urllib模块提供的urlretrieve()函数,urlretrieve()方法直接将远程的数据下载到本地
注意:若是网站有反爬虫的话这个函数会返回 403 Forbidden
参数url:传入的网址,网址必须得是个字符串
参数filename:指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
参数reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
参数data:指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。
下面例子将表情包下载到本地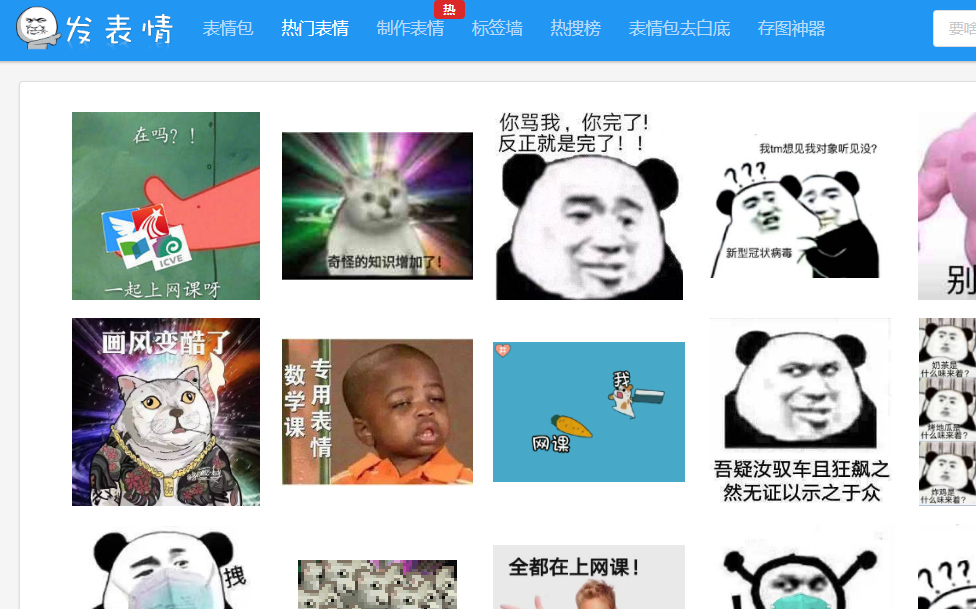
import requests
from lxml import etree
from urllib import request
import os
import re
def page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'
}
res = requests.get(url,headers=headers)
text = res.text
html = etree.HTML(text)
imgs = html.xpath("//div[@class='tagbqppdiv']//img")
for img in imgs:
img_url = img.get('data-original')
alt =img.get('alt')
sufixx = os.path.splitext(img_url)[1]#切割文件后缀名
alt = re.sub(r'[??.。!!]',"",alt)
filename = alt + sufixx
request.urlretrieve(img_url,r"F:paconghr classxpathimages\"+filename)
# print(etree.tostring(img))
# imgs = html.xpath("//div[@class='page-content text-center']//@href")#取出所有href里的链接
#print(text)
def main():
for i in range(1,101):
url = 'https://www.fabiaoqing.com/biaoqing/lists/page/%d.html'%i
page(url)
break
if __name__ == '__main__':
main()
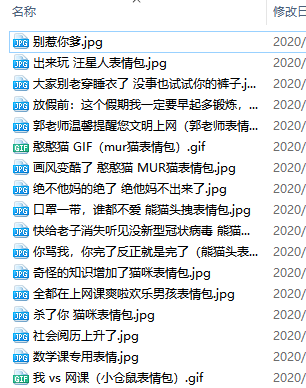
运行结果: