一、Ceph基础:
1、基础概念:
ceph 是一个开源的分布式存储,同时支持对象存储、块设备、文件系统
ceph是一个对象(object)式存储系统,它把每一个待管理的数据流(文件等数据)切分伟一到多个固定大小(默认4M)的对象数据,并以其为原子单元(原子是构成元素的最小单元)完成数据的读写
对象数据的底层存储服务是由多个存储主机(host)组成的存储集群,该集群也被称之为RADOS(reliable automatic distributed object store)存储集群,即可靠的、自动化的、分布式的对象存储系统
librados是RADOS存储集群的API,支持C/C++/JAVA/Python/ruby/go/php等多种编程语言客户端
2、ceph的设计思想:
ceph的设计宗旨在实现以下目标:
每一组件皆可扩展
无单点故障
基于软件(而非专业设备)并且开源(无供应商)
在现有的廉价硬件上运行
尽可能自动管理,减少用户干预
3、ceph版本:
x.0.z - 开发版
x.1.z - 候选版
x.2.z - 稳定、修正版
4、ceph集群角色定义:
参考:https://docs.ceph.com/en/latest/start/intro/ 和 http://docs.ceph.org.cn/start/intro/
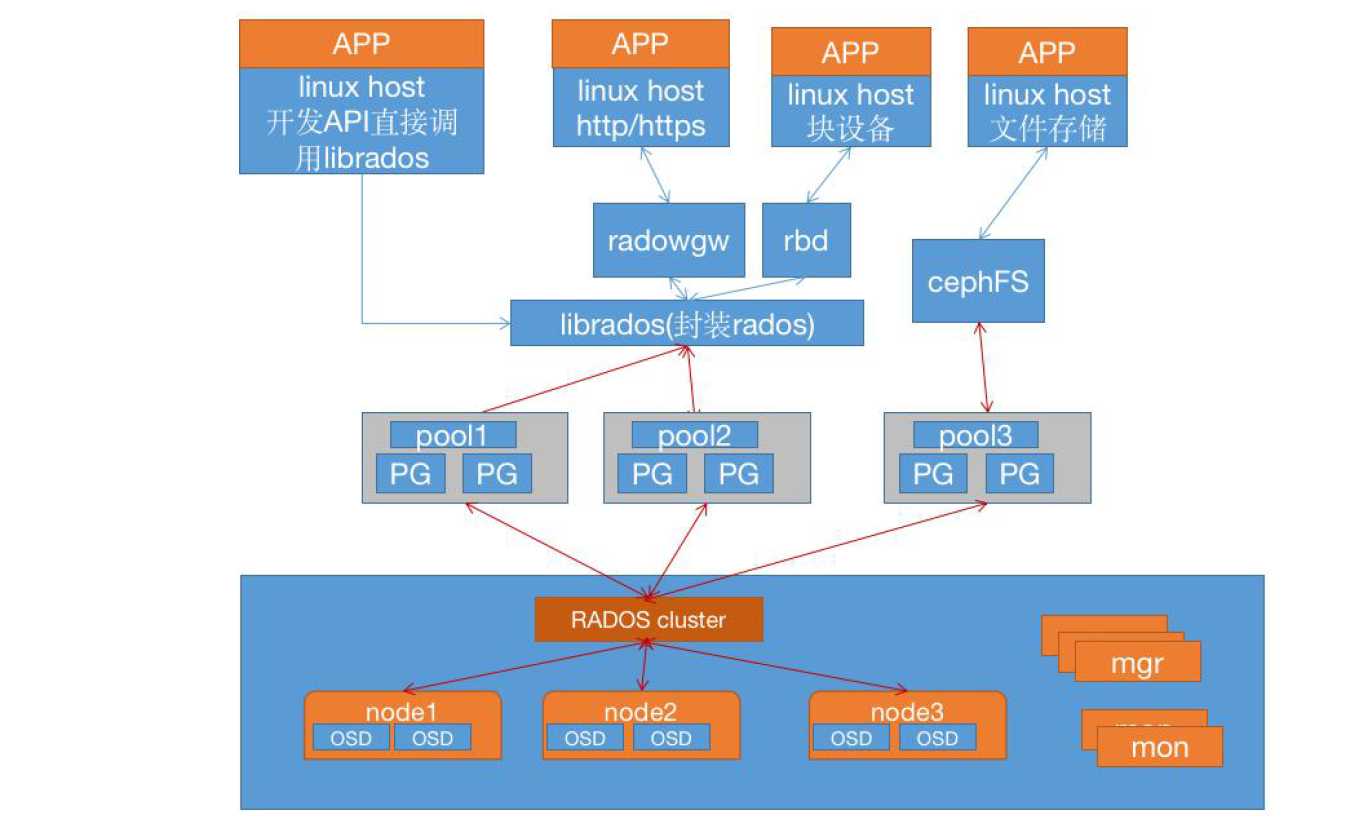
5、ceph集群的组成部分:
若干的Ceph OSD(对象存储守护进程)
至少需要一个Ceph Monitor 监视器 (数量最好为奇数1,3,5,7........)
两个或以上的Ceph管理器 managers,运行Ceph文件系统客户端时还需要高可用的Ceph Metadata Server(文件系统元数据服务器)
RADOS Cluster:由多台host存储服务器组成的ceph集群
OSD(Object Storage Daemon):每台存储服务器的磁盘组成的存储空间
Mon(Monitor):Ceph的监视器,维护OSD和PG的集群状态,一个Ceph集群至少有一个Mon节点,可以是一三五七等这样的奇数个
Mgr(Manager):负责跟踪运行时指标和Ceph集群的当前状态,包括存储利用率,当前性能指标和系统负载等
6、Ceph集群术语详细介绍:
6.1 Monitor(ceph-mon)ceph监视器:
软件包名&进程名:ceph-mon
在一个主机上运行的一个守护进程,用于维护集群状态映射(maintains maps of the cluster state),比如ceph 集群中有多少存储池、每个存储池有多少PG 以及存储池和PG的映射关系等, monitor map, manager map, the OSD map, the MDS map, and the CRUSH map,这些映射是Ceph 守护程序相互协调所需的关键群集状态,此外监视器还负责管理守护程序和客户端之间的身份验证(认证使用cephX 协议)。通常至少需要三个监视器才能实现冗余和高可用性。
6.2 Managers
软件包&进程名:ceph-mgr
在一个主机上运行的一个守护进程,Ceph Manager 守护程序(ceph-mgr)负责跟踪运行时指标和Ceph 集群的当前状态,包括存储利用率,当前性能指标和系统负载。Ceph Manager 守护程序还托管基于python 的模块来管理和公开Ceph 集群信息,包括基于Web的Ceph 仪表板和REST API。高可用性通常至少需要两个管理器。
6.3 Ceph OSDs(对象存储守护程序ceph-osd)
软件包名&进程名:ceph-osd
提供存储数据,操作系统上的一个磁盘就是一个OSD 守护程序,OSD 用于处理ceph集群数据复制,恢复,重新平衡,并通过检查其他Ceph OSD 守护程序的心跳来向Ceph监视器和管理器提供一些监视信息。通常至少需要3 个Ceph OSD 才能实现冗余和高可用性。
6.4 MDS(ceph元数据服务器ceph-mds)
软件包名&进程名:ceph-mds
代表ceph文件系统(NFS/CIFS)存储元数据(即Ceph块设备和Ceph对象存储不使用MDS)
6.5 Ceph的客户端管理工具
例如:rados、ceph、rbd 推荐使用部署专用节点对ceph进行管理、升级和后期维护,方便权限管理,避免一些不必要的误操作发生
6.6 Ceph的其他相关术语请参考:http://docs.ceph.org.cn/glossary/
7、Ceph逻辑组织架构:
7.1 Pool:存储池 ,分区、存储池的大小取决于底层的存储空间
7.2 PG(Placement group):一个pool内部可以有多个PG存在,pool和PG都是抽象的逻辑概念,一个pool中有多少个PG可以通过公式计算
7.3 OSD(Object Storage Daemon,对象存储设备):每一块磁盘都是一个osd,一个主机由一个或多个osd组成
8、向Ceph写入数据的大致流程:
Ceph集群部署好了之后,要先创建存储池才能向ceph写入数据,文件在向ceph保存之前要先进行一致性hash计算,计算后会把文件保存在某个对应的PG中,此文件一定属于某个pool的一个PG,再通过PG保存在OSD上。数据对象在写到主OSD之后再同步到从OSD以实现数据的高可用

根据上图总结一下存储文件到Ceph的流程:
1、计算文件到对象的映射:假设file为客户端要读写的文件,得到oid(object id)= ino + ono (其中ino:inode number ,file的元数据序列号 ,file的唯一ID;ono:object number,file切分产生的某个object的序号,默认以4M切分一个块的大小)
2、通过hash算法计算出文件对应的pool中的PG:通过一致性hash计算Object到PG,Object-》PG映射hash(oid)&mask-》pgid
3、通过CRUSH把对象映射到PG中的OSD:通过CRUSH算法计算PG到OSD,PG——》OSD映射:[CRUSH(pgid)——》(osd1,osd2,osd3)]
4、PG中的主OSD将对象写入到硬盘
5、主OSD将数据同步给备份OSD即从OSD,并等待备份OSD返回确认
6、主OSD将写入完成返回给客户端
9、Ceph元数据保存方式:
9.1 xattrs(扩展属性):是将元数据保存在对象对应文件的扩展属性中并保存到系统盘上,这要求支持对象存储的本地文件系统(一般是XFS)支持扩展属性
9.2 omap(object map:对象映射):是将元数据保存在本地文件系统之外的独立key-value存储系统中,在使用filestore时是leveldb;在使用bluestore时是rocksdb
9.3 filestore与leveldb
Ceph早期基于filestore使用google的leveldb保存对象元数据。Leveldb是一个持久化存储的KV系统,与Redis不同的是,leveldb不会像Redis一样将数据放在内存中从而占据打两的内存空间,而是将大部分数据存储到磁盘上,但是需要把磁盘格式化为文件系统(XFS)
Filestore将数据保存到与Posix兼容的文件系统(Btrfs,XFS,Ext4),缺点:性能、对象属性与磁盘本地的文件系统属性匹配存在限制

9.4 bluestore与rocksdb
由于levelDB依赖磁盘文件系统的支持,后期facebook对levelDB进行改进为RocksDB(https://github.com/facebook/rocksdb)。RocksDB将对象数据的元数据保存在RocksDB,在当前OSD中划分出一部分空间,格式化为BlueFS文件系统用于保存RocksDB中的元数据信息(称为BlueStore)并实现元数据的高可用,BlueStore的最大优点就是构建在裸磁盘设备之上,并对诸如OSD等新的存储设备做了很多优化工作
RocksDB通过中间层BlueRocksDB访问文件系统接口,这个文件系统与传统的Linux文件系统(例如Ext4,XFS)不同,它不是VFS下面的通用文件系统,而是一个用户态的逻辑。BlueFS通过函数接口(API,非POSIX)的方式为BlueRocksDB提供类似文件系统的能力
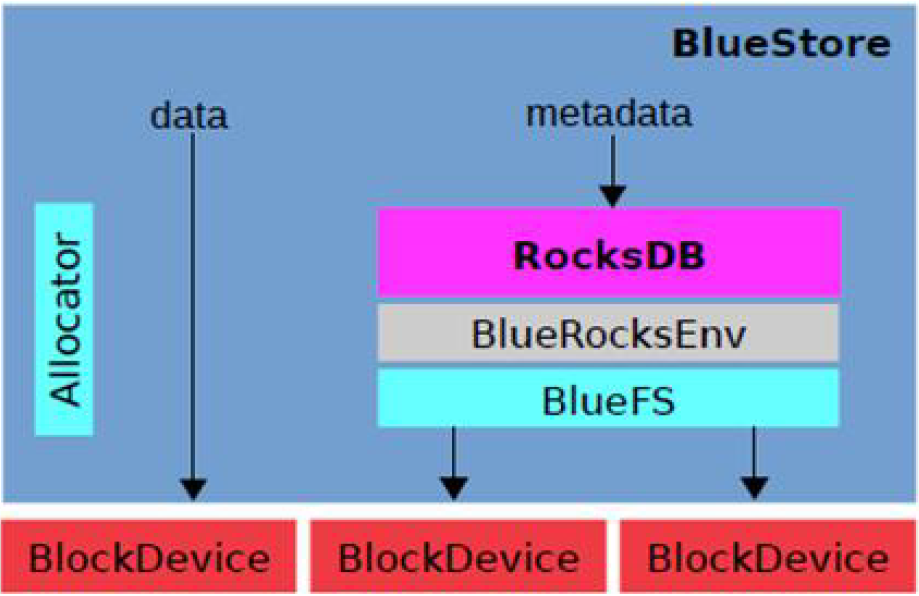
以上各模块的作用:
Allocator:负责裸设备的空间管理分配
RocksDB:基于leveldb的开发的一款KV数据库,BlueStore将元数据全部存放至RocksDB中,这些元数据包括存储预写日志、数据对象元数据、Ceph的omap数据信息、以及分配器的元数据
BlueRocksEnv:这是RocksDB与BlueFS的交互接口,RocksDB提供了文件操作的接口EnvWrapper(Env封装器),可以通过继承实现该接口来定义底层的读写操作,BlueRocksEnv就是继承EnvWrapper实现对BlueFS的读写
BlueFS:BlueFS是BlueStore针对RocksDB开发的轻量级文件系统,用于存放RocksDB产生的.sst和.log文件
BlockDevice:BlueStore抛弃了传统的ext4、xfs文件系统,使用直接管理裸盘的方式;BlueStore支持同时使用多种不同类型的设备,在逻辑上BlueStore将存储空间划分为三层:慢速(Slow)空间,高速(DB)空间,超高速(WAL)空间,不同空间可以指定不同的设备类型,当然也可使用同一块设备
BlueStore的优势:BlueStore的设计考虑了FileStore中存在的一些硬伤,抛弃了传统的文件系统直接管理裸设备,缩短了IO路径,同时采用ROW的方式,避免了日志双写的问题,在写入性能上有了极大的提高
10、CRUSH算法简介:
CRUSH:Controllers replication under scalable hashing:可控的、可复制的、可伸缩的一致性hash算法,CRUSH是一种分布式算法,类似于一致性hash算法,用于为RADOS存储集群控制数据的分配
Ceph使用CRUSH算法来存放和管理数据,它是Ceph的智能数据分发机制。Ceph使用CRUSH算法来准确计算数据应该被保存到哪里,以及应该从哪里读取。和保存元数据不同的是,CRUSH按需计算出元数据,因此它就消除了对中心式服务器/网关的需求,它使得Ceph客户端能够计算出元数据,该过程也称为CRUSH查找,然后和OSD直接通信
这里就会有一个问题,为什么要这么设计CRUSH算法?如果是把对象直接映射到OSD之上会导致对象与OSD的对应关系过于紧密和耦合,当OSD由于故障发生变更时将会对整个Ceph集群产生影响。于是Ceph将一个对象映射到RADOS集群的时候分两步走:首先使用一致性hash算法将对象名称映射到PG ,然后将PG ID基于CRUSH算法映射到OSD即可查到对象。
以上两个过程都是以”实时计算“的方式完成,而没有使用传统的查询数据与块设备的对应表的方式,这样有效的避免了组件的”中心化“问题,也解决了查询性能和冗余问题,使得Ceph集群扩展不再受查询的性能限制
二、Ceph集群部署
1、环境准备
系统版本:ubuntu-18.04-lts
内存: 3G
CPU:1C
磁盘:每台主机挂载5块数据盘
ip hostname role
192.168.199.22 ubuntu-node02 ceph-deploy、ceph-mgr、ceph-mon、ceph-node
192.168.199.23 ubuntu-node03 ceph-node
192.168.199.24 ubuntu-node04 ceph-node
2、配置国内ubuntu源
vim /etc/apt/sources.list
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释 deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse # deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse # deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse # deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse # deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
3、配置时间同步:
apt install ntpdate -y
ntpdate ntp1.aliyun.com
4、配置本地hosts文件
vim /etc/hosts
192.168.199.22 ubuntu-node02 192.168.199.23 ubuntu-node03 192.168.199.24 ubuntu-node04
5、导入ceph的校验码,添加国内的ceph源
wget -q -O- "https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc" | sudo apt-key add -
sudo echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main" >> /etc/apt/sources.list
6、配置双网卡:
ens33:桥接
ens38:nat
注:另外两台机器只需将IP修改一下就可以了
vim /etc/netplan/01-netcfg.yaml
network:
version: 2
renderer: networkd
ethernets:
ens33:
dhcp4: no
dhcp6: no
addresses: [ 192.168.199.22/24 ]
gateway4: 192.168.199.1
nameservers:
search: [ ubuntu-node02 ]
addresses:
- "192.168.199.1"
ens38:
dhcp4: no
dhcp6: no
addresses: [ 172.16.1.22/24 ]
7、创建ceph用户并配置可免密登录其他节点
groupadd -r -g 2022 ceph && useradd -r -m -s /bin/bash -u 2022 -g 2022 ceph && echo ceph:123456 | chpasswd
ssh-keygen -t rsa
ssh-copy-id ceph@192.168.199.22
ssh-copy-id ceph@192.168.199.23
ssh-copy-id ceph@192.168.199.24
允许ceph用户执行sudo命令: echo "ceph ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers
8、安装ceph部署工具ceph-deploy:
apt-cache madison ceph-deploy # 列出ceph-deploy的版本信息
apt install ceph-deploy -y
9、初始化mon节点:
切换到ceph用户的家目录创建ceph集群初始化目录:
su - ceph
mkdir ceph-cluster
各节点安装python2并创建软链接
apt install python2.7 -y
ln -sv /usr/bin/python2.7 /usr/bin/python2
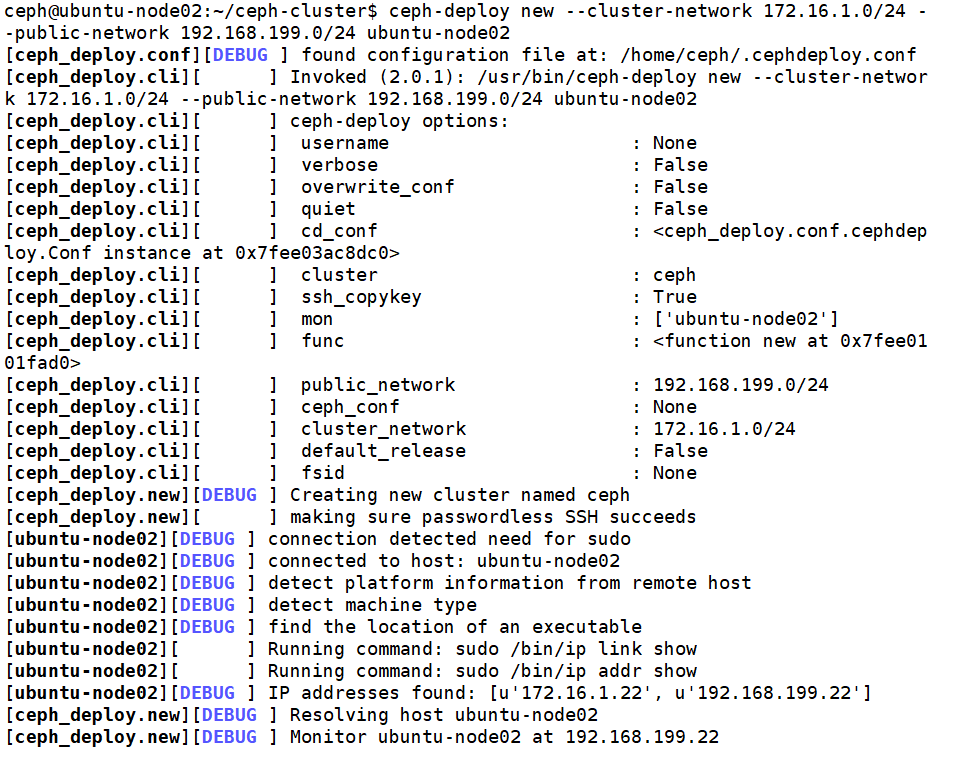
ceph-deploy new --cluster-network 172.16.1.0/24 --public-network 192.168.199.0/24 ubuntu-node02
注:
--cluster-network:指定ceph集群内部通信的网段
--public-network:指定外部访问的网段地址
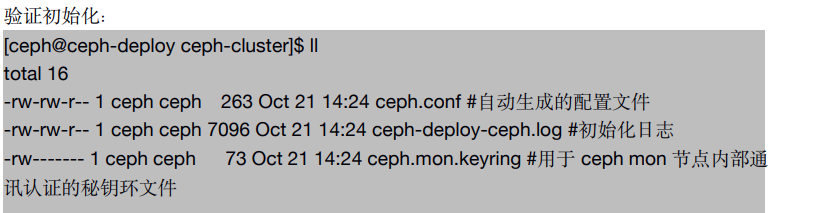
10、初始化node节点:
注意:确保ceph用户的家目录在/var/lib/ceph并且将原来/home/ceph/目录下面的ceph-cluster目录下面的文件拷贝到/var/lib/ceph/ceph-cluster目录下
ceph-deploy install --no-adjust-repos --nogpgcheck ubuntu-node02 ubuntu-node03 ubuntu-node04 # 根据情况输入yes和主机密码
11、配置mon节点并同步生成秘钥:
apt install ceph-mon -y
ceph-deploy mon create-initial # 初始化mon节点
验证mon节点:

分发admin秘钥:
apt-get install ceph-common -y
ceph-deploy admin ubuntu-node02
12、ceph节点验证秘钥:

修改/etc/ceph/ceph.client.admin.keyring文件的属主:
sudo chown -R ceph. /etc/ceph/
13、配置manager节点:
sudo apt install ceph-mgr -y # 安装ceph-mgr
ceph-deploy mgr create ubuntu-node02 # 创建管理节点
验证mgr节点:

14、使用ceph-deploy管理ceph集群:
15、验证ceph命令:
注意:因为重新推送了admin秘钥,所以/etc/ceph/ceph.client.admin.keyring文件的属主改变了 需要重新修改属主
sudo chown -R ceph. /etc/ceph/
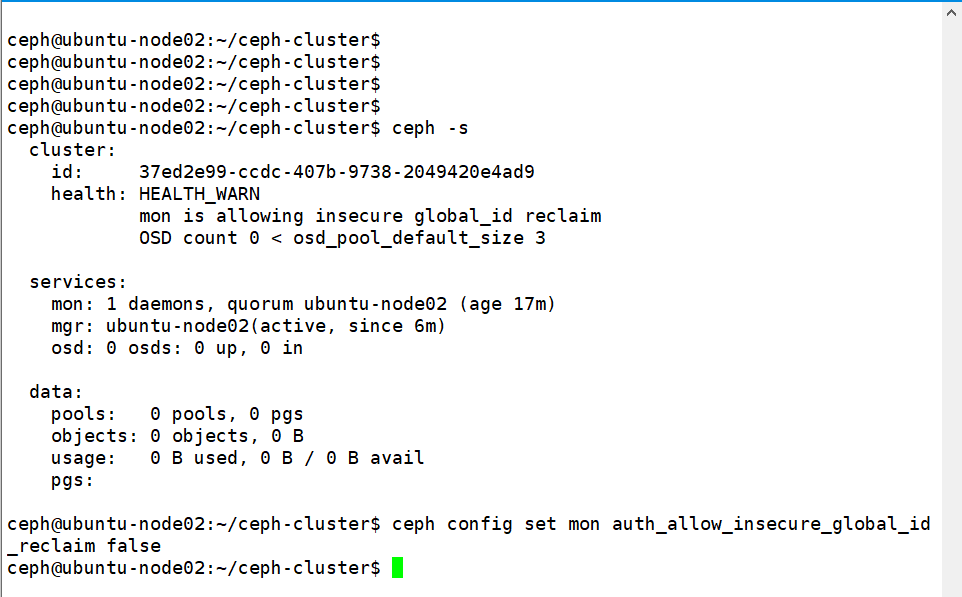
16、集群调整:
17、准备OSD节点:
初始化环境:
ceph-deploy install --release pacific ubuntu-node02
ceph-deploy install --release pacific ubuntu-node03
ceph-deploy install --release pacific ubuntu-node04
列出指定节点的磁盘信息:
ceph-deploy disk list ubuntu-node02
使用 ceph-deploy disk zap 擦除各 ceph node 的 ceph 数据磁盘:
ceph-deploy disk zap ubuntu-node02 /dev/sdb ceph-deploy disk zap ubuntu-node02 /dev/sdc ceph-deploy disk zap ubuntu-node02 /dev/sdd ceph-deploy disk zap ubuntu-node02 /dev/sde ceph-deploy disk zap ubuntu-node02 /dev/sdf ceph-deploy disk zap ubuntu-node03 /dev/sdb ceph-deploy disk zap ubuntu-node03 /dev/sdc ceph-deploy disk zap ubuntu-node03 /dev/sdd ceph-deploy disk zap ubuntu-node03 /dev/sde ceph-deploy disk zap ubuntu-node03 /dev/sdf ceph-deploy disk zap ubuntu-node04 /dev/sdf ceph-deploy disk zap ubuntu-node04 /dev/sde ceph-deploy disk zap ubuntu-node04 /dev/sdd ceph-deploy disk zap ubuntu-node04 /dev/sdc ceph-deploy disk zap ubuntu-node04 /dev/sdb
18、添加OSD:
ceph-deploy osd create ubuntu-node02 --data /dev/sdb ceph-deploy osd create ubuntu-node02 --data /dev/sdc ceph-deploy osd create ubuntu-node02 --data /dev/sde ceph-deploy osd create ubuntu-node02 --data /dev/sdd ceph-deploy osd create ubuntu-node02 --data /dev/sdf ceph-deploy osd create ubuntu-node03 --data /dev/sdb ceph-deploy osd create ubuntu-node03 --data /dev/sdc ceph-deploy osd create ubuntu-node03 --data /dev/sdd ceph-deploy osd create ubuntu-node03 --data /dev/sde ceph-deploy osd create ubuntu-node03 --data /dev/sdf ceph-deploy osd create ubuntu-node04 --data /dev/sdb ceph-deploy osd create ubuntu-node04 --data /dev/sdc ceph-deploy osd create ubuntu-node04 --data /dev/sdd ceph-deploy osd create ubuntu-node04 --data /dev/sde ceph-deploy osd create ubuntu-node04 --data /dev/sdf
19、设置OSD服务自启动:

注:ubuntu-node03节点和ubuntu-node04节点以此类推
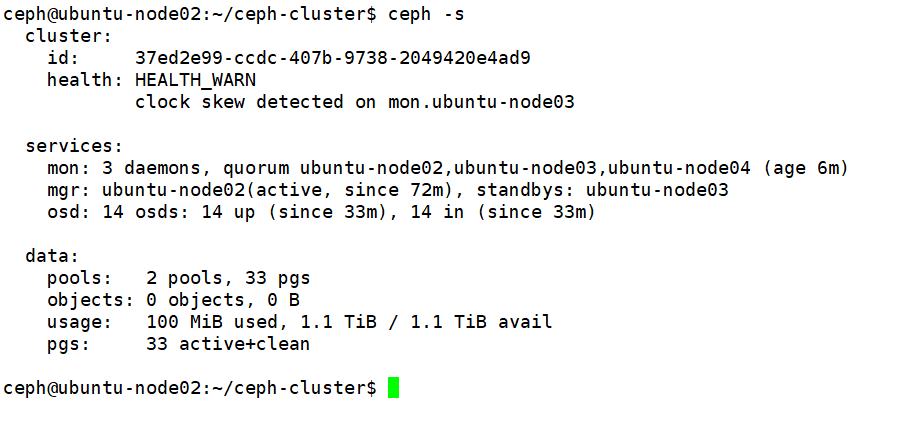
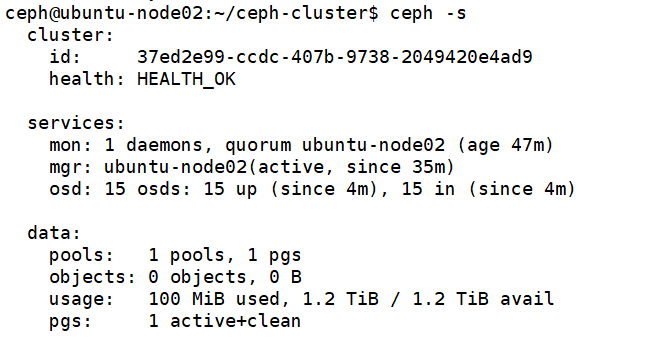
20、验证ceph集群:
21、从RADOS移除OSD:
21.1 停用设备:ceph osd out 14
22.2 停止进程:systemctl stop ceph-osd@14
22.3 移除设备:ceph osd purge 14 --yes-i-really-mean-it
22、测试上传和下载数据:
创建pool:ceph osd pool create mypool 32 32 # 32PG和32PGP
ceph pg ls-by-pool mypool | awk '{print $1,$2,$15}' # 验证PG和PGP的组合
ceph osd pool ls 或者 rados lspool # 列出所有的pool
上传文件:
rados put msg1 /var/log/syslog --pool=mypool # 文件上传mypool并且指定对象id为msg1
列出文件:
rados ls --pool=mypool
文件信息:
ceph osd map mypool msg1 # ceph osd map命令可以获取到存储池中数据对象的具体位置信息
下载文件:
rados get msg1 --pool=mypool /opt/my.txt
删除文件:
rados rm msg1 --pool=mypool
三、集群扩展
1、扩展ceph-mon节点:
apt install ceph-mon -y # 安装ceph-mon软件包
ceph-deploy mon add ubuntu-node03 # 在管理节点增加mon节点
ceph-deploy mon add ubuntu-node04
ceph quorum_status --format json # 验证状态
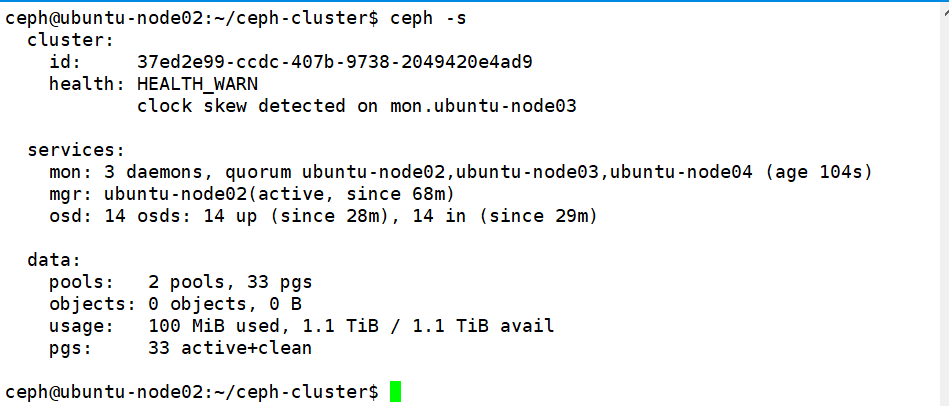
2、扩展mgr节点:
apt install ceph-mgr -y
ceph-deploy mgr create ubuntu-node03
ceph-deploy admin ubuntu-node03 # 同步配置到ubuntu-node03节点
验证mgr节点状态: