车联网入侵检测技术
CAN总线数据异常检测分类
CAN总线数据异常检测方法主要分为基于统计方法、基于规则方法和基于机器学习方法。
-
基于统计的异常检测是通过统计大量的历史报文记录,捕获CAN数据流量,建立能够表达其随机行为的概要模型。原始的方法是基于单变量的概率模型,将其抽象为独立高斯变量而后发展出多变量模型,考虑多个变量之间的相关性,以及时间序列模型,分析数据随时间变化的规律。另外,有研究采用基于信息墒的异常检测方法,越有规律的数据集,其墒越小,而异常数据的墒较大,以此来找出异常点。基于统计的方法的优点是系统无需了解攻击的先验件,能够实时更新并检测出最新的攻击行为,并根据之前的数据获得用户的正常行为数据。其缺点是基于统计的方法高维数据检测性能较差,且对于异常阂值的设定会影响检测性能。
-
基于规则的方法是在已知先验知识的条件下,对正常数据和异常数据的模式进行人为划分,满足正常模式的数据即为正常数据。其中包括一种基于ASL的有限状态机方法,将所需编译的规则转换成打一展的有限状态自动机,以及专家系统的异常检测。基于规则的方法可以达到较好的分类效果,且鲁棒性较高,但是检测决策的过程异常复杂,检结论往往取决于专家的业务决策水平和能力,且需要耗费大量的人力。
-
基于机器学习方法是较为常用的异常检测技术,机器学习是使计算机能模拟人类的学习行为,通过学习获取新的知识和技能,并对已有的知识结构进行重新架构并完善性能的技术。
- 基于贝叶斯网络的方法,所需的参数较少,模拟不确定性的处理模型的效果较好,但是其网络特征变量是依据经验选取的,如果参数选取不当将造成较大的误检率。
- 基于神经网络模型的方法,神经网络是生物学上真实人类大脑神经网络的结构和功能及基本特性经过理论抽象、简化后构成的一种信息处理系统。基于神经网络的检测方法采用创建用户概要的方法,根据前期已知命令预测未知命令,以此判断是否出现人侵行为,将其应用于异常检测中具有自适应能力较强的优点,可进行并行处理且容错能力较强。
- 基于模糊理论的方法,模糊理论采用了滥用检测的优点,并没有严格的公式推导,而是一种符合人类思考方式的推导过程,常用于模式识别等场合。模糊理论在端口扫描和探测领域使用效果较好,但它的资源消耗较高。
- 基于遗传算法的方法是一种启发式搜索算法,下一代在性能上更优于上一代,反复迭代向着更优解的方向进化,提高了训练数据和检测数据性能,缺点是计算开销较大。基于密度的方法,典型的算法是局部异常因子(L OF)算法,它通过赋予待检测对象一个表示其异常程度因子的方式,得到该对象相对于其局部邻域的异常程度,其优点是可以检测出局部异常数据。
- 基于聚类的方法,典型的算法是K-means算法,它是一种基于样本间相似性度量的间接聚类方法,属于非监督学习方法。此外,还有一些其他的方法,诸如单分类支持向量机(One class SVM )孤立森林(Isolation Forest ) 等多种方法对于异常检测都有较好的性能。
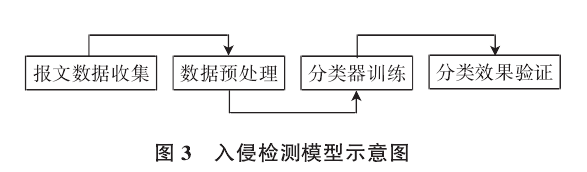
F1 车内CAN总线入侵检测算法研究_关亚东
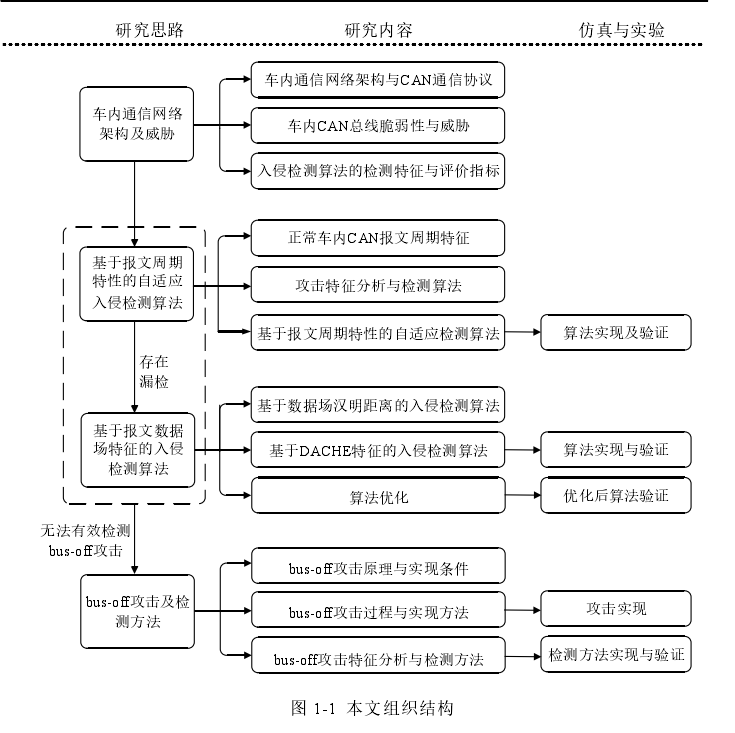
F2 机器学习在网络安全入侵检测中的应用_吴乔

F3 基于机器学习的车联网入侵检测技术的研究与实现_李宁宁
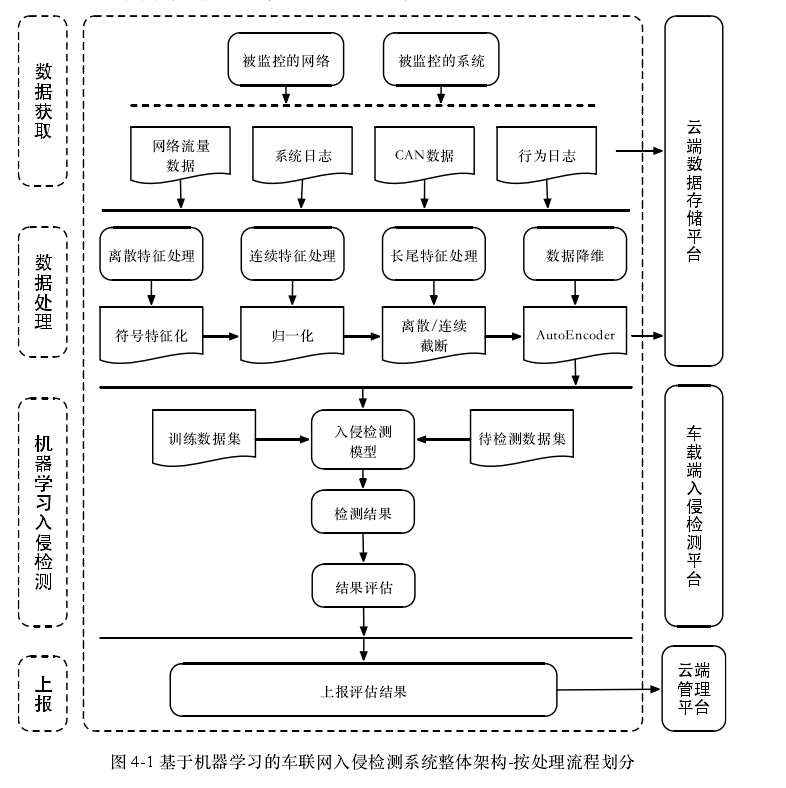
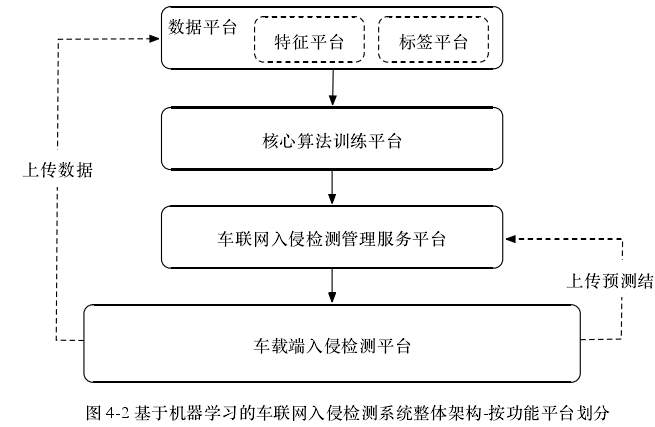
F4 基于机器学习的车载CAN网络入侵检测研究_谢浒
基于报文数据特征的CAN总线异常检测(常用)|
应用的三种机器学习算法:
- Adaboost
- KNN
- SVM