转载自:https://blog.csdn.net/huachao1001/article/details/78501928
使用tensorflow过程中,训练结束后我们需要用到模型文件。有时候,我们可能也需要用到别人训练好的模型,并在这个基础上再次训练。这时候我们需要掌握如何操作这些模型数据。看完本文,相信你一定会有收获!
1 Tensorflow模型文件
我们在checkpoint_dir目录下保存的文件结构如下:
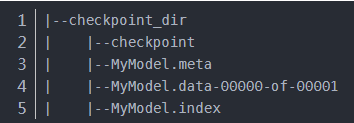
1.1 meta文件
MyModel.meta文件保存的是图结构,meta文件是pb(protocol buffer)格式文件,包含变量、op、集合等。
1.2 ckpt文件
ckpt文件是二进制文件,保存了所有的weights、biases、gradients等变量。在tensorflow 0.11之前,保存在**.ckpt**文件中。0.11后,通过两个文件保存,如:
1.3 checkpoint文件
我们还可以看,checkpoint_dir目录下还有checkpoint文件,该文件是个文本文件,里面记录了保存的最新的checkpoint文件以及其它checkpoint文件列表。在inference时,可以通过修改这个文件,指定使用哪个model
2 保存Tensorflow模型
tensorflow 提供了tf.train.Saver类来保存模型,值得注意的是,在tensorflow中,变量是存在于Session环境中,也就是说,只有在Session环境下才会存有变量值,因此,保存模型时需要传入session:
1 saver = tf.train.Saver() 2 saver.save(sess,"./checkpoint_dir/MyModel")
看一个简单例子:
1 import tensorflow as tf 2 3 w1 = tf.Variable(tf.random_normal(shape=[2]), name='w1') 4 w2 = tf.Variable(tf.random_normal(shape=[5]), name='w2') 5 saver = tf.train.Saver() 6 sess = tf.Session() 7 sess.run(tf.global_variables_initializer()) 8 saver.save(sess, './checkpoint_dir/MyModel')
执行后,在checkpoint_dir目录下创建模型文件如下:
1 checkpoint 2 MyModel.data-00000-of-00001 3 MyModel.index 4 MyModel.meta
另外,如果想要在1000次迭代后,再保存模型,只需设置global_step参数即可:
1 saver.save(sess, './checkpoint_dir/MyModel',global_step=1000)
保存的模型文件名称会在后面加-1000,如下:
1 checkpoint 2 MyModel-1000.data-00000-of-00001 3 MyModel-1000.index 4 MyModel-1000.meta
在实际训练中,我们可能会在每1000次迭代中保存一次模型数据,但是由于图是不变的,没必要每次都去保存,可以通过如下方式指定不保存图:
1 saver.save(sess, './checkpoint_dir/MyModel',global_step=step,write_meta_graph=False)
另一种比较实用的是,如果你希望每2小时保存一次模型,并且只保存最近的5个模型文件:
1 tf.train.Saver(max_to_keep=5, keep_checkpoint_every_n_hours=2)
注意:tensorflow默认只会保存最近的5个模型文件,如果你希望保存更多,可以通过max_to_keep来指定
如果我们不对tf.train.Saver指定任何参数,默认会保存所有变量。如果你不想保存所有变量,而只保存一部分变量,可以通过指定variables/collections。在创建tf.train.Saver实例时,通过将需要保存的变量构造list或者dictionary,传入到Saver中:
1 import tensorflow as tf 2 w1 = tf.Variable(tf.random_normal(shape=[2]), name='w1') 3 w2 = tf.Variable(tf.random_normal(shape=[5]), name='w2') 4 saver = tf.train.Saver([w1,w2]) #这定义了需要保存的参数 5 sess = tf.Session() 6 sess.run(tf.global_variables_initializer()) 7 saver.save(sess, './checkpoint_dir/MyModel',global_step=1000)
3 导入训练好的模型
在第1小节中我们介绍过,tensorflow将图和变量数据分开保存为不同的文件。因此,在导入模型时,也要分为2步:构造网络图和加载参数
3.1 构造网络图
一个比较笨的方法是,手敲代码,实现跟模型一模一样的图结构。其实,我们既然已经保存了图,那就没必要在去手写一次图结构代码。
1 saver=tf.train.import_meta_graph('./checkpoint_dir/MyModel-1000.meta')
上面一行代码,就把图加载进来了
3.2 加载参数
仅仅有图并没有用,更重要的是,我们需要前面训练好的模型参数(即weights、biases等),本文第2节提到过,变量值需要依赖于Session,因此在加载参数时,先要构造好Session:
1 import tensorflow as tf 2 with tf.Session() as sess: 3 new_saver = tf.train.import_meta_graph('./checkpoint_dir/MyModel-1000.meta') 4 new_saver.restore(sess, tf.train.latest_checkpoint('./checkpoint_dir'))
此时,W1和W2加载进了图,并且可以被访问:
1 import tensorflow as tf 2 with tf.Session() as sess: 3 saver = tf.train.import_meta_graph('./checkpoint_dir/MyModel-1000.meta') 4 saver.restore(sess,tf.train.latest_checkpoint('./checkpoint_dir')) 5 print(sess.run('w1:0'))
执行后,打印如下:[ 0.51480412 -0.56989086]
4 使用恢复的模型
前面我们理解了如何保存和恢复模型,很多时候,我们希望使用一些已经训练好的模型,如prediction、fine-tuning以及进一步训练等。这时候,我们可能需要获取训练好的模型中的一些中间结果值,
可以通过graph.get_tensor_by_name('w1:0')来获取,注意w1:0是tensor的name。
假设我们有一个简单的网络模型,代码如下:
1 import tensorflow as tf 2 3 4 w1 = tf.placeholder("float", name="w1") 5 w2 = tf.placeholder("float", name="w2") 6 b1= tf.Variable(2.0,name="bias") 7 8 #定义一个op,用于后面恢复 9 w3 = tf.add(w1,w2) 10 w4 = tf.multiply(w3,b1,name="op_to_restore") 11 sess = tf.Session() 12 sess.run(tf.global_variables_initializer()) 13 14 #创建一个Saver对象,用于保存所有变量 15 saver = tf.train.Saver() 16 17 #通过传入数据,执行op 18 print(sess.run(w4,feed_dict ={w1:4,w2:8})) 19 #打印 24.0 ==>(w1+w2)*b1 20 21 #现在保存模型 22 saver.save(sess, './checkpoint_dir/MyModel',global_step=1000)
接下来我们使用graph.get_tensor_by_name()方法来操纵这个保存的模型。
1 import tensorflow as tf 2 3 sess=tf.Session() 4 #先加载图和参数变量 5 saver = tf.train.import_meta_graph('./checkpoint_dir/MyModel-1000.meta') 6 saver.restore(sess, tf.train.latest_checkpoint('./checkpoint_dir')) 7 8 9 # 访问placeholders变量,并且创建feed-dict来作为placeholders的新值 10 graph = tf.get_default_graph() 11 w1 = graph.get_tensor_by_name("w1:0") 12 w2 = graph.get_tensor_by_name("w2:0") 13 feed_dict ={w1:13.0,w2:17.0} 14 15 #接下来,访问你想要执行的op 16 op_to_restore = graph.get_tensor_by_name("op_to_restore:0") 17 18 print(sess.run(op_to_restore,feed_dict)) 19 #打印结果为60.0==>(13+17)*2
如果你不仅仅是用训练好的模型,还要加入一些op,或者说加入一些layers并训练新的模型,可以通过一个简单例子来看如何操作:
1 import tensorflow as tf 2 3 sess = tf.Session() 4 # 先加载图和变量 5 saver = tf.train.import_meta_graph('my_test_model-1000.meta') 6 saver.restore(sess, tf.train.latest_checkpoint('./')) 7 8 # 访问placeholders变量,并且创建feed-dict来作为placeholders的新值 9 graph = tf.get_default_graph() 10 w1 = graph.get_tensor_by_name("w1:0") 11 w2 = graph.get_tensor_by_name("w2:0") 12 feed_dict = {w1: 13.0, w2: 17.0} 13 14 #接下来,访问你想要执行的op 15 op_to_restore = graph.get_tensor_by_name("op_to_restore:0") 16 17 # 在当前图中能够加入op 18 add_on_op = tf.multiply(op_to_restore, 2) 19 20 print (sess.run(add_on_op, feed_dict)) 21 # 打印120.0==>(13+17)*2*2
如果只想恢复图的一部分,并且再加入其它的op用于fine-tuning。只需通过graph.get_tensor_by_name()方法获取需要的op,并且在此基础上建立图,看一个简单例子,假设我们需要在训练好的VGG网络使用图,并且修改最后一层,将输出改为2,用于fine-tuning新数据:
1 ...... 2 ...... 3 saver = tf.train.import_meta_graph('vgg.meta') 4 # 访问图 5 graph = tf.get_default_graph() 6 7 #访问用于fine-tuning的output 8 fc7= graph.get_tensor_by_name('fc7:0') 9 10 #如果你想修改最后一层梯度,需要如下 11 fc7 = tf.stop_gradient(fc7) # It's an identity function 12 fc7_shape= fc7.get_shape().as_list() 13 14 new_outputs=2 15 weights = tf.Variable(tf.truncated_normal([fc7_shape[3], num_outputs], stddev=0.05)) 16 biases = tf.Variable(tf.constant(0.05, shape=[num_outputs])) 17 output = tf.matmul(fc7, weights) + biases 18 pred = tf.nn.softmax(output) 19 20 # Now, you run this with fine-tuning data in sess.run()