练习
目录
- 11.13
- 1.叠加装饰器的装饰顺序与执行顺序
- 2.什么是无参装饰器与有参装饰器
- 3.简述可迭代对象,迭代器对象及迭代取值方式,及for循环内部原理
- 4.迭代器对象的优缺点是什么?
- 5.写出一下func执行的结果
- 6.请实现一个装饰器,限制该函数被调用的频率,如10秒一次
- 11.18
- 2.什么是序列化?什么是反序列化?为什么要这么做?
- 3.什么是json与picjle的区别是什么?
- 4.ATM的登录与注册功能,用户数据用json数据保存。
- 5.写一个扑克牌随机发牌游戏
- 11.19 爬虫正则
- 11.25
- 1.面向对象编程的优缺点是什么?
- 2.对象的属性查找顺序是什么?
- 11.26
- 1.什么是继承?继承的目的?
- 2.python与期他语言的继承区别是什么?
- 3.如何寻找继承关系?
- 4.继承背景下对象属性的查找顺序是什么?
- 5.什么是派生?如何重用父类的属性并派生?两种方式
- 6.什么是新式类与经典类?
- 7.钻石继承下,经典类与新式类属性的查找顺序是什么?
- 8.下面这段代码的输出结果将是什么?请解释。
- 9.下述代码新式类与新式类的查找顺序是什么?
- 11.27
- 1.什么是组合?为什么要使用组合?
- 2.什么是封装?
- 3.什么是访问限制机制?
- 4.访问限制机制的优点?
- 5.什么是property?为什么要使用property?
- 6.练习题: 老师学生课程
11.13
1.叠加装饰器的装饰顺序与执行顺序
装饰顺序:从下往上(被装饰函数)
执行顺序:从上往上(python代码的执行顺序)
1.1无参装饰器模板:
def outter(func):
@wraps(func)
def inner(*args, **kwargs):
# 装饰前做的事
return func(*args, **kwargs)
# 装饰后做的事
retur inner
给函数添加测试运行时间的功能:
import time
from functools import wraps
def outter(func):
@wraps(func)
def inner(*args, **kwargs):
start_time = time.time()
res = func(*args, **kwargs)
end_time = time.time()
print(end_time-start_time)
return res
return inner
@outter
def time_func():
time.sleep(1)
time_func()
1.2有参装饰器
from functools import wraps
def wrappers(params1,params2,params3):
def outter(func):
@wraps(func)
def inner(*args, **kwargs):
# 装饰前做的事
return func(*args, **kwargs)
# 装饰后做的事
return inner
return outter
2.什么是无参装饰器与有参装饰器
无参装饰器:被装饰的函数不需要参数,两层
有参装饰器:被装饰的函数需要参数,三层
说白了,有参装饰器就是再无参装饰器的基础上又添加了一层包装,目的:添加一个参数。那么有没有可能四层、五层?答案是没必要。因为四层、五层就意味着传递了更多的参数,那么我们用三层就能达到效果。所有装饰器最多三层
3.简述可迭代对象,迭代器对象及迭代取值方式,及for循环内部原理
3.1迭代器
迭代器:迭代取值的工具 ——(用__iter__生成迭代器对象)
优点:1.不依赖与索引取值
2.内存中只占一份空间,不会内存溢出,节约空间,运行效率更高*(执行一次__next__取值一次,而不是一次全部取值)*
缺点:1.不能获取指定的元素
2.只能依次往后取值
3.2 迭代协议
class MyIter:
"""num传入 用来指定迭代次数 """
def __init__(self, num):
self.num = num
self.c = 0
# 迭代
def __iter__(self):
return self
# 取值
def __next__(self):
self.c += 1
if self.c <= self.num:
return "jeff"
else:
raise StopIteration
# 循环取值
for i in MyIter(10):
print(i)
3.2 for 循环内部原理
1、在遍历Foo的实例对象时,执行for...in...时,首先会先执行iter()方法,将此对象变为迭代器。
2、iter方法返回了一个迭代器对象,而后调用next()方法进行循环
4.迭代器对象的优缺点是什么?
优点:1.不依赖与索引取值
2.内存中只占一份空间,不会内存溢出,节约空间,运行效率更高*(执行一次__next__取值一次,而不是一次全部取值)*
缺点:1.不能获取指定的元素
2.只能依次往后取值
5.写出一下func执行的结果
def say_hi(func):
def wrapper(*args, **kwargs):
print("HI")
ret = func(*args, **kwargs)
print("BYE")
return re
return wrapper
def say_yo(func):
def wrapper(*args, **kwargs):
print("YO")
return func(*args, **kwargs)
return wrapper
@say_hi
@say_yo
def func():
print("Tank & Jason")
func()
#结果:
HI
YO
Tank & Jason
BYE
6.请实现一个装饰器,限制该函数被调用的频率,如10秒一次
import time
def outter(func):
def inner(*args, **kwargs):
print('开始调用函数。。。')
res = func(*args, **kwargs)
time.sleep(10)
print('函数调用结束。。。')
return res
return inner
@outter
def index():
print('函数正在执行中。。。')
index()
11.18
2.什么是序列化?什么是反序列化?为什么要这么做?
序列化:
序列:字符串
序列化:其他数据类型转成字符串的过程
序列化:其他数据类型转成字符串的过程
反序列化:字符串转成其他数据类型
注意:
写入文件的数据必须是字符串(二进制)
基于网络传输的数据必须是二进制
3.什么是json与picjle的区别是什么?
json:可以和其他语言玩
pickle:只能和自己(python)玩
4.ATM的登录与注册功能,用户数据用json数据保存。
with open(user_path, 'w', encoding='utf-8') as f:
json.dump(user_dic, f, ensure_ascii=False)
f.flush()
5.写一个扑克牌随机发牌游戏
飘三叶:
有bug,可取到重复的牌
import random
def fried_golden_flower():
for i in range(0, 3):
color = random.choice(['♥', '♠', '♦', '♣'])
number = random.choice(['A', '2', '3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K'])
a = color
b = number
point = namedtuple('扑克牌', ['color', 'number'])
p = point(color, number)
print(p, a+b)
fried_golden_flower()
斗地主:
from collections import namedtuple
import random
def fight_against_landlords():
list = ['大鬼', '小鬼']
color = ['♥', '♠', '♦', '♣']
number = ['A', '2', '3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K']
for i in color:
for n in number:
list.append(i+n)
# 打乱顺序
random.shuffle(list)
# 生成迭代器,避免取到重复的牌
a = list.__iter__()
for i in range(0,3):
list_s = [] # 将发的17张牌放在此列表中
for num in range(0, 17):
list_s.append(a.__next__())
print("玩家%s:%s" % (i+1, list_s))
dizhupai = []
for i in range(0, 3):
dizhupai.append(a.__next__())
print('地主牌:%s' % dizhupai)
fight_against_landlords()
11.19 爬虫正则
# 注意: 先敲课堂上的代码,理解并记录博客,再写作业!
'''
1.subprocess模块的作用?
subprocess 子进程模块
2.什么是包?包的作用是什么?
包是一个带有__init__.py的文件夹,包也可以被导入,并且可以一并导入包下的所有模块。
3.如何防止模块被导入时自动执行测试功能。
伪代码:
if __name__ == '__main__':
调用执行的函数()
4.请写出logging模块的使用步骤:
# logging配置字典
LOGGING_DICT = {...}
1.配置日志的路径,项目的路径
2.配置日志的文件(名字,创建日志文件)
3.配置日志字典数据
4.调用日志模块,并把字典数据当参数参数
5.请写出爬虫原理的4个过程?
整个流程:
1.发送请求:requests
2.获取响应数据:对方机器直接返回
3.解析并提取想要的数据:re
4.保存提取后的数据:with open()保存
我们需要做的:
1.发送请求
2.解析数据
3.保存数据
6.什么是正则表达式与re模块?
正则表达式:一种筛选匹配字符串的独立技术
re模块:pycharm利用re模块,匹配字符串
7.使用正则表达式匹配出str1中的地址。
source = '''
<html><h1>www.baidu.com</h1></html>
<html><h1>www.taobao.com</h1></html>
<html><h1>www.jd.com</h1></html>
<html><h1>www.oldboyedu.com</h1></html>
'''
答案1:print(re.findall('www.(?:baidu|taobao|jd|oldboyedu).com', source))
结果:['www.baidu.com', 'www.taobao.com', 'www.jd.com', 'www.oldboyedu.com']
答案2:print(re.findall('www..*com', source))
8.用正则过滤掉str3中的英文和数字,最终输出"张全蛋 广州"
str3 = "not 404 found 张全蛋 99 广州"
不标准答案:print(re.findall('(?:张全蛋|广州)', str3))
结果:['张全蛋', '广州']
答案:print(re.findall('[^a-z:0-9:A-Z ]{2}', str3))
结果:['张全蛋', '广州']
9.复习今日之前的所有知识点!!!
'''
11.25
1.面向对象编程的优缺点是什么?
优点:可扩展性高
缺点:相对于面向过程复杂度高
2.对象的属性查找顺序是什么?
自己——类——报错
3.求结果:
class Student:
name = '张全蛋'
def __init__(self, name):
self.name = name
def learn(self):
print('learning...')
stu1 = Student('赵铁柱')
print(stu1.name)
# 结果:赵铁柱 优先查找自己
11.26
1.什么是继承?继承的目的?
继承是一种创建新类的方式,在python中,新建的类可以继承一个或多个父类,父类又可称为基类或超类(super),新建的类称为派生类或子类
2.python与期他语言的继承区别是什么?
python可以多继承,其他语言只能单继承
3.如何寻找继承关系?
mro(): 会把当前类的继承关系列出来
4.继承背景下对象属性的查找顺序是什么?
自己-->类->报错
5.什么是派生?如何重用父类的属性并派生?两种方式
第一种:super().__init方法
class Animal():
def __init__(self, name, eat, run):
self.name = name
self.eat = eat
self.run = run
print(f'{self.name}会{self.eat}')
print(f'{self.name}会{self.run}')
class Sunwukong(Animal):
def __init__(self, name, eat, run, aa):
super().__init__(name, eat, run)
self.aa = aa
第二种:父类.__init__方法
class Animal():
def __init__(self, name, eat, run):
self.name = name
self.eat = eat
self.run = run
print(f'{self.name}会{self.eat}')
print(f'{self.name}会{self.run}')
class Sunwukong(Animal):
def __init__(self, name, eat, run, aa):
Animal.__init__(self,name, eat, run)
self.aa = aa
6.什么是新式类与经典类?
- 新式类:
1.凡是继承object的类或子孙类都是新式类。
2.在python3中所有的类都默认继承object,都是新式类。
- 经典类:
1.在python2中才会有经典类与新式类之分。
2.在python2中,凡是没有继承object的类,都是经典类。
7.钻石继承下,经典类与新式类属性的查找顺序是什么?
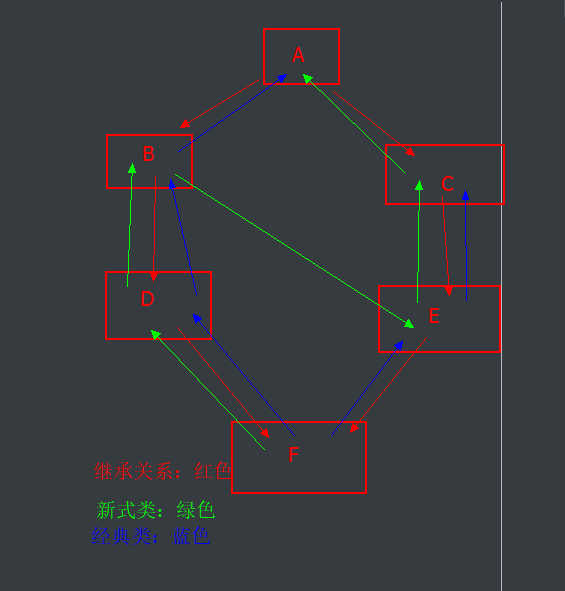
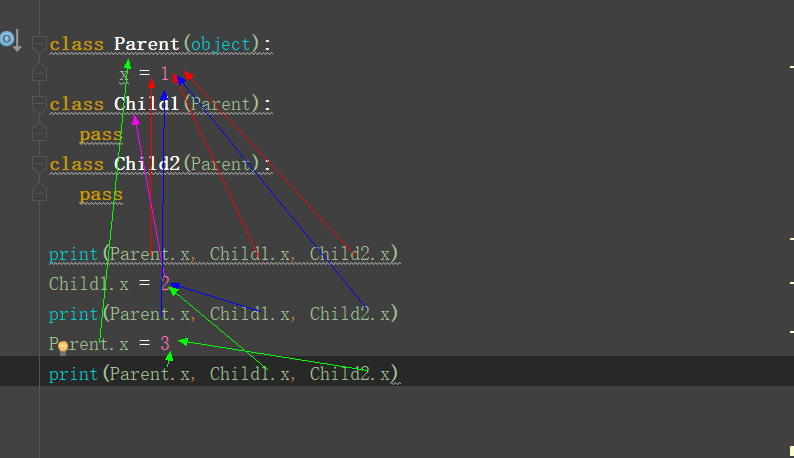
8.下面这段代码的输出结果将是什么?请解释。
class Parent(object):
x = 1
class Child1(Parent):
pass
class Child2(Parent):
pass
print(Parent.x, Child1.x, Child2.x) # 1 1 1
Child1.x = 2
print(Parent.x, Child1.x, Child2.x) # 1 2 1
Parent.x = 3
print(Parent.x, Child1.x, Child2.x) # 3 2 3
# 结果:
1 1 1
1 2 1
3 2 3
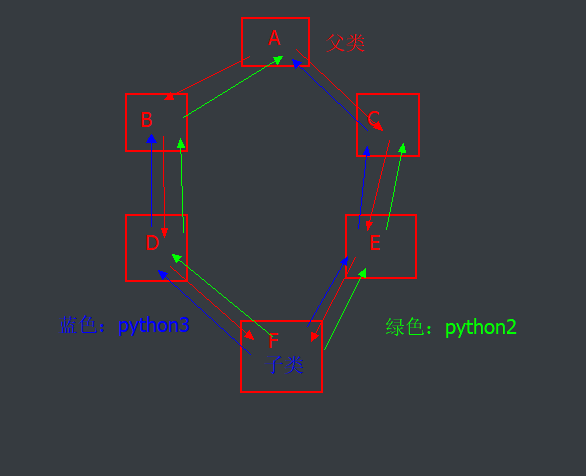
9.下述代码新式类与新式类的查找顺序是什么?
class A(object):
def test(self):
print('from A')
class B(A):
def test(self):
print('from B')
class C(A):
def test(self):
print('from C')
class D(B):
def test(self):
print('from D')
class E(C):
def test(self):
print('from E')
class F(D, E):
def test(self):
print('from F')
pass
# python3中校验:
FD->DB->FE->EC->CA
# python2中校验:
FD->DB->BA->FE->EC
11.27
1.什么是组合?为什么要使用组合?
组合指的是一个对象中,包含另一个或多个对象。
2.什么是封装?
隐藏对象的属性和实现细节,仅对外提供公共访问方式
3.什么是访问限制机制?
在内部在属性前加'__',使属性私有化。实际上是内部替换了变量名称 方法名 替换为:_类名__方法名
4.访问限制机制的优点?
1.让一些关键的数据,变成私有更加的安全
2.不是随意可以更改的
3.在属性,和方法前面加’__‘,变成私有,那么外界就不可以直接调用修改。
4.但是:在类的内部可以定义一个函数,方法调用修改。使用者直接调用这个函数就可以了。这个函数就是接口
5.可以在这个函数、方法加条件限制,而不是任意的改动
5.什么是property?为什么要使用property?
让使用者调用方式一致,是一个内置的装饰器。
使用了property内置装饰器之后,使用者调用方法时少了一个括号,导致看起来像获取某个方法,而不是加括号执行某个函数
6.练习题: 老师学生课程
- 需求:
- 老师对象:
- 特征:
# 老师信息都为隐私数据,需要私有化
- 1.姓名
- 2.年龄
- 3.性别
- 4.薪资
- 5.等级
- 6.身份证ID
# 课程列表无需私有化
- 7.课程列表
- 技能:
- 1.查看老师信息接口:
- 直接打印即可
- 2.获取老师身份证ID:
- 该方法将 动词设置为 名词的调用方式
- 3.添加课程:
- 该功能为老师课程列表添加课程对象
- 4.删除指定课程
- 该功能删除老师课程列表中的课程对象
- 5.修改课程信息
- 修改老师课程课表中课程的
- 6.打印所有课程
- 打印老师课程列表中所有课程的信息
- 遍历调用所有课程对象中打印课程技能
- 课程对象:
- 特征:
- 1.课程名称
- 2.课程价格
- 3.课程周期
- 技能:
- 1.可以打印课程信息
class Techer():
def __init__(self, name, age, sex, money, lever, ID):
self.__name = name
self.__age = age
self.__sex = sex
self.__money = money
self.__lever = lever
self.__ID = ID
self.course_list = []
def select_user(self):
print(f'''
姓名:{self.__name}
年龄:{self.__age}
性别:{self.__sex}
薪资:{self.__money}
等级:{self.__lever}
身份证:{self.__ID}
''')
@property
def select_ID(self):
print(f'身份证:{self.__ID}')
# 添加课程
def insert_course(self, course):
self.course_list.append(course)
print('添加课程成功!')
# 删除指定课程
def del_course(self, course):
self.course_list.remove(course)
print('删除成功!')
# 修改课程
def revise_course(self, to_course,from_course):
# 先删除原来的,在添加修改后的
self.course_list.remove(to_course)
self.course_list.append(from_course)
def select_course(self):
print(self.course_list)
class Course():
def __init__(self, name, price, time):
self.name = name
self.price = price
self.time = time
self.list = [self.name, self.price, self.time]
# course_list = [self.name, self.price, self.time]
def select_course(self):
print(f'''
课程名称:{self.name}
课程价格:{self.price}
课程周期:{self.time}
''')
# 产生两个对象
jeff = Techer('jeff','18','男',10000,15,13456465)
python = Course('python', 19999, '6个月')
go = Course('go', 2999, '8个月')
# 组合
jeff.course = python
jeff.course = go
# 获取课程信息列表(对象)
python = python.list
go = go.list
# 将对象传给接口
jeff.insert_course(python)
jeff.insert_course(go)
# 查看课程
jeff.select_course()
# jeff.revise_course('php','java')
# jeff.select_course()
# 运行
# jeff.select_user()
# jeff.course.select_course()