CPU和GPU之所以大不相同,是由于其设计目标的不同,它们分别针对了两种不同的应用场景。CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。
这些都使得CPU的内部结构异常复杂。而GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境。于是CPU和GPU就呈现出非常不同的架构(示意图):

GPU采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑并省去了Cache。而CPU不仅被Cache占据了大量空间,而且还有有复杂的控制逻辑和诸多优化电路,相比之下计算能力只是CPU很小的一部分。
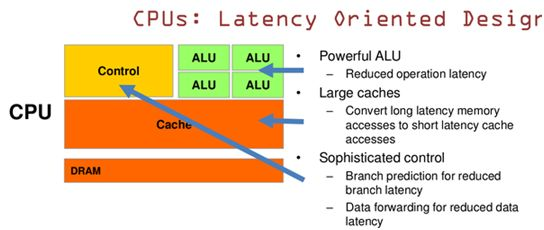
CPU 基于低延时的设计,CPU有强大的ALU(算术运算单元),它可以在很少的时钟周期内完成算术计算。
GPU是基于大的吞吐量设计:Cache比较小、控制单元简单,但GPU的核数很多,适合于并行高吞吐量运算。

总而言之,CPU和GPU因为最初用来处理的任务就不同,所以设计上有不小的区别。而某些任务和GPU最初用来解决的问题比较相似,所以用GPU来算了。
GPU的运算速度取决于雇了多少小学生,CPU的运算速度取决于请了多么厉害的教授。教授处理复杂任务的能力是碾压小学生的,但是对于没那么复杂的任务,还是顶不住人多。当然现在的GPU也能做一些稍微复杂的工作了,相当于升级成初中生高中生的水平。
但还需要CPU来把数据喂到嘴边才能开始干活,究竟还是靠CPU来管的。
OpenCL与CUDA的关系是什么?
-
虽然两者抱着相同的目标:通用并行计算。但是CUDA仅仅能够在NVIDIA的GPU硬件上运行,而OpenCL的目标是面向任何一种MassivelyParallel Processor,期望能够对不同种类的硬件给出一个相同的编程模型。
-
跨平台性和通用性。这一点上OpenCL占有很大优势(这也是很多National Laboratory使用OpenCL进行科学计算的最主要原因)。OpenCL支持包括ATI,NVIDIA,Intel,ARM在内的多类处理器,并能支持运行在CPU的并行代码,同时还独有Task-Parallel Execution Mode,能够更好的支持Heterogeneous Computing。这一点是仅仅支持数据级并行并仅能在NVIDIA众核处理器上运行的CUDA无法做到的。
-
CUDA和OpenCL的关系并不是冲突关系,而是包容关系。OpenCL是一个API,在第一个级别,CUDA架构是更高一个级别,在这个架构上不管是OpenCL还是DX11这样的API,还是像C语言、Fortran、DX11计算,都可以支持。
-
关于OpenCL与CUDA之间的技术区别,主要体现在实现方法上。基于C语言的CUDA被包装成一种容易编写的代码,因此即使是不熟悉芯片构造的科研人员,也可能利用CUDA工具编写出实用的程序。而OpenCL虽然句法上与CUDA接近,但是它更加强调底层操作,因此难度较高,但正因为如此,OpenCL才能跨平台运行。