elasticsearch安装ik分词器插件
分词∶即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
IK提供了两个分词算法:ik_ smart:最少切分、ik_max_word:最细粒度划分
安装ik分词器插件
- github下载ik分词器插件压缩包,跟elasticsearch版本保持一致
- 在elasticsearch目录下的plugins文件夹里新建文件夹,用来存放ik分词器插件
- 将ik分词器压缩包解压到新建的文件夹中
- 重启elasticsearch服务
- 查看是否加载ik分词器插件
D:javaeselasticsearch-7.11.2-windows-x86_64elasticsearch-7.11.2in>elasticsearch-plugin list
Future versions of Elasticsearch will require Java 11; your Java version from [D:javajdkjre] does not meet this requirement. Consider switching to a distribution of Elasticsearch with a bundled JDK. If you are already using a distribution with a bundled JDK, ensure the JAVA_HOME environment variable is not set.
ik
打开kibana测试
ik_ smart:最少切分
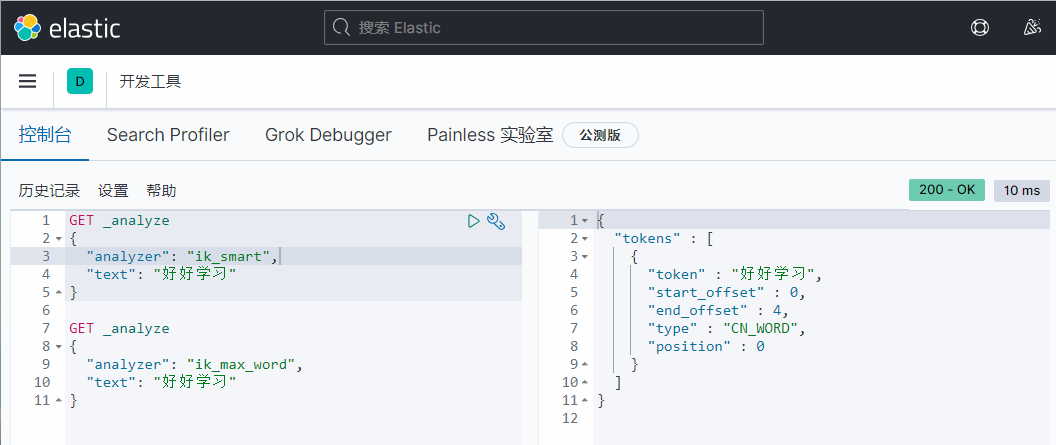
ik_max_word:最细粒度划分(穷尽词库的可能)
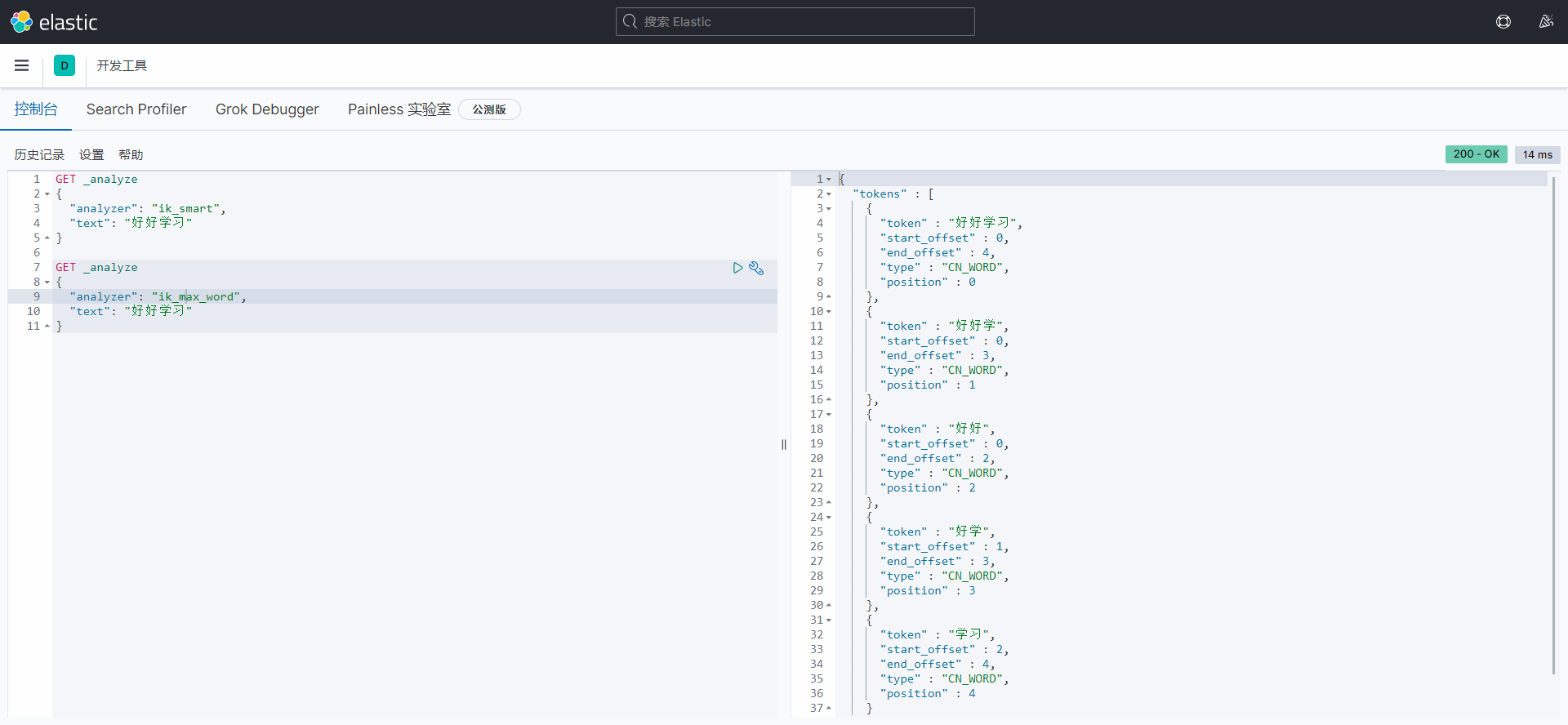
ik分词器分的词可能达不到我们的需求,所以我们可以将自己需要的词加到分词器的字典中,在ik分词器中增加自己的配置
- 在ik分词器插件的config目录下新建dic文件(dic文件就是字典),eg:yl.dic
- 将自己需要的词添加到dic文件中
- 打开IKAnalyzer.cfg.xml配置文件配置自己的字典
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">yl.dic</entry>
- 重启es服务以及kibana服务即可