文章参考 菜鸟教程 相关内容
一、运算符
1:算数运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 30 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 200 |
| / | 除 - x除以y | b / a 输出结果 2 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 0 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的20次方, 输出结果 100000000000000000000 |
| // | 取整除 - 返回商的整数部分(向下取整) |
>>> 9//2
4
>>> -9//2
-5
|
2:成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |


name = """张三""" if "张" in name: print("OK") if "李" not in name: print("Not in") # 输出结果 # OK # Not in
3:比较运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False。 |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 true. |
| <> | 不等于 - 比较两个对象是否不相等。python3 已废弃。 | (a <> b) 返回 true。这个运算符类似 != 。 |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False。 |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。 | (a < b) 返回 true。 |
| >= | 大于等于 - 返回x是否大于等于y。 | (a >= b) 返回 False。 |
| <= | 小于等于 - 返回x是否小于等于y。 | (a <= b) 返回 true。 |
4:赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
5:逻辑运算符
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。 | (a and b) 返回 20。 |
| or | x or y | 布尔"或" - 如果 x 是非 0,它返回 x 的值,否则它返回 y 的计算值。 | (a or b) 返回 10。 |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
6:运算符优先级
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
7:练习题
-
判断1 > 1 and 3 < 4 or 9 > 5 and 2 > 1 and 9 > 8 or 7 < 6 的真假
分析:首先根据优先级(小括号>not>and>or)先计算(1 > 1 and 3 < 4)为False (9 > 5 and 2 > 1 and 9 > 8 )True。简化为:False or True or False 继续根据or一真则真。结果为True
-
判断 not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 8 的真假
分析:首先根据优先级(小括号>not>and>or)先计算(not 2 > 1)为False ,加上and 3 < 4仍是False。(4 > 5 and 2 > 1 and 9 > 8 ) False。简化为:False or False or True 根据or一真则真返前真。结果为True
快速分析:根据or的特点。a:逻辑运算符中优先级最低;b:一真则真。 直接观察最末尾的(7<8)。直接判定结果为True。
-
求 0 or 0 and 3 or 7 or 9 and 6 的值。
分析:首先根据优先级,计算 0 and 3 ,and 一假则假返前假 ,全真返后真 返回0。9 and 6 返回6。简化 0 or 0 or 7 or 6 ,or一真则真返前真。结果为7。
-
求 'Hello' and 'World and Python' or 9 and 6 的值。
分析:首先根据优先级化简: 'World and Python' or 6 。根据or的属性:一真则真返前真。结果为 'World and Python' 。
-
求 i =10;i += i-i-1 的值。
分析:首先根据优先级化简: 算数运算符 - 的优先级高于赋值运算符+=。(i-i-1)= -1,简化为 i+=(-1)。也就是 i = i -1 结果为 9
二、数据类型
1:基本数据类型
1.1 整数
1.1.1 类型转换
int([x]) -> integer
int(x, base=10) -> integer :base表示:N进制
1.1.2 当前数字的二进制至少用几位表示
bit_length()
strNum = "12" print(type(strNum),strNum) # 输出结果 <class 'str'> 12 num = int(strNum) print(type(num),num) # 输出结果 <class 'int'> 12 v = num.bit_length() print(v) # 输出结果 4
1.2 字符串 str
1.2.1 字符串常用的方法示例
strTest = "aaRon" v1 = strTest.capitalize(); #首字母大写 print(v1) # 输出结果 Aaron v2 = strTest.lower(); #变小写 print(v2) # 输出结果 aaron v3 = strTest.casefold();#变小写 更强大 print(v3) # 输出结果 aaron v4 = strTest.center(10,"中");#填充 print(v4) # 输出结果 中中aaRon中中中 v5 = strTest.count('r');#计算字符串出现个数,区分大小写 print(v5) # 输出结果 0 v6 = strTest.count('a',1);#计算字符串出现个数,从某个位置开始找 print(v6) # 输出结果 1 v7 = strTest.count('a',2,666);#计算字符串出现个数,从某个位置开始找 print(v7) # 输出结果 0 v8 = strTest.endswith("on");#以XX结尾 print(v8) # 输出结果 True v9 = strTest.endswith("a",0,2);#以XX结尾 区间应该是[0,2) print(v9) # 输出结果 True v10 = strTest.startswith("aa");#以XX开头 print(v10) # 输出结果 True v11 = strTest.startswith("R",2,6);#以XX开头 区间应该是[2,6) print(v11) # 输出结果 True v12 = strTest.find("o");#获取字节首次出现的位置 print(v12) # 输出结果 3 v13 = strTest.find("o",4,5);#获取字节首次出现的位置 print(v13) # 输出结果 -1 strTest2 ="I am {name}, I'm {age} years old";# format格式化 strTest3 ="I am {0}, I'm {1} years old";# format格式化 v14 = strTest2.format(name='Aaron',age=23); print(v14); # 输出结果I am Aaron, I'm 23 years old v15 = strTest3.format('Aaron',23); print(v15); # 输出结果I am Aaron, I'm 23 years old v16 = strTest2.format_map({"name":"Aaron","age":23}); print(v16); # 输出结果I am Aaron, I'm 23 years old # v17 = strTest.index('z'); # 此方法不好,容易报错,建议不使用,使用find替代 # print(v17); # 输出结果 报错了 strTest3 = "姓名 密码 备注 zhang三 zhangsanzhangsan 我的张三,职位管理员 李四 lisilisi 我的lisi,职位普通员工"; v18 = strTest3.expandtabs(20);# 制表符 print(v18);# 姓名 密码 备注 #zhang三 zhangsanzhangsan 我的张三,职位管理员 #李四 lisilisi 我的lisi,职位普通员工
strTest = "12a"; v1 = strTest.isidentifier();# 判断是否为标识符(字母、数字、下划线) print(v1);# 输出结果 False v2 = strTest.isalpha();# 判断是否为字符 print(v2);# 输出结果 False strTest = "as1"; v3 = strTest.isalpha();# 判断是否为字符 print(v3);# 输出结果 False v4 = strTest.isalnum();# 判断是否为数字 v5 = strTest.isdecimal();# 判断是否为数字 v6 = strTest.isdigit();# 判断是否为数字 print(v4,v5,v6);# 输出结果 True False False strTest = "②"; v4 = strTest.isalnum();# 判断是否为数字 v5 = strTest.isdecimal();# 判断是否为数字 v6 = strTest.isdigit();# 判断是否为数字 print(v4,v5,v6);# 输出结果 True False True strTest = "② 阿斯蒂芬"; v7 = strTest.isprintable();# 判断是否存在打印时不可显示的字符( 等特殊符号无法再print的时候直接输出) print(v7);# 输出结果 False strTest = " "; v8= strTest.isspace();# 判断是否存在空格 print(v8);# 输出结果 True strTest = " I Am not title "; v9= strTest.istitle();# 判断是否标题 print(v9);# 输出结果 False v9 = strTest.title(); print(v9);# 输出结果 I Am Not Title print(v9.istitle());# 输出结果 True ############重点#################### strTest = " I Am not title "; v10= "_".join(strTest);# 字符串拼接 print(v10);# 输出结果 _I_ _A_m_ _ _n_o_t_ _t_i_t_l_e_ strTest = "设置填充"; v11= strTest.center(20,'#');# 居中填充 print(v11);# 输出结果 ########设置填充######## v12= strTest.ljust(20,'#');# 文字居左填充 print(v12);# 输出结果 设置填充################ v13= strTest.rjust(20,'#');# 文字居右填充 print(v13);# 输出结果 ################设置填充 v14= strTest.zfill(20);# 文字居右填充,默认填充0 print(v14);# 输出结果 0000000000000000设置填充 strTest = "aaRon"; v15= strTest.islower();# 判断是否是小写 print(v15);# 输出结果 False v15 = strTest.lower();# 转换成小写 print(v15);# 输出结果 aaron v15= strTest.isupper();# 判断是否是大写 print(v15);# 输出结果 False v15 = strTest.upper();# 转换成大写 print(v15);# 输出结果 AArON v15 = strTest.swapcase();# 大小写互换 print(v15);# 输出结果 AARON strTest = " 去 空 格 "; v16= strTest.lstrip();# 去掉左空格,还能移除 等 print(v16);# 输出结果 去 空 格 v16= strTest.rstrip();# 去掉右空格 print(v16);# 输出结果 去 空 格 v16= strTest.strip();# 去掉左右空格 print(v16);# 输出结果 去 空 格 # 最大公共子序列 strTest = "iamaaron"; v17= strTest.strip("aabmdon");# 先进性最多匹配 print(v17);# 输出结果 iamaar #创建对应关系 多与translate() 方法连用 strTest = "ewsoifrjuifrasdfjas;dfwoireuwepru"; m=str.maketrans("aeiou","12345") v18 = strTest.translate(m); print(v18); #输出结果 2ws43frj53fr1sdfj1s;dfw43r25w2pr5 # 分割方法partition v19 = strTest.partition('a'); #以a分割,从左到右分割第一次出现a的位置 print(v19); #输出结果('ewsoifrjuifr', 'a', 'sdfjas;dfwoireuwepru') v19 = strTest.rpartition('a'); #以a分割,从右到左分割第一次出现a的位置 print(v19); #输出结果('ewsoifrjuifrasdfj', 'a', 's;dfwoireuwepru') # 分割方法 split v20 = strTest.split('a'); #分割后a元素不存在 print(v20); #输出结果 ['ewsoifrjuifr', 'sdfj', 's;dfwoireuwepru'] v20 = strTest.split('a',1); #分割后a元素不存在 print(v20); #输出结果 ['ewsoifrjuifr', 'sdfjas;dfwoireuwepru'] strTest = "ewsoifrjui frasdfj as;dfwoi reuwepru"; v20 = strTest.splitlines(True); #根据换行符分割 print(v20); #输出结果 ['ewsoifrjui ', ' ', 'frasdfj ', 'as;dfwoi ', 'reuwepru'] v20 = strTest.splitlines(False); #根据换行符分割 print(v20); #输出结果 ['ewsoifrjui', '', 'frasdfj', 'as;dfwoi', 'reuwepru']
strTest = "ads;lkjqwerj;sadfxczv"; v0 = strTest.replace("a","张三") print(v0); # 输出结果 张三ds;lkjqwerj;s张三dfxczv v1 = strTest[8]; print(v1); # 输出结果 w v1 = strTest[3:5]; #[3,5) print(v1); # 输出结果 ;l v1 = strTest[3:-1]; print(v1); # 输出结果 ;lkjqwerj;sadfxcz v2 = len(strTest); print(v2); # 输出结果 21 v = range(5) for item in v: print(item); # 输出结果 # 0 # 1 # 2 # 3 # 4 # 输出结果 v = range(0,5,2) for item in v: print(item); # 输出结果 # 0 # 2 # 4 # 输出结果
首先是切片的书写形式:[i : i+n : m] ;
i 是切片的起始索引值,为列表首位时可省略;i+n 是切片的结束位置,为列表末位时可省略;m 是步长,默认值是1,不允许为0 ,当m为负数时,列表翻转。
注意:这些值都可以大于列表长度,不会报越界。
切片的基本含义是:从序列的第i位索引起,向右取到后n位元素为止,按m间隔过滤 。
示例:“宁教我负天下人,不让天下人负我”。
下标 [0 1 2 3 4 5 6 7 8 9 10 11......14]
下标 [-15............-9 -8 -7 -6 -5 -4 -3 -2 -1]
正常截取:[1:6] ,表示从索引为1开始,截取到索引为6。注意区间为左闭右开。结果为教我负天下
下标为负数:[-5:-2] ,从右向左是负数,同样区间为左闭右开。结果为天下人
步长为负数:表示从右向左取[1:6:-1] 结果为空,意不意外。[6:1:-1]结果为人下天负我。
我们可以这样理解:步长未负数,表示倒着取,倒着去,开始索引必须大于结束索引值。
步长大于1表示:[1:6:3] 表示3个为一组,取第一个。结果为教天
我们仿造教学中的手势记忆。把其实索引想象成左手,终止索引想象成右手,手心之间表示取出的结果。如果是步长为负数表示右手为起始位置,左手为终止位置,然后再把得到的内容翻转。
1.2.3 通过切片操作对象
如果把切片放在赋值语句的左边,或把它作为 del 操作的对象,我们就可以对序列进行嫁 接、切除或就地修改操作。通过下面这几个例子,你应该就能体会到这些操作的强大功能:
li = list(range(10)) print(li) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 嫁接 li[2:5] = [10, 30] print(li) # [0, 1, 10, 30, 5, 6, 7, 8, 9] # 切除 del li[5:7] print(li) # [0, 1, 10, 30, 5, 8, 9] # 匹配替换 li[3::2] = [11,22] # 小心这种写法,如果匹配的个数与给定替换的个数不一致,会有问题: print(li) # [0, 1, 10, 11, 5, 22, 9] li[2:5]=[100] # 警惕这种写法,右侧必须是个可迭代对象 li[2:5]=100 会报错的 print(li) # [0, 1, 100, 22, 9]
1.2.4 字符串练习
1:输出"Hello,Python!"中有多少个大写字母,多少个小写字母,以及o出现的索引位置
st='Hello,Python!' upCount=0 #大写字母个数 lowCount=0 #小写字母个数 charCount=0#标点符号个数 oIndex="" # ,以及o出现的索引位置 currentIndex=0 for a in st: if a.islower(): lowCount+=1 elif a.isupper(): upCount+=1 if a=="o": oIndex+=str(currentIndex)+" " currentIndex+=1 resu =" 大写字母个数:{upCount}, 小写字母个数:{lowCount} ,标点符号个数:{charCount} o出现的索引位置:{oIndex}";# format格式化 resu=resu.format(upCount=upCount,lowCount=lowCount,charCount=charCount,oIndex=oIndex) print(resu)
总结:记忆方法(大小多少是开头,分分合合充结尾)
1.3 布尔值
对于int类型而言:0是False 非0是True
对于str类型而言:空字符串是False, 不空是True
1.4 列表 list
# list 列表 li=[1,12,19,"name",["张三",["18",21],"李四"],"Aaron",True]; #中括号扩起来,,分割.比C#和Java中强大 # 索引取值 print(li[3]); #输出结果 name # 修改某个元素 li[3]="修改后的内容"; print(li[3]); #输出结果 修改后的内容 li[1:3]=[120]; print(li);#[1, 120, '修改后的内容', ['张三', ['18', 21], '李四'], 'Aaron', True] print(li[3]); #输出结果 ['张三', ['18', 21], '李四'] print(li[3:-1]);#输出结果 ['修改后的内容', ['张三', ['18', 21], '李四'], 'Aaron'] # 删除 del li[3] del li[2:4] print(li); #[1, 120, True] v = 120 in li; print(v); #输出结果 True # 循环遍历 for item in li: print(item); #输出结果太多了,
# list 列表 li=[1,12,19,"name",["张三",["18",21],"李四"],"Aaron",True]; #中括号扩起来,,分割.比C#和Java中强大 # 索引取值 print(li[4][1][0][1]); #输出结果 8 #字符串转化成列表 lis=list("abc"); print(lis); #输出结果 ['a', 'b', 'c'] #列表转化成字符串 li = ["11","22","33","Aaron"]; strv = "".join(li); # 注意:列表中的数据只有字符串 print(strv); #输出结果 112233Aaron #列表添加 li.append(["55","66"]); print(li);#输出结果 ['11', '22', '33', 'Aaron', ['55', '66']] #浅拷贝 v = li.copy(); print(v); #输出结果 ['11', '22', '33', 'Aaron', ['55', '66']] #计算元素出现的次数 v1 = li.count("22"); print(v1); #输出结果 1 li.extend([55,"66",True]); #可迭代对象 print(li); #输出结果 ['11', '22', '33', 'Aaron', ['55', '66'], 55, '66', True] v2 = li.index(55); print(v2); #输出结果 5 ## 如果没有,可能会报错 #在指定位置插入数据 li.insert(3,["44",44]); print(li); #输出结果 ['11', '22', '33', ['44', 44], 'Aaron', ['55', '66'], 55, '66', True] #删除数据 v3=li.pop(); #删除末尾值,并将被删除的值返回 print(v3,li);#输出结果 True ['11', '22', '33', ['44', 44], 'Aaron', ['55', '66'], 55, '66'] v4=li.pop(4); #删除指定索引,并将被删除的值返回 print(v4,li);#输出结果 Aaron ['11', '22', '33', ['44', 44], ['55', '66'], 55, '66'] v5=li.remove('22'); print(v5,li);#输出结果 None ['11', '33', ['44', 44], ['55', '66'], 55, '66'] #v5=li.remove('2222'); 如果不存在,就会报错 #列表反转 li.reverse(); print(li); #输出结果 ['66', 55, ['55', '66'], ['44', 44], '33', '11'] li = [11,55,44,77,3,234,0] li.sort(); #仅能为数字 print(li);#输出结果 [0, 3, 11, 44, 55, 77, 234] #清空列表 li.clear(); print(li);#输出结果 []
1.5 元祖 tuple
# 元祖 tu = (111,"22",[33,(44,"55")],True,); # 元祖,第一级元素不可被修改,不能增加或者删除 # 索引 v = tu[0]; print(v); #输出结果 111 # 切片 v2=tu[1:-2]; print(v2); #输出结果 ('22',) # 转换 # 字符串转化成元祖 strTest= "abcd"; tu = tuple(strTest); print(tu); #输出结果 ('a', 'b', 'c', 'd') # 元祖转化成字符串 tu = ('a', 'b', 'c', 'd'); strTest="".join(tu); print(strTest); #输出结果 abcd # 统计某个值出现的次数 v3=tu.count('d'); print(v3); #输出结果 1 # 统计某个值首次出现的索引值 v4=tu.index('d'); print(v4); #输出结果 3
1.6 字典 dict
# 字典 info = { "k1":"value1", 2:22, True:True, (4,5):("44","55"), "list":[66,"77",(88,"99")], "dic":{ "dic1":1, "dic2":[2,3], } } #字典的key不能是:列表和字典 #字典的值可以是任何类型 # 字典是无序的 print(info); #输出结果 {'k1': 'value1', 2: 22, True: True, (4, 5): ('44', '55'), 'list': [66, '77', (88, '99')], 'dic': {'dic1': 1, 'dic2': [2, 3]}} print(info[True]); #输出结果 True print(info["dic"]["dic2"][1]);#输出结果 3 del info["dic"]["dic2"][1]; #删除 print(info); #输出结果 {'k1': 'value1', 2: 22, True: True, (4, 5): ('44', '55'), 'list': [66, '77', (88, '99')], 'dic': {'dic1': 1, 'dic2': [2]}} #循环 # 循环key for item in info.keys(): print(item); # 循环value print("--------------") for item in info.values(): print(item); # 循环所有 print("--------------") for k,v in info.items(): print(k,v); print("--------------") # 常用的方法 v=dict.fromkeys(["k1",123,"999"],"value12345"); print(v); #输出结果 {'k1': 'value12345', 123: 'value12345', '999': 'value12345'} #get v2 = info.get("k222","没有取到,就设置默认值") print(v2); #输出结果 没有取到,就设置默认值 #pop v3 = info.pop("k222","如果没有获取到,就返回默认值"); print(v3);#输出结果 如果没有获取到,就返回默认值 v4 = info.popitem(); #随机删除一个 print(v4,info);#输出结果 ('dic', {'dic1': 1, 'dic2': [2]}) {'k1': 'value1', 2: 22, True: True, (4, 5): ('44', '55'), 'list': [66, '77', (88, '99')]} #设置默认值 v5 = info.setdefault("k1","设置默认值,如果存在就不修改"); print(v5);#输出结果 value1 v6 = info.setdefault("k222222","设置默认值,如果Bu存在就添加"); print(v6);#输出结果 设置默认值,如果Bu存在就添加 dic ={"k1":"v1","k2":"v2"}; dic.update({"k1":"asdfasdf","k3":"asdfasdf"}); print(dic);#输出结果 {'k1': 'asdfasdf', 'k2': 'v2', 'k3': 'asdfasdf'} dic.update(k1="asdfasdf",k3="asdfasdf"); #另外一种写法 print(dic);#输出结果 {'k1': 'asdfasdf', 'k2': 'v2', 'k3': 'asdfasdf'}
dic1=[{"name":"张三","age":13},{"name":"李四","age":44},{"name":"王五","age":26},{"name":"赵六","age":6}]
dic1.sort(key=lambda x:x["age"]) # 注意排序没有返回值,是对其本身进行排序
print(dic1) # [{'name': '赵六', 'age': 6}, {'name': '张三', 'age': 13}, {'name': '王五', 'age': 26}, {'name': '李四', 'age': 44}]
1.7 集合
集合 :由不同元素组成的集合,无序排列的hash值,
set:可变集合; frozenset:不可变集合
#定义方法 set1= {1,2,2,"2"}; print(set1);#输出结果 {1, 2, '2'} set2= set([1,2,2,"2"]); #输入一个可迭代类型 print(set2);#输出结果 {1, 2, '2'} #添加单个元素 set2.add(3); print(set2);#输出结果 {1, 2, 3, '2'} #拷贝元素 set3=set2.copy(); print(set3);#输出结果 {1, 2, 3, '2'} #删除元素 set2.remove(3); #指定删除 如果不存在,就会报错 print(set2);#输出结果 {1, 2, '2'} set2.discard(3); #指定删除 如果不存在,也不会报错 print(set2);#输出结果 {1, 2, '2'} set2.pop(); #随机删除 print(set2);#输出结果 {2, '2'} #清空元素 set2.clear(); print(set2);#输出结果 set() set4 = {"张三","李四","王五",1,2} set5 = {"李四","王五","赵六",2,3} #求交集 set6=set4.intersection(set5); print(set6);#输出结果 {'李四', '王五', 2} set6=set4&set5; print(set6);#输出结果 {'李四', '王五', 2} #求并集 set6=set4.union(set5); print(set6);#输出结果 {1, 2, '赵六', '王五', '张三', 3, '李四'} set6=set4|set5; print(set6);#输出结果 {1, 2, '赵六', '王五', '张三', 3, '李四'} #求差集 set6=set4.difference(set5); print(set6);#输出结果 {1, '张三'} set6=set4-set5; print(set6);#输出结果 {1, '张三'} #求补集(并集-交集) set6=set4.symmetric_difference(set5); print(set6);#输出结果 {1, 3, '张三', '赵六'} set6=set4^set5; print(set6);#输出结果 {1, 3, '张三', '赵六'} #常用方法 #求完差集后更新 set4.difference_update(set5); #set4=set4-set5; print(set4); #输出结果 {1, '张三'} #判断是否有交集 var1=set4.isdisjoint(set5); print(var1); #输出结果 True set7 = {1,2,3}; set8 = {1,2}; #判断是否有是父集合(全包含) var1=set7.issuperset(set8); print(var1); #输出结果 True var1=set7.issubset(set8); print(var1); #输出结果 False #更新操作 set8.update(set7); print(set8); #输出结果 {1, 2, 3} #集合去重 lista =["张三","李四","李四",1,2,1]; lista = list(set(lista));#去重后顺序发生变化 print(lista); #输出结果 [2, 1, '李四', '张三']
格式化
msg = 'I am %s, my age is %d,my hobby is %s,I have %.2f 元' %('Yangke',12,["游泳","跑步"],12345678.15647897132) print(msg); #输出结果 I am Yangke, my age is 12,my hobby is ['游泳', '跑步'],I have 12345678.16 元 #打印百分比 tpl = "percent %.6f %%" % 12.214548; print(tpl);#输出结果 percent 12.214548 % #通过键值对 msg = 'I am %(name)s, my age is %(age)d,my hobby is %(hobby)s,I have %(money).2f 元' %{"name":'Yangke',"age":12,"hobby":["游泳","跑步"],"money":12345678.15647897132}; print(msg); #输出结果 I am Yangke, my age is 12,my hobby is ['游泳', '跑步'],I have 12345678.16 元 # sep: print("张三","李四","王五",sep=":");
msg = 'I am {}, my age is {},my hobby is {},I have {} 元' .format('Yangke',12,["游泳","跑步"],12345678.15647897132) print(msg); #输出结果 I am Yangke, my age is 12,my hobby is ['游泳', '跑步'],I have 12345678.156478971 元 msg = 'I am {3}, my age is {2},my hobby is {1},I have {0} 元' .format(12345678.15647897132,["游泳","跑步"],12,'Yangke') print(msg); #输出结果 I am Yangke, my age is 12,my hobby is ['游泳', '跑步'],I have 12345678.156478971 元 #通过键值对 msg = 'I am {name}, my age is {age},my hobby is {hobby},I have {money} 元' .format(name='Yangke',age=12,hobby=["游泳","跑步"],money=12345678.15647897132); print(msg); #输出结果 I am Yangke, my age is 12,my hobby is ['游泳', '跑步'],I have 12345678.156478971 元 #通过字典 msg = 'I am {name}, my age is {age},my hobby is {hobby},I have {money} 元' .format(**{"name":'Yangke',"age":12,"hobby":["游泳","跑步"],"money":12345678.15647897132}); print(msg); #输出结果 I am Yangke, my age is 12,my hobby is ['游泳', '跑步'],I have 12345678.156478971 元 #通过列表 msg = 'I am {:s}, my age is {:d},my hobby is {},I have {:.2f} 元' .format(*['Yangke',12,["游泳","跑步"],12345678.15647897132]); print(msg); #输出结果 I am Yangke, my age is 12,my hobby is ['游泳', '跑步'],I have 12345678.16 元
1.8 练习题:
#9*9乘法表 strResult = ""; for i in range(1,10): for j in range(1,10): if j<=i: formatResult="{0}*{1}={2}"; strResult += formatResult.format(j,i,i*j).center(10); print(strResult); strResult=""; 练习
# 百钱百鸡 # 公鸡:5 ,母鸡:3,小鸡:0.333 #公鸡0-20 母鸡:0-33 小鸡 0-100 for countG in range(0,100//5): for countM in range(0,100//3): countX = 100 - countG -countM; if (countG*5+countM*3+countX*1/3==100): print(countG,countM,countX); 百钱百鸡
userList =[]; for i in range(0,200): tempResult = {'name':"aaron"+str(i),"email":"aaron"+str(i)+"@live.com","pwd":"pwd"+str(i)}; userList.append(tempResult); while True: inp=input("请输入页码"); page=int(inp); currentPage = userList[(page-1)*10:page*10]; for item in currentPage: print(item);
# 首先,引入re,进行多字符串分割 # 其次,注意大小写统一 import re message = 'To be,or not to be:that is the question' wordlist = re.split(' |:|,', message.lower()) # 方法一:创建一个计数容器,自己算 countList={} for i in wordlist: if i in countList: countList[i]+=1 else: countList[i]=1 print(countList) # 方法二:利用字典设置默认值setdefault方法 countList2={} for i in wordlist: countList2.setdefault(i,0) countList2[i]=countList2[i]+1 print(countList2) #方法三:引用第三方空间 from collections import Counter count3= Counter(wordlist) print(count3)
小结
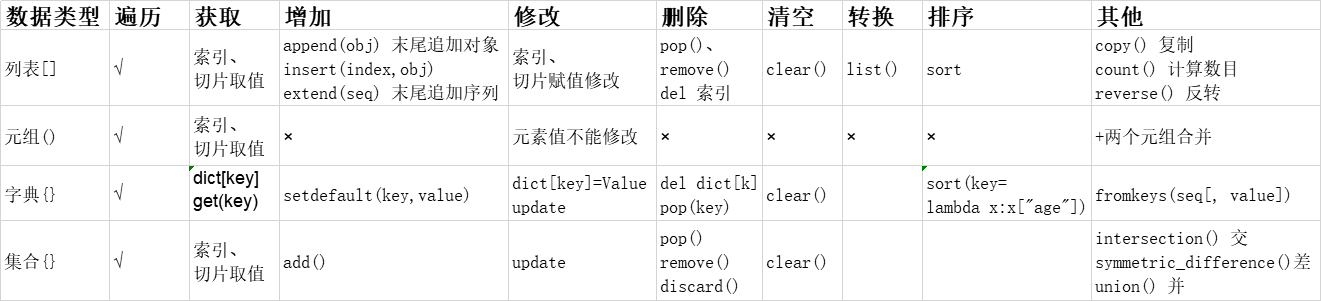
列表用[]; 元组用()可以看作是不可修改的列表。
字典用{};集合用{}可以看做是只有Key的字典。
2:可迭代对象
2.1 支持解包
#2.1 支持解包 a,b,c="123" #字符串 print(a,b,c) #输出结果 1 2 3 name, age, date = ['aaron', 20, '2020-02-02'] #列表 print(name, age, date) #输出结果 aaron 20 2020-02-02 zhangsan,lisi=('张三','李四') #元组 print(zhangsan,lisi) #输出结果 张三 李四 dict1,dict2={"k1":"v1","k2":"v2"} #字典 print(dict1,dict2) #输出结果 k1 k2 set1,set2={"s1","s1","s2"} #集合 print(set1,set2) #输出结果 k1 k2
还可以这种形式:* 尽可能多的匹配
a,*b,c="123456" #字符串
print(a,b,c) #输出结果 1 ['2', '3', '4', '5'] 6
2.2 尽量不要在迭代过程中删除数据。字典尽量在迭代过程中不要修改数据
原因:1 列表等可变的对象在迭代过程中删除索引会发生变化 2 元组: 不可变的列表.⼜被称为只读列表,不能被删除
mingZhu=["红楼梦","三国演义","水浒传","西游记"] for item in mingZhu: mingZhu.remove(item) print(mingZhu)
# 输出结果: ['三国演义', '西游记'] #原因分析:列表在迭代过程中可以想象成有一个索引下标 #["红楼梦","三国演义","水浒传","西游记"] # 0 1 2 3 #第一次循环 索引为0 删除mingZhu[0] 此时的结果 #["三国演义","水浒传","西游记"] # 0 1 2 #第二次循环 索引为1删除mingZhu[1] 此时的结果 #["三国演义","西游记"] # 0 1 #第三次循环 索引为2删除 大于列表长度,循环结束
真的不能删除吗?只要思想不滑坡,方法总比问题多。出现这种问题主要是自增过程中跳号。我们根据索引来倒叙删除就可以了
# for i in range(len(mingZhu),0,-1): # mingZhu.remove(mingZhu[i-1]) # print(mingZhu)
# # 字典也不能在循环的时候更改大小 # dic = {"a":"123", "b":"456"} # for k in dic: # dic.setdefault("c", "123") # #报错 dictionary changed size during iteration
2.3 赋值、深拷贝、浅拷贝
直接赋值:其实就是对象的引用(别名)。
浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
import copy a = 1 # 定义不可变数据类型 b=a # 直接赋值 c = copy.copy(a) # 浅拷贝 d = copy.deepcopy(a) # 深拷贝 print(a,b,c,d) #值相同 # 1 1 1 1 print(id(a),id(b),id(c),id(d)) # 内存地址相同 # 2059560032 2059560032 2059560032 2059560032 b=2 print(a,b,c,d) #值相同 # 1 2 1 1 print(id(a),id(b),id(c),id(d)) # 内存地址相同 # 2059560032 2059560048 2059560032 2059560032
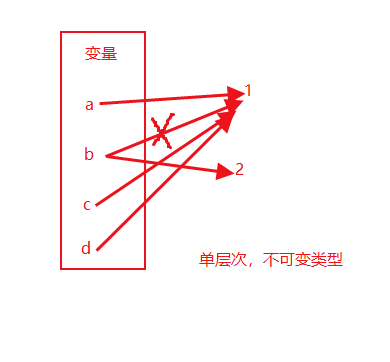 结论一:不可变类型,直接引用内存地址。
结论一:不可变类型,直接引用内存地址。
import copy a = [1,2] # 定义可变数据类型 b=a # 直接赋值 c = copy.copy(a) # 浅拷贝 d = copy.deepcopy(a) # 深拷贝 print(a,b,c,d) #值相同 # [1, 2] [1, 2] [1, 2] [1, 2] print(id(a),id(b),id(c),id(d)) # 内存地址相同 # 46329944 46329944 46329904 46330064 b.append(3) print(a,b,c,d) #值相同 # [1, 2, 3] [1, 2, 3] [1, 2] [1, 2] print(id(a),id(b),id(c),id(d)) # 内存地址相同 # 46329944 46329944 46329904 46330064
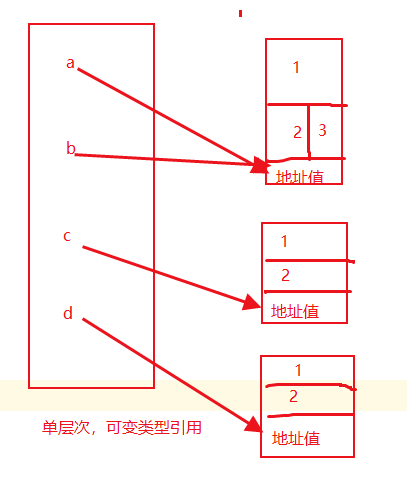
结论二:可变数据类型,不管深拷贝还是浅拷贝对可变数据类型都是会重新创建新的内存空间。
import copy a = ([1,2],(3,4)) # 不可变数据类型 b = a # 直接赋值 c = copy.copy(a) # 浅拷贝 d = copy.deepcopy(a) # 深拷贝 print(a,b,c,d) #值相同 ([1, 2], (3, 4)) ([1, 2], (3, 4)) ([1, 2], (3, 4)) ([1, 2], (3, 4)) print(id(a),id(b),id(c),id(d)) # 内存地址相同 # 18086568 18086568 18086568 18170784 b[0].append(33) print(a,b,c,d) #值相同 # ([1, 2, 33], (3, 4)) ([1, 2, 33], (3, 4)) ([1, 2, 33], (3, 4)) ([1, 2], (3, 4)) print(id(a),id(b),id(c),id(d)) # 内存地址相同 # 18086568 18086568 18086568 18170784
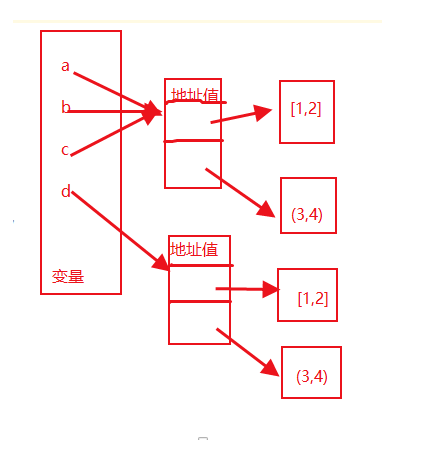
结论三: 外层是不可变类型,浅拷贝不会继续深层拷贝,会递归判断内层数据类型
import copy a = [[1,2],(3,4)] # 可变数据类型 b = a # 直接赋值 c = copy.copy(a) # 浅拷贝 d = copy.deepcopy(a) # 深拷贝 print(a,b,c,d) #值相同 #[[1, 2], (3, 4)] [[1, 2], (3, 4)] [[1, 2], (3, 4)] [[1, 2], (3, 4)] print(id(a),id(b),id(c),id(d)) # 内存地址相同 # 53227352 53227352 53276760 53277880 b[0].append(33) print(a,b,c,d) #值相同 # [[1, 2, 33], (3, 4)] [[1, 2, 33], (3, 4)] [[1, 2, 33], (3, 4)] [[1, 2], (3, 4)] print(id(a),id(b),id(c),id(d)) # 内存地址相同 # 53227352 53227352 53276760 53277880
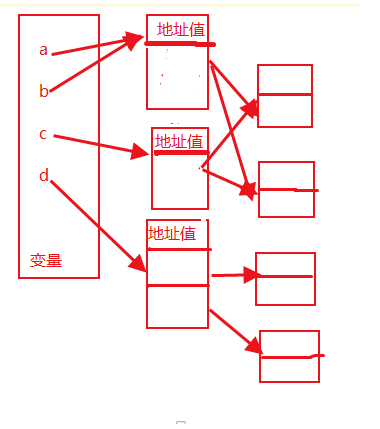
总结:直接赋值,紧跟时代潮流,与本体共进退。
浅拷贝,有一定的思想,不易欺骗。
深拷贝,实事求是,坚如磐石,