配置详情:
操作系统:centos7.6
Mysql:5.6
Mysql-master:192.168.198.130
Mysql-slave:192.168.198.133
一 主从复制方式
异步复制(Asynchronous replication)(默认)
MySQL 主服务器上I/O thread 线程将二进制日志写入binlog文件之后就返回客户端结果
不会考虑二进制日志是否完整传输到从服务器以及是否完整存放到从服务器上的relay日志中,这种模式一旦主服务(器)宕机,数据就会发生丢失
全同步复制(Fully synchronous replication)
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响
详见:https://www.cnblogs.com/JIAlinux/p/10893553.html
半同步复制(Semisynchronous replication)
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端
相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用
从MySQL5.5开始,MySQL以插件的形式支持半同步复制
详见:https://www.cnblogs.com/kevingrace/p/10228694.html
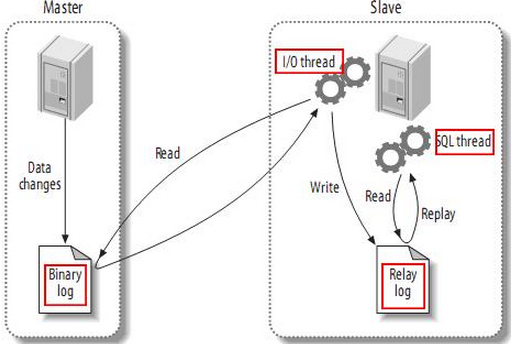
二 原理
主从复制是一种数据复制技术,是myslq数据库提供的一种高可用、高性能的解决方案
首先master开启二进制日志,将数据更新记录到二进制日志文件中
从slave start开始,slave通过I/O线程向master请求二进制日志文件,slave要知道向谁请求从哪个位置点请求
master接收到slave的I/O请求之后,就会从相应的位置点开始,给slave传日志
slave接收到日志后,会写入本地的中继日志中
slave通过sql线程读取中继日志中的内容,在数据库中执行相应的操作,到此为止,master和slave上的数据一致,之后slave服务器进入等待状态,等待master的后续更新
三 配置(传统模式)
master配置
修改配置文件
[root@localhost ~]# cp /etc/my.cnf /etc/my.cnf.bak [root@localhost ~]# vim /etc/my.cnf log-bin=binlog #开启二进制日志 server-id=1 #指定服务id(集群中每台服务器id不同)
#mysql同步的数据中是包含server-id的,而server-id用于标识该语句最初是从哪个server写入的,因此server-id一定要有的
#每一个同步中的slave在master上都对应一个master线程,该线程就是通过slave的server-id来标识的
#每个slave在master端最多有一个master线程,如果两个slave的server-id 相同,则后一个连接成功时,slave主动连接master之后,如果slave上面执行了slave stop
#则连接断开,但是master上对应的线程并没有退出;当slave start之后,master不能再创建一个线程而保留原来的线程,那样同步就可能有问题
#在mysql做主主同步时,多个主需要构成一个环状,但是同步的时候又要保证一条数据不会陷入死循环,这里就是靠server-id来实现的
启动服务
mysqld_safe &
登录数据库,授权一个实现复制数据的用户
mysql> grant replication slave on *.* to 'slave'@'192.168.198.133' identified by 'slave';
mysql> flush privileges; #刷新权限
验证slave是否能够登录(在slave上操作)
[root@localhost ~]# mysql -uslave -p -h 192.168.198.131
查看当前使用的二进制日志信息
mysql> show master statusG *************************** 1. row *************************** File: binlog.000001 Position: 412 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 1 row in set (0.00 sec)
slave配置
修改配置文件
[root@localhost ~]# cp /etc/my.cnf /etc/my.cnf.bak [root@localhost ~]# vim /etc/my.cnf server-id=2 #指定服务id(要与主服务器不一样)
启动服务
mysqld_safe &
登录数据库,请求同步
mysql> change master to master_host='192.168.198.131', #master ip -> master_port=3306, #master端口 -> master_user='slave', #连接master时所用的用户 -> master_password='slave', #密码 -> master_log_file='binlog.000001', #master现时所用的二进制日志文件 -> master_log_pos=412; #日志文件中的位置 mysql> start slave;
查看同步状态
mysql> show slave statusG

四 测试
在master上创建db1库,然后在slave上查看
mysql> create database db1; mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | db1 | | mysql | | performance_schema | | test | +--------------------+ 5 rows in set (0.04 sec)
五 注意:在同步前先确保主从服务器数据一致
克隆或新机器先全备,发送给从服务器写入,使两台机器一致
mysqldump -uroot -pyy123 -A > /tmp/mysql.sql scp /tmp/mysql.sql 192.168.198.133:/tmp/ mysql -uroot -pyy123 < mysql.sql
mysqldump -uroot -pyy123 -A --master-data > /tmp/mysql.sql
innobackupex --user=root --password=yy123 --slave-info /backup/
双主配置:主从配置完再配置主从(两台机器倒换)
六 主从延迟原因及解决方案
1 从服务器配置过低导致延迟
只读节点的数据为了和主节点保持同步,采用了MySQL binlog复制技术,由一个IO线程和一个SQL线程来完成,IO线程负责将主库的binlog拉取到只读节点,
SQL线程负责消费这些binlog日志,这两个线程会消耗掉只读节点的IO资源,所以当只读节点IOPS配置不够的时候,则会导致只读节点的数据出现延迟
解决方法:升级从服务器的配置,让只读节点的配置大于或者等于主节点的配置即可
2 主库的QPS(每秒查询数)过高导致只读节点延迟
由于只读节点与主库的同步采用的是单线程同步,而主库的压力是并发多线程写入,这样势必会导致只读节点的数据延迟
解决方法:开启只读节点的并行复制 (mysql5.6.3以后支持多线程复制)
3 主库的DDL语句导致只读节点延迟
可能1:只读节点与主库的DDL同步是串行进行的,如果DDL操作在主库执行时间很长,那么同样在备库也会消耗同样的时间
例:主库对一张500W的表添加一个字段耗费了10分钟,那么在只读节点上也同样会耗费10分钟,所以只读节点会延迟600S
可能2:只读节点上有一个执行时间非常长的的查询正在执行,那么这个查询会堵塞来自主库的DDL,读节点表被锁,直到查询结束为止,进而导致了只读节点的数据延迟
解决方法:对于可能1,只能说执行操作之前对可能带来的影响要有考量; 对于情况2,可以kill掉只读节点上的大查询进行,就可以恢复只读节点与主节点的数据同步
4 主库执行大事务导致延迟
主库执行了一条insert … select非常大的插入操作,该操作产生了近几百G的binlog文件传输到只读节点,进而导致了只读节点出现应用binlog延迟
解决办法: 将大事务拆分成为小事务进行排量提交,这样只读节点就可以迅速的完成事务的执行,不会造成数据的延迟
5 无主键的表进行DML操作导致延迟
由于表中没有主键,所以导致了每一个事务条目的更新都是全表扫描,如果表中很很多的数据,则备库执行该更新的事务条目的时候,就会出现很多的全表扫描更新
进一步说明就是,由于表中没有主键,在ROW模式下,每删一条数据都会做全表扫,也就是说一条delete,如果删了10条,会做10次全表扫,所以slave会一直卡住
解决办法: 每张表在设计的时候都加上一个主键
七 主从复制监控
在从服务器上执行show slave satusG, 与主从同步状态相关的参数
mysql> show slave statusG *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 192.168.198.131 Master_User: slave Master_Port: 3306 Connect_Retry: 60 Master_Log_File: binlog.000001 #SLAVE中的I/O线程当前正在请求的主服务器二进制日志文件的名称 Read_Master_Log_Pos: 503 #在当前的主服务器二进制日志中,SLAVE中的I/O线程已经读取的位置 Relay_Log_File: localhost-relay-bin.000002 #SQL线程当前正在读取和执行的中继日志文件的名称 Relay_Log_Pos: 371 #在当前的中继日志中,SQL线程已读取和执行的位置 Relay_Master_Log_File: binlog.000001 #由SQL线程执行的包含多数近期事件的主服务器二进制日志文件的名称 Slave_IO_Running: Yes #I/O线程是否启动并成功地连接到主服务器上 Slave_SQL_Running: Yes #SQL线程是否启动 Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 503 Relay_Log_Space: 548 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 #从属服务器SQL线程和从属服务器I/O线程之间的时间差距,单位以秒计。从库同步延迟情况出现的 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1 Master_UUID: b4afa401-3ae7-11eb-ada2-000c29db5617 Master_Info_File: /data/mysql/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 1 row in set (0.00 sec)
通常需要监控一下三个参数:
Slave_IO_Running:Yes 表示和主库连接正常并能实施复制工作,No则说明与主库通信异常
Slave_SQL_Running:YES 表示正常,NO表示执行失败,具体就是语句是否执行通过,常会遇到主键重复或是某个表不存在
Seconds_Behind_Master: 是通过比较sql_thread执行的event的ts和io_thread复制好的event的ts进行比较得到的值:
NULL — 表示io_thread或是sql_thread有任何一个发生故障,也就是该线程的Running状态是No,而非Yes
0 — 该值为零,是我们极为渴望看到的情况,表示主从复制良好
正值 — 表示主从已经出现延时,数字越大表示从库落后主库越多
负值 — 几乎很少见,这是一个BUG值,该参数是不支持负值的,也就是不应该出现
上面根据Seconds_Behind_Master的值来判断slave的延迟状态,这么做在大部分情况下尚可接受,但有时候是不够准确的
Seconds_Behind_Master:是通过比较sql_thread执行的event的timestamp和io_thread复制好的event的timestamp进行比较,而得到的这么一个差值
我们都知道的relay-log和主库的bin-log里面的内容完全一样,在记录sql语句的同时会被记录上当时的ts,所以比较参考的值来自于binlog
其实主从没有必要与NTP进行同步,也就是说无需保证主从时钟的一致.你也会发现,其实比较真正是发生在io_thread与sql_thread之间
而io_thread才真正与主库有关联,于是,问题就出来了, 当主库I/O负载很大或是网络阻塞,io_thread不能及时复制binlog(没有中断,也在复制)
而sql_thread一直都能跟上 io_thread的脚步,这时Seconds_Behind_Master的值是0,也就是我们认为的无延时,但是,实际上不是
这也就是为什么大家要批判用这个参数来监控数据库是否发生延时不准的原因
这个值并不是总是不准,如果当io_thread与master网络很好的情况下,那么该值也是很有价值的
较为准确的判断主从同步状态:
首先看 Relay_Master_Log_File 和 Master_Log_File 是否有差异;
如果Relay_Master_Log_File 和 Master_Log_File不一样,那说明存在延迟,需要从MASTER上取得binlog status,判断当前的binlog和MASTER上的差距
如果Relay_Master_Log_File 和 Master_Log_File一样,再看Exec_Master_Log_Pos 和 Read_Master_Log_Pos 的差异,对比SQL线程比IO线程慢了多少个binlog事件
故相对严谨的做法是:
对MASTER和slave同时发起SHOW BINARY LOGS和SHOW slave STATUSG的请求
判断二者binlog的差异,以及Exec_Master_Log_Pos 和Read_Master_Log_Pos 的差异