARED(6)。此时事务获得SHARED LOCK。
第二个阶段:
语句序列:(3)
此时事务获得RESERVED LOCK。
第三个阶段:
事务执行修改操作。
第四个阶段:
语句序列:(1)——>(4)——>(5)
状态变化为:
RESERVED→ RESERVED 、PENDING(1)→PENDING(4)→EXCLUSIVE(5)。此时事务获得排斥锁,就可以进行写磁盘操作了。
注:在上面的过程中,由于(1)的执行,使得某些时刻SQLite处于两种状态,但它持续的时间很短,从某种程度上来说可以忽略,但是为了把问题说清楚,在这里描述了这一微妙而巧妙的过程。
4、SQLite的死锁问题
SQLite的加锁机制会不会出现死锁?
这是一个很有意思的问题,对于任何采取加锁作为并发控制机制的DBMS都得考虑这个问题。有两种方式处理死锁问题:(1)死锁预防(deadlock prevention)(2)死锁检测(deadlock detection)与死锁恢复(deadlock recovery)。SQLite采取了第一种方式,如果一个事务不能获取锁,它会重试有限次(这个重试次数可以由应用程序运行预先设置,默认为1次)——这实际上是基本锁超时的机制。如果还是不能获取锁,SQLite返回SQLITE_BUSY错误给应用程序,应用程序此时应该中断,之后再重试;或者中止当前事务。虽然基于锁超时的机制简单,容易实现,但是它的缺点也是明显的——资源浪费。
5、事务类型(Transaction Types)
既然SQLite采取了这种机制,所以应用程序得处理SQLITE_BUSY错误,先来看一个会产生SQLITE_BUSY错误的例子:

所以应用程序应该尽量避免产生死锁,那么应用程序如何做可以避免死锁的产生呢?
答案就是为你的程序选择正确合适的事务类型。
SQLite有三种不同的事务类型,这不同于锁的状态。事务可以从DEFERRED、IMMEDIATE或者EXCLUSIVE,一个事务的类型在BEGIN命令中指定:
BEGIN [ DEFERRED | IMMEDIATE | EXCLUSIVE ] TRANSACTION;
一个deferred事务不获取任何锁,直到它需要锁的时候,而且BEGIN语句本身也不会做什么事情——它开始于UNLOCK状态;默认情况下是这样的。如果仅仅用BEGIN开始一个事务,那么事务就是DEFERRED的,同时它不会获取任何锁,当对数据库进行第一次读操作时,它会获取SHARED LOCK;同样,当进行第一次写操作时,它会获取RESERVED LOCK。
由BEGIN开始的Immediate事务会试着获取RESERVED LOCK。如果成功,BEGIN IMMEDIATE保证没有别的连接可以写数据库。但是,别的连接可以对数据库进行读操作,但是RESERVED LOCK会阻止其它的连接BEGIN IMMEDIATE或者BEGIN EXCLUSIVE命令,SQLite会返回SQLITE_BUSY错误。这时你就可以对数据库进行修改操作,但是你不能提交,当你COMMIT时,会返回SQLITE_BUSY错误,这意味着还有其它的读事务没有完成,得等它们执行完后才能提交事务。
Exclusive事务会试着获取对数据库的EXCLUSIVE锁。这与IMMEDIATE类似,但是一旦成功,EXCLUSIVE事务保证没有其它的连接,所以就可对数据库进行读写操作了。
上面那个例子的问题在于两个连接最终都想写数据库,但是他们都没有放弃各自原来的锁,最终,shared锁导致了问题的出现。如果两个连接都以BEGIN IMMEDIATE开始事务,那么死锁就不会发生。在这种情况下,在同一时刻只能有一个连接进入BEGIN IMMEDIATE,其它的连接就得等待。BEGIN IMMEDIATE和BEGIN EXCLUSIVE通常被写事务使用。就像同步机制一样,它防止了死锁的产生。
基本的准则是:如果你在使用的数据库没有其它的连接,用BEGIN就足够了。但是,如果你使用的数据库在其它的连接也要对数据库进行写操作,就得使用BEGIN IMMEDIATE或BEGIN EXCLUSIVE开始你的事务。