import torch import numpy from torch.utils.data import TensorDataset from troch.utils.data import DataLoader #TensorDataset将数据和标签封装到一起,再用DataLoader封装后即可在for中实现每次一个batch_size train = TensorDataset(train_x, train_y) train = DataLoader(train, batch_size = k, shuffle = True) test = TensorDataset(test_x, test_y) test = DataLoader(test, batch_size = k, shuffle = True) model = torch.nn.Sequential( torch.nn.Linear(128, 64), torch.nn.Sigmoid(), torch.nn.Linear(64, 10)) loss = torch.nn.MSELoss() optimizer = torch.optim.Adam() for i in range(100): for x, y in train: #model.train():训练时加上,会正常使用Batch Normalization 和 Dropout #model.eval():测试时加上,不会使用Batch Normalization 和 Dropout model.train() pred = model(x) loss_value = loss(pred, y) loss_value.backward() optimizer.step() for xt, yt in test: model.eval() test_pred = model(test_x) test_loss_value = loss(test_pred)
opencv读取视频
import cv2 import torch import torch.nn as nn import torch.nn.functional as F vc = cv2.VideoCapture('C:/Users/Dell/Downloads/2.mp4') if vc.isOpened(): flag, frame = vc.read() else: flag = False while(flag): gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) cv2.imshow('name', frame) if cv2.waitKey(10) & 0xFF == 27: break flag, frame = vc.read() vc.release() cv2.destroyAllWindows()
图像合并:
img1 = cv2.imread('C:/Users/Dell/Downloads/1.jpg') img2 = cv2.imread('C:/Users/Dell/Downloads/3.jpg') img1 = cv2.resize(img1, (700, 533)) #合并之前先调整到一致的大小 img = cv2.addWeighted(img1, 0.4, img2, 0.6, 0) #img = 0.4 * img1 + 0.6 * img2 + 0 cv2.imshow('img',img) cv2.waitKey(0) cv2.destroyAllWindows()
阈值处理:
img1 = cv2.imread('C:/Users/Dell/Downloads/1.jpg') img2 = cv2.imread('C:/Users/Dell/Downloads/3.jpg') ret, img = cv2.threshold(img1, 127, 255, cv2.THRESH_TOZERO_INV) cv2.imshow('img', img) if cv2.waitKey(0) & 0xFF == 27: cv2.destroyAllWindows()
import torch import torch.nn as nn import torch.nn.functional as F import cv2 import numpy as np img1 = cv2.imread('C:/Users/Dell/Downloads/1.jpg') img2 = cv2.imread('C:/Users/Dell/Downloads/3.jpg') #均值滤波,用3 * 3的权值为全1的卷积核做内积,将结果求均值 # img = cv2.blur(img1, (3, 3)) # cv2.imshow('img', img) #方框滤波,当normalize = True时,和均值滤波一样 #当normalize = False时,内积后不求平均,若超过255,则赋值为255 # img = cv2.boxFilter(img1, -1, (3, 3), normalize = False) # cv2.imshow('img', img) #高斯滤波:卷积核内的数值满足高斯分布,更重视中心位置,离中心越远重要性越低 # img = cv2.GaussianBlur(img, (5, 5), 1) # cv2.imshow('img', img) #中值滤波:用卷积核框起来的数中的中值代替 # img = cv2.medianBlur(img1, 5) # cv2.imshow('img', img) #将几张图片一起显示,注意img1和img2大小要相等,可以先resize img1 = cv2.resize(img1, (700, 533)) #合并之前先调整到一致的大小 res = np.hstack((img1, img2)) #横着一排 res = np.vstack((img1, img2)) #竖着一排 cv2.imshow('all', res) cv2.waitKey(0) cv2.destroyAllWindows()
腐蚀操作:
#腐蚀操作:在任意处画框,将在框内的边界内的点腐蚀,且此时框同时框住边界外和边界内 kernel = np.ones((3, 3), np.uint8) img = cv2.erode(img1, kernel, iterations = 1) #原图片,框的大小,迭代次数(腐蚀次数) = 1
膨胀操作:
img_dilate = cv2.dilate(img1, kernel, iterations = 1) #和腐蚀传入的参数一样
开运算和闭运算:
kernel = np.ones((5, 5), dtype = np.uint8) #开运算:先腐蚀,再膨胀 img_open = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel) #闭运算:先膨胀,再腐蚀 img_close = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel) cv2.imshow('img', img_open) cv2.waitKey(0) cv2.destroyAllWindows()
梯度运算:
#梯度运算:结果 = 膨胀 - 腐蚀 img_grad = cv2.morphologyEx(img, cv2.MORPH_GRADIENT, kernel)
礼帽和黑帽:
#礼帽:原始图像 - 开运算 img_tophat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel) #黑帽:闭运算 - 原始图像 img_blackhat = cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel)
Sobel算子求图像边缘:
分别为水平和垂直的卷积核,其中A为原始图像,Gx和Gy为替代3 * 3大小的中间值
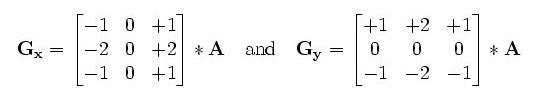
#Sobel算子:用于边缘检测(灰度值变化剧烈的地方就是边缘) #(原图像, 深度:-1表示与原图像深度相同, 水平, 垂直, 卷积核大小:为1 3 5 7) #水平和垂直不能同时为1,各自求完相加即可 #img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY) sobelx = cv2.Sobel(img1, -1, 1, 0, ksize = 3) #需要abs的原因为:3 * 3的kerbel为-1 0 1 内积时是左边减右边,若左边小,则结果就会为负值,而灰度值为0 - 255,因此取个绝对值 # -2 0 2 垂直时同理 # -1 0 1 sobelx = cv2.convertScaleAbs(sobelx) sobely = cv2.Sobel(img1, -1, 0, 1, ksize = 3) sobely = cv2.convertScaleAbs(sobely) sobel = cv2.addWeighted(sobelx, 0.5, sobely, 0.5, 0) cv2.imshow('sobelx', sobel) cv2.waitKey(0) cv2.destroyAllWindows()
Scharr算子:
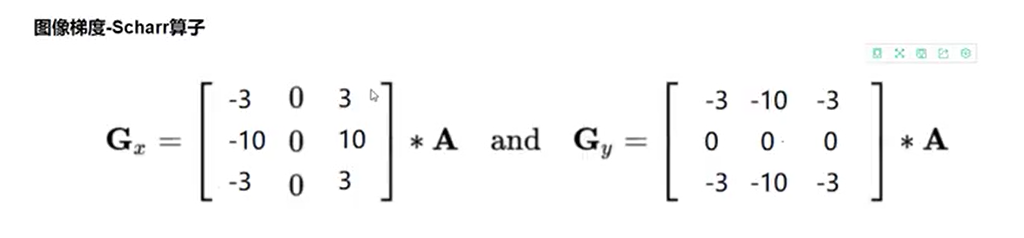
#Scharr算子:scharr与sobel算子思想一样,只是卷积核的系数不同, #提取边界也更加灵敏,能提取到更细小的边界,但请注意,越是灵敏就越是可能误判,卷积核默认3 * 3 scharrx = cv2.Scharr(img1, -1, 1, 0) scharry = cv2.Scharr(img1, -1, 0, 1) scharrx = cv2.convertScaleAbs(scharrx) scharry = cv2.convertScaleAbs(scharry) scharr = cv2.addWeighted(scharrx, 0.5, scharry, 0.5, 0) cv2.imshow('scharr', scharr) cv2.waitKey(0) cv2.destroyAllWindows()
Laplacian算子:
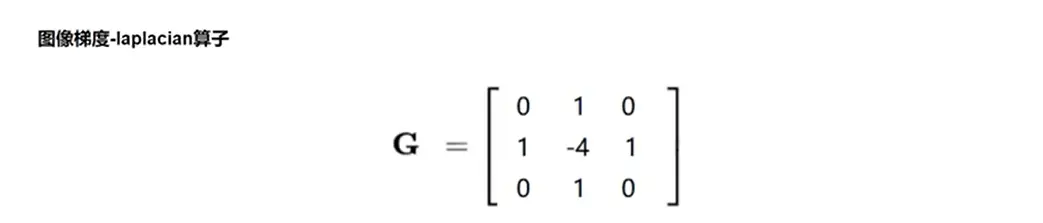
#Laplacian算子:没有水平和垂直之分 laplacian = cv2.Laplacian(img1, -1) cv2.imshow('laplacian', laplacian) cv2.waitKey(0) cv2.destroyAllWindows()
高斯金字塔:
向下采样(将图像变小):将图像与高斯内核卷积,之后将所有偶数行和列去掉
向上采样(放大):将图像在每个方向都扩大为原来的两倍,新增的行和列用0填充
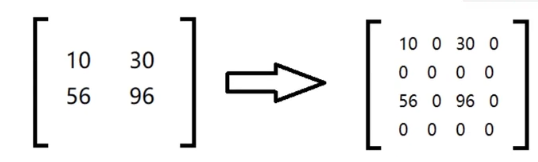
img_u = cv2.pyrUp(img1) img_d = cv2.pyrDown(img1) cv2.imshow('img', img_d)