重做
redo log,重做日志有两种,联机和归档(数据库事务的历史记录)
- 每个Oracle数据库至少有两个联机重做日志文件,循环使用,Oracle先往日志1写,写满专向日志2,写满转回日志文件1
- 归档重做文件日志文件只是复制旧的,写满了的联机重做日志文件
- 当系统写满日志文件时,ARCH进程会把联机重做日志文件复制到另一个位置
- 当硬盘出现故障或者物理损坏时,使用归档重做日志文件实现介质恢复
COMMIT
commit是一个非常快的操作,不管事务大小,commit响应时间通常是"平均的"
commit 1行花费x隔单位,commit 1000行同样花费x个单位,但是进行1000次commit一行的操作花费的是1000*x个单位
commit提交前做好的工作
- 在SGA中产生了回滚段(callback segment)记录
- 在SGA中产生了修改数据块
- 在SGA中产生了上面两条缓冲重做(undo)
- 取决于上面3项大小和消耗的时间,一部分数据可能已经刷新到硬盘上
- 已经获得所有的锁定
当commit时,所有剩下的工作
- 为事务产生一个系统改变号(System Change Number,SCN)
- LGWR把所有余下的缓冲区中的重做日志存储到硬盘上,并在联机重做日志文件中记录SCN(当前步骤即SCSN)
- 删除了事务条目,意味着已经提交了,在V$TRANSZCTION试图中的记录将消失
- 释放会话占用的所有锁定,释放在入队列等待中被占用锁定的每个事项
- 访问多个修改事务块,若它们仍在缓冲区高速缓存中,用快速模式访问和清除
执行commit只有很少的工作,时间最长的总是LGWR执行的操作,因为它是物理硬盘的IO
当操作进行时,LGWR连续刷新,至少:
- 每3秒
- 当满1/3或1MB
- 碰到任何事物commit
LGWR消耗的时间是由重做日志缓冲区已经释放的内容限定的
LGWR不会存储所有工作,当操作进行时,他将增加释放后台重做日志缓冲区中的内容,可以立即释放所有重做内容
在提交前,缓冲重做日志已经被放到硬盘上了,当commit时,必须等待
LGWR的调用是同步的事物要等待LGWR完全写完,收到的数据存在于硬盘上
SCN
是Oracle保证事务顺序并从失败中恢复的简单定时机制,SCN也能保证数据库一致读取性和检查点机制,类似计数器
回滚
ROLLBACK 必须物理上取消已完成的工作,在ROLLBACK之前已经完成了很多工作
- 已经在SGA产生了回滚段记录
- 已经在SGA产生了修改数据块
- 已经在SGA中产生了上面两条重做缓冲信息
- 取决于上面三项大小和消耗时间,一部分上面的数据可能已经刷新到硬盘上
- 已经获得所有锁定
当ROLLBACK时
撤销所有已做的修改,通过从ROLLBACK(undo)读取数据来完成,实际上是逆向操作
- 如果插入了一行,ROLLBACK删除它
- 如果更新了一行,ROLLBACK将逆向更新
- 如果删除了一行,回滚将重新插入它
释放会话占用的所有锁定,释放在队列中等待被占用锁定的每个事项
commit只是刷新保留在重做日志缓冲区中的数据,和ROLLBACK相比,做了非常少的工作
产生多少重做
重做管理是数据库中串行化的关键,在LGWR结果所有事务,要求它在它们的事务中管理重做和COMMIT
LGWR做的越多,系统越慢
使用动态性能试图V$MYSTAT,连接V$STATNAME,然后检索名为redo size的统计值,用V$STATNAME找到它
select * from v$statname;
阐述如何指定事务产生的重做量,知道要修改多少数据,可以直观估计要产生多少重做
对于AUTOTRACE追踪的语句(INSERT,UPDATE和DELETE),可以使用AUTOTRACE
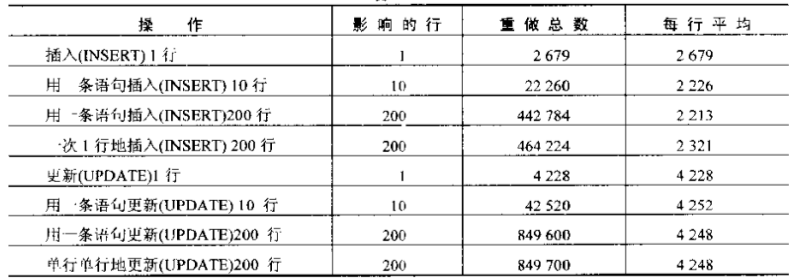

无论使用一条语句UPDATE200行,都产生相同数量的重做,对DELETE结果也一样,无论是一条语句还是200条语句
insert情况不太一样,对于单行插入产生的重做稍微多一些,当一行插入时,必须组织不同块中的数据,一次插入多行不是这样
产生的重做是修改数据量的函数,如果insert2000字节的行,每行产生的重做将会稍微多余2000字节
当update时,会产生两倍数量的重做(记录日志数据和回滚),DELETE的情况和INSERT情况相似,整个行记录在回滚段

BEFORE触发器即使不修改行中的任何值,也会增加额外的重做信息
使用上面的技术,会发现
- BEFORE或AFTER触发器不影响DELETE
- 对于BEFORE或AFTER触发器,INSERT产生同样多的额外重做信息
- UPDATE只受BEFORE触发器的影响,而AFTER触发器不增加额外重做信息
- 行的大小影响INSERT产生的额外重做信息的数量,不影响UPDATE
在UPDATE时,AFTER触发器对UPDATE更有效,它根本不影响重做的产生,当且仅当必须使用BEFORE触发器时才使用它
估计重做的量
- 估计"事务"的大小--需要修改多少数据
- 是否增加10%~20%的额外开销,取决于要修改的行数,行越多,额外开销越少
- 对UPDATE,此值加倍
为了保持索引结构,必须完成索的工作量从UPDATE到UPDATE可能是不同的,考虑触发器的缺点和代表性能的隐式操作
如何不让重做日志产生
redo log对数据库至关重要,某些sql语句和操作支持使用nologging,可以不产生redo log
当使用nologging操作
- 会产生一定数量的重做,用来保护数据字典,无法避免重做的产生,虽然可以比以前明显地少
- nologging不能防止后面的操作产生重做
- 在ARCHIVELOG模式的数据库中执行nologging操作之后,必须尽快备份受影响的数据文件,可以避免介质故障丢失对文件的修改
两种方式使用nologging
- 在sql命令中何时为止嵌入关键字nologging
- 在nologging模式中隐式执行
在ARCHIVELOG模式数据库中,适当使用NOLOGGING,可以通过大量减少产生的重做日志数量,加速许多操作
不能分配一个新日志
Sun Feb 25 10:59:55 2001
Thread 1 cannot allocate new log, sequence 326
Checkpoint not complete
被要求归档,而不是设置检查点没有完成
只要数据库试图重用联机重做日志文件,但是发现不行时,就把此消息写入服务器的alert.log文件
当DBWR没有完成检查重做日志保护的数据,或者ARCH没有把重做日志文件复制到归档为止,就会发生这种情况
当发现会话长时间等待,最可能碰到提示:
切换日志文件,日志缓冲区空间,或切换日志文件设置检查点或归档没有完成
块清除
数据锁定会影响存储在块头上的数据,缺点是当块写一次被访问时,必须“清除”它,换句话说,删除事务的信息
这么做会产生重做并且导致块变脏
如果主要是小到中等的事务(OLTP联机事务处理),或是在批量操作后分析表的数据仓库,一般会"清除"块
COMMIT时处理的一个步骤,重新访问SGA中的块;如果是可访问的,清除它们,称为"提交清除"
强制清除
Oracle分配块清单,这些块在事务相关的提交清单中修改过,每个块清单有20个块,Oracle根据需要尽可能多地分配
修改过的块总和超过了缓冲区高速缓存大小的10%,Oracle会停止分配新块
SELECT产生了重做,它还"弄脏"了这些修改过的块,导致DBWR再次写入它们,这是块清除的原因
在OLTP(联机事务处理)系统中,所有事务都是短半块,修改几块并全部清除
create table as select
直接路径装载数据,直接路径插入数据,都将创建''干净"的块
日志竞争
最大等待事件是;日志文件同步
正在经历重做日志竞争,它们运行得不够快,发生原因有很多种
- 一个应用程序提交频率太高,例如提交在循环中insert,
等待LGWR把重做日志缓冲刷新到硬盘上,LGWR可以在后台完成工作,不必等待
当COMMIT越频繁,等待越多,假定所有事务大小合适,导致日志文件等待的通常原因是
- 重做放到了运行慢的设备上,硬盘性能差,应该去购买更块的硬盘
- 把重做和其他文件放到了同一设备上,重做是设计用来在专用设备上大量连续写入,其他组件,试图作为LGWR同时在这台设备上读写,就会遇到一定程度竞争
- 用缓冲方式安装设备,使用一种成熟的文件系统,双倍的缓冲降低了运行速度
- 用慢的技术放置重做,例如RAID读取性能好,写入性能差,
需要至少5个专用设备创建日志,为了也能镜像归档文件,最好是6个,找出最小的,最快的,一两个大的硬盘
重做组1 -- 硬盘1和3
重做组2 -- 硬盘2和4
归档 -- 硬盘5和可选的硬盘6
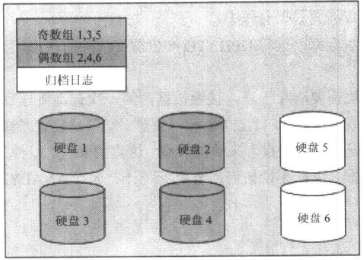
把成员A和B的第一组重做日志放到"组1",把成员C和D的第二组重做日志放到"组2",如果还有第3组和第4组,放到奇数组和偶数组硬盘上
LGWR将同时写入硬盘1和硬盘3,当这组写满时,LGWR将移到硬盘2和硬盘4
写满后,又返回重新写入硬盘1和硬盘3
同时ARCH处理全部联机重做日志
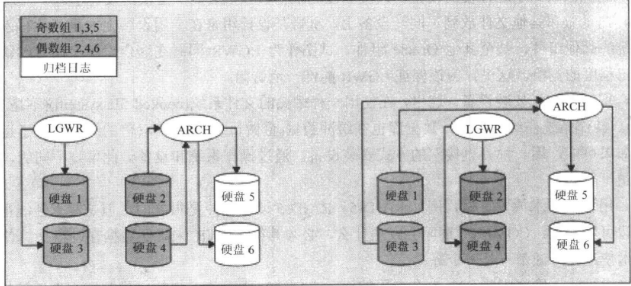
LGWR在网组1上写时,ARCH在读组2,同时往归档硬盘上写
当LGWR往组2上写时,ARCH在读组1,同时往归档硬盘上写,每个LGWR和ARCH都有自己专用的设备
它们不会竞争其他设备,也不会相互竞争
日志文件是最利于使用RAW硬盘的一组Oracle文件
临时表的重做和回滚
临时表不为它们的块产生重做,临时表上的操作是不能恢复的
当修改临时表中的块时,这种修改不会在重做日志文件中记录
然后临时表会产生回滚,回滚是记录到日志的,临时表会产生redo log
- INSERT产生很少甚至没有回滚/重做
- DELETE对临时表和对正常表产生同样多的重做
- UPDATE对临时表产生的重做只有UPDATE对正常表产生的重做的一半
避免删除临时表,因为如果产生回滚,DELETE的逆向操作INSERT是很麻烦的
可以使用TRUNCATE或者只是在COMMIT或会话结束后自动清空
分析重做
使用Logminer,在里面找到DELETE的OBJ$,查看表何时由于"事故"被删除,且希望DBA在DROP TABLE前刚刚保存
回滚
ORA-01555:snapshot too old 错误问题造成的混乱十分严重
什么产生最多/最少的撤销
- INSERT将产生最少数量的撤销,因为Oracle所要做的记录是"删除"行ID
- UPDATE第二位,记录修改过的字节,只要在撤销中记录行的一小部分
- DELETE产生最多的撤销,Oracle必须把整行的"前映像"记录到撤销段,等于将整个数据写入到回滚段
set transaction
选择事务要使用的回滚段,主要是为比较大的操作能够确保有大的回滚段
对于罕见的大更新,可以使用一次
大回滚段的一个问题是,不能阻止其他事务使用
没有办法使一个回滚段属于单个事务,如果执行许多信息的某种批量更新,使用这种特性比较好
在原来的地方把大表分区,然后执行并行更新
ORA-01555: Snapshot too old
- 对在系统上执行的工作,回滚段太小
- 程序产生交叉commit(是上面情况的一种变种)
- 块清除
前两点和Oracle的一致读模式直接相关,重复使用回滚段,既回滚失败的事务又提供一致读,导致了ORA-01555
第三点在只有一个会话的数据库中,这个会话没有修改这张表,会产生错误,未修改的表为什么产生回滚呢
- 分析相关对象,块清除是大量UPDATE或INSERT的结果
- 增多回滚段,可以降低当执行长时间查询时回滚数据被重写的可能性
- 降低查询的运行时间,降低对大回滚段的需要
事实上回滚段太小了
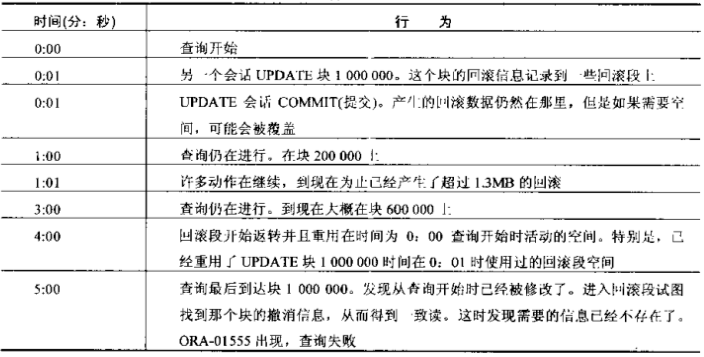
如果回滚段是确定大小的,那么在查询执行期间便于反转,并且查询访问的数据可能被修改可能再次遇到ORA-01555
必须去定回滚段的大小需要配置足够的回滚,适应长时间的查询需要
如果从查询开始的回滚都没有重写,就可以避免ORA-01555
产生ORA-01555,是由系统最小回滚段确定的,平均容量的回滚段,最大和最小是一样的,但也有风险,最好的做法是为装载工作估计合理的使用空间
交叉提交
交叉提交也可能产生ORA-01555错误,可以通过commit x 行降低回滚空间,但是系统变慢,产生更多的undo和redo,必然导致ORA-01555
最合适的配置方法,为系统配置一个合适大小的回滚段
延迟块清除
Oracle确定前面事务使用的回滚段(block header),确定块头是否指出前一事务的提交状态
为了得到由于推迟块清除产生的ORA-10555,必须满足以下条件
已经修改并commit,块依旧没有自动清除,超过的块超过了能适应SGA块缓冲区高速缓冲的10%