
解析:支架模板支持的类型包括Empty、Create、Delete、Details、Edit、List

解析:Spring支持4种依赖检查:默认的是none。因此说法不正确的结果是D

解析:各层之间不是都能相互访问的

解析:在解析XML文件数据绑定在TreeView控件操作中,需要在TreeView控件的DataBindings属性里,找到TextField属性并设置值。TextField属性是数据绑定时用于节点的Text属性的表列或XML特性名,所以还需要把节点的名称赋值给TextField属性。排除ab。NavigateUrlField属性,也就是说当 TreeView 控件绑定到某数据源时,请使用 NavigateUrlField 属性指定要绑定到 TreeNode 对象的 NavigateUrl 属性的字段名。所以正确选项为cd

解析:调用get方法会通过主键查询,查询时会首先在缓存中查找,找到了直接返回缓存对象,找不到,才会发sql查询,并且将对象存入缓存中,对象地址是一样的

解析:Action() 方法直接用于请求控制器的动作方法,然后通过动作方法返回结果展示部分视图。 Partial()是不能对应动作方法的,更不能做主视图

解析:更新操作是将本地版本更新为服务器上的最新版本。删除操作需要提交才能生效。

解析:RenderSection()方法是用于呈现指定部分的内容,即在母版页中某个位置定义一个容器,内容页中输出。并不是必须的,而RenderBody()方法呈现内容视图中的内容这是必须调用的方法
解析:IOC是控制反转,就是类本身不控制其属性的值,而是交给第三方容器注入。所以不需要通过代码实现


解析:ValidationMessage()和ValidationSummary()方法封装了对ModelState对象的调用

解析:对应字符串类型的属性,如果要访问动态数据,必须使用%{..}这样的语法,否则将被直接作为字符串常量
解析:ERROR等关键字需要继承actionsupport, execute()方法返回success
解析:get方法类级别不延迟加载,load方法默认配置类级别延迟加载。4句会先在缓存中寻找,而2已经产生了sql语句而且和4一样,所以不会产生sql语句

解析:
局部变量在被使用时应该先赋值,故选项a错误
不能把非空的类型的值直接赋给可空类型的变量,故选项b错误

解析:Spring与Mybatis集成的两种方式:映射接口和SqlSessionTemplate

解析:SimpleTrigerBean可以配置延迟启动时间、间隔时间、重复执行次数、开始时间、结束时间等,但d选项startTime不是毫秒数,而是规定的日期格式 (yyyy-MM-dd HH:mm:ss)

解析:
Required验证特性是非空验证,即必须输入;StringLength特性是验证字符串的长度;RegularExpression特性是正则表达式;Compare特性是比较两者之间是否相同;Range特性是指范围

解析:Hibernate使用延迟加载实现对性能优化,当真正使用应该数据的时候才会发送sql,故为了避免读取大字段带来的性能开销,应该设置属性的延迟加载机制

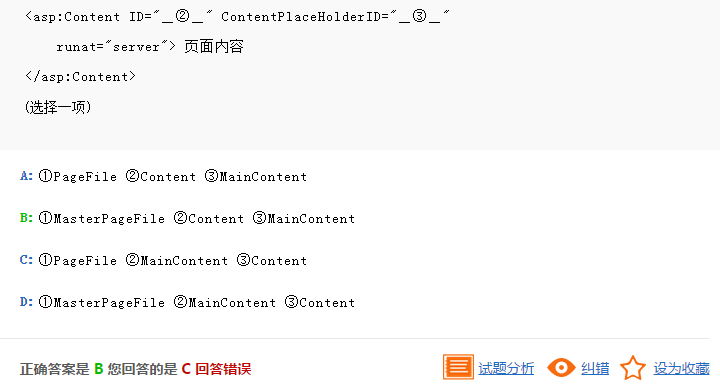
解析:MasterPageFile设置的值是母版视图文件的完整的路径,<asp:Content>标记是和母版视图的<asp:ContentPlaceHolder>标记是对应的,对应关系是通过ContentPlaceHolderID的属性值来确定的。

解析:绑定用#,格式化要用{}

解析:使用DTD验证XML文档有两种方式,一种是直接把DTD嵌入在XML中,称为内部DTD文档。
另外一种是吧DTD存储在独立的文件中,存储DTD的文件一般以.dtd作为文件的扩展名,然后在要验证的XML文件中引入,语法如下:
<!DOCTYPE 根元素 SYSTEM “DTD文件路径” >

解析:静态资源使用HttpHandler需要在web.config 中配置用到的HttpHandler

解析:
org.hibernate.Session的flush()方法可以强制同步缓存和数据库,clear()方法用来清空缓存中保存的持久化对象。
org.hibernate.Transaction的commit()方法会强制同步缓存和数据库,除非FlushMode设置为MANUAL。对持久化对
象的属性值进行修改不会立即触发缓存与数据库的同步操作,直到调用flush()方法或commit()方法或执行某些查询操作。
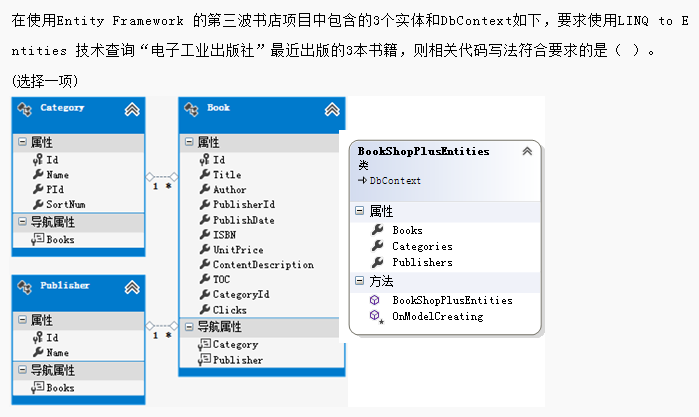

解析:由于要查询的是“最近出版的3本书”,需要降序排列,A、D是升序排列,take()分区方法是查询出结果集之后,才进行筛选的

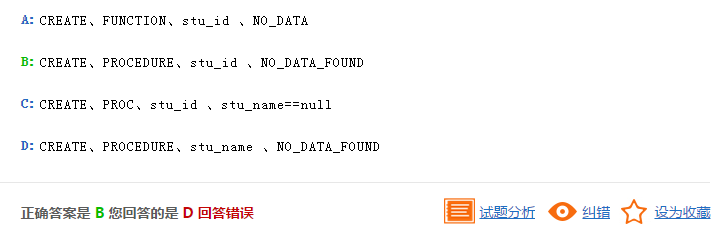
解析:创建存储过程需要使用PROCEDURE,因此a、c错误,因为通过学号参数进行查询,因此d错误