【数据结构】排序——外部排序(2)
上一章说到减少初始归并段数量或者是增大归并路数,都可以减少归并的趟数,进而减少磁盘的读写次数。
置换选择排序(生成初始归并段)
是在树形选择排序的基础上得来的的,特点是在整个排序的过程中,选择最小(或最大)关键字和输入、输出交叉或平行。
实现过程
FI:初始待排文件。FO:初始归并段输出文件。WA:内存工作区。FO和WA初始状态为空,WA可容纳w个记录
- 从FI输入w个记录到工作区WA
- 从WA中选出其中关键字取最小值得记录,极为MINMAX记录
- 将MINMAX记录输出到FO中去
- 若FI不为空,则从FI输入下一个记录到WA中
- 从WA中所有关键字必MINMAX记录的关键字大的记录中选出最小关键字记录,作为新的MINMAX记录
- 重复3-5,直至WA中选不出新的MINMAX记录为止,由此得到一个初始归并段,输出一个归并段的结束标志到FO中去
- 重复2-6,直至WA为空,由此得到全部初始归并段。
手动实现过程
eg、FI={17、21、05、44、10、12、56、32、29},WA=3。

其中WA区域中MINMAX记录选择是利用败者树完成。
最佳归并树
由置换选择生成树所得初始归并段,其各长短不等对平衡归并有什么影响?
若将初始归并段的长度看成是归并树中叶子结点的权,显然,归并方案不同,所得归并树也不同,树的带权路径长度(或外存读写次数)也不同。因此若对长度不同的多个初始归并段,构造一棵哈夫曼树作为归并树,便可以使在进行外部归并时所需对外存进行的读写次数达到最少,这棵归并树成为最佳归并树。
结构概述
各叶结点表示一个初始归并段,上面的权值表示该归并段的长度;叶结点到根的路径长度表示其参加归并的趟数;各非叶结点代表归并成的新归并段;根结点表示最终生成的归并段;树的带权路径长度WPL为归并过程中的总读记录数。
算法优化
引入哈夫曼树的思想,在归并树中,让记录少的初始归并段最先归并,记录数多的初始归并段最晚归并,就可以建立总的读写次数最少的最佳归并树。
eg、由置换选择排序得到的9个初始归并段,其长度依次为{9,30,12,18,3,17,2,6,24},现作3-路平衡归并

显然这不是最佳方案。
算法修正
若初始归并段不足以构成一棵严格k叉树时,则需要添加长度为0的“虚段”
按照哈夫曼树的原则,权为0的叶子应该离树根最远。
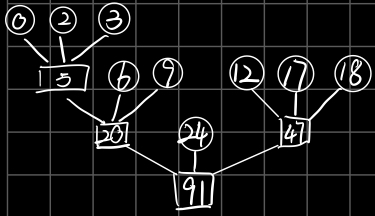
需要修正的条件
度为0的结点有n个,度为k的结点有m个。
严格k叉树有n=(k-1)m+1=>m=(n-1)/(k-1)
若(n-1)MOD(k-1)=0,则说明正好可以构造k叉归并树
若m=(n-1)MOD(k-1)=u(u不为0),则再加上k-u-1个空归并段就可以建立归并树。