[任何爬虫均只为学习,不用于商业及其他目的,侵权删]
一.概述
本次针对图灵社区进行爬取免费的推荐书籍。
一般进行爬虫前需要先针对网站的dom域进行一次分析;确定爬取的关键位置/关键字
二. 开始
1.先打开->"图灵社区的免费图书推荐页",发现URL是这样的:
http://www.ituring.com.cn/book?tab=free&sort=vote
2.确定URL情况:
1.请求URLhttp://www.ituring.com.cn 2.参数book?tab=free&sort=vote 3.header,这个根据情况可以不需要
3.确定初始进入页的页面布局
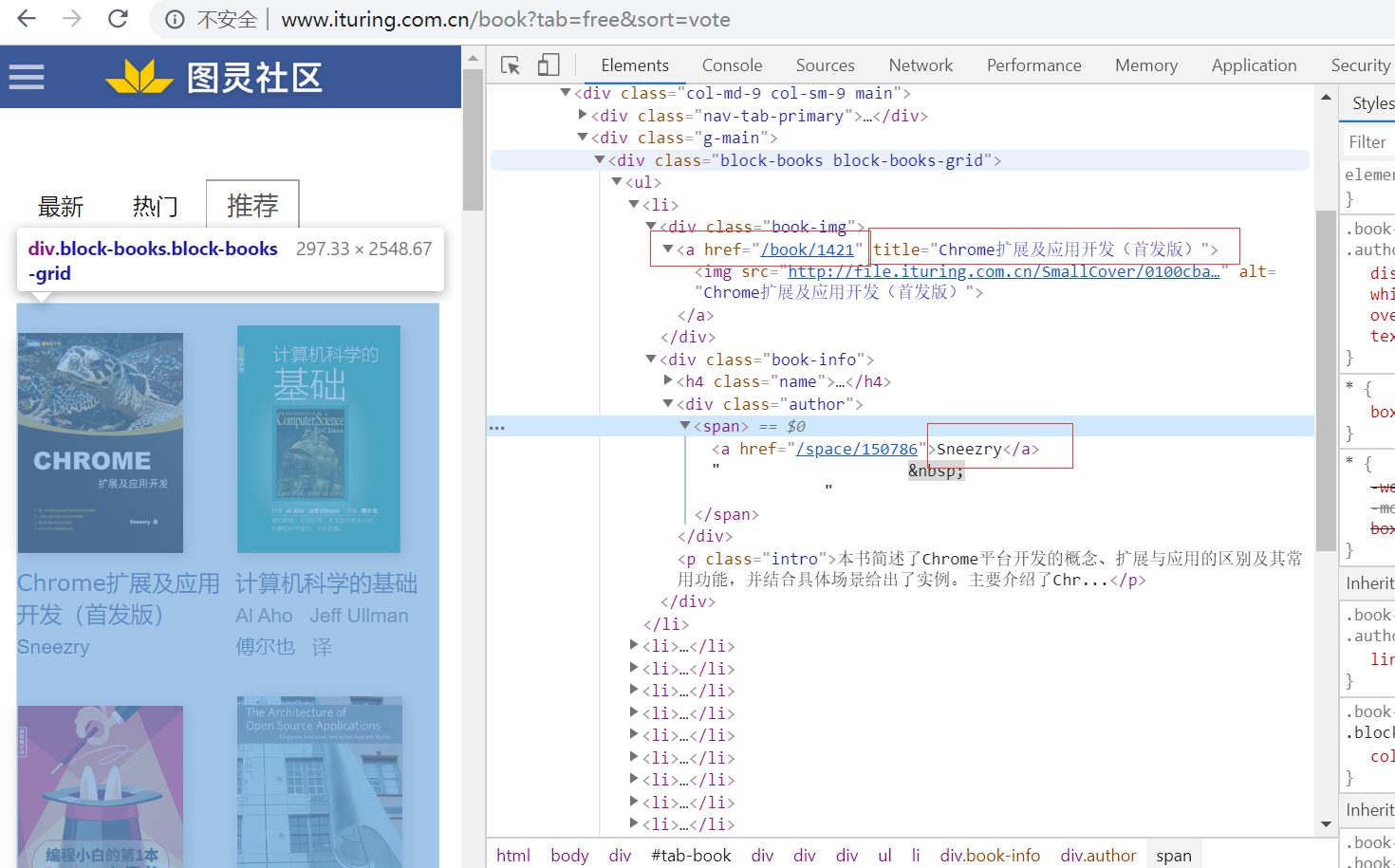
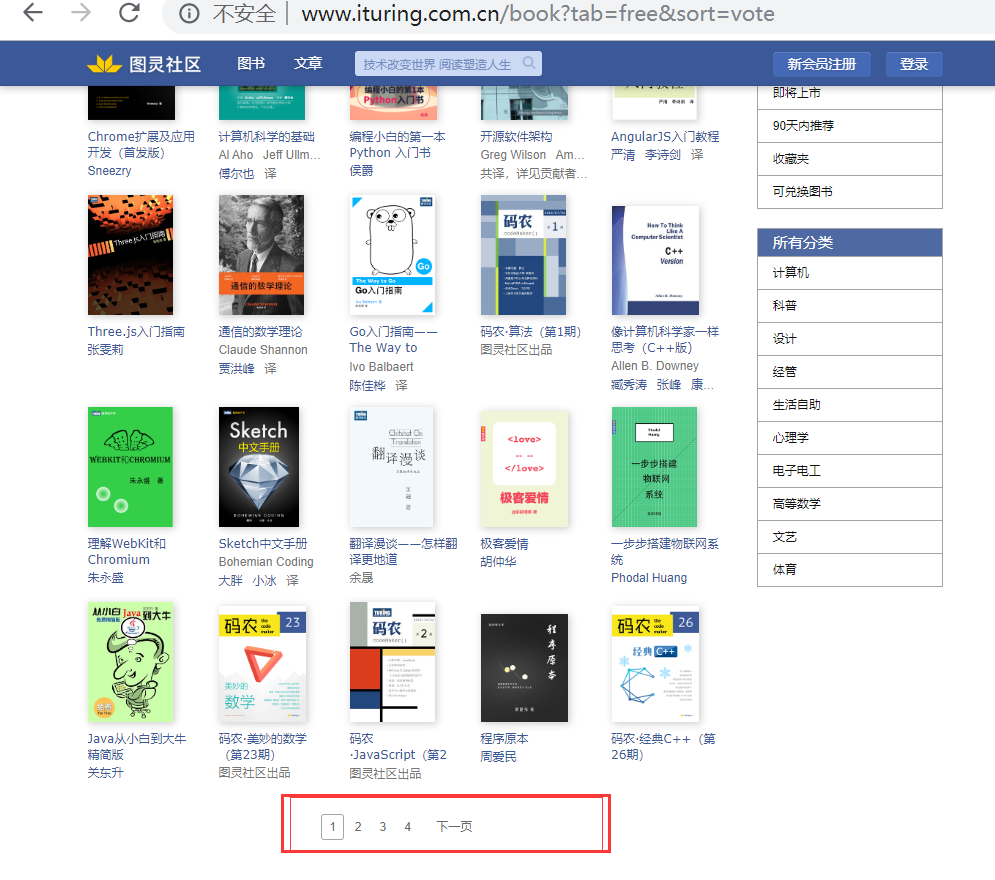
>a.注意底下的页面数值
>b.注意红框圈出的,我们需要的数据
>c.第一个<a href>这个是我们进入该书详情的一个url地址,进入是这样的:(介绍书的详情,并有目录结构)

>d.第一个<a title>是书的名称
>e.第二个<a>上的文本是作者的名字
4.根据(3)获取到的信息,进入(3-a)得到的页面数值,即翻页数,这个的作用在于:第(2)点说的参数
我们可以打开F12开发者模式,选择console来获取数值,如下:
$(".PagedList-skipToPage")
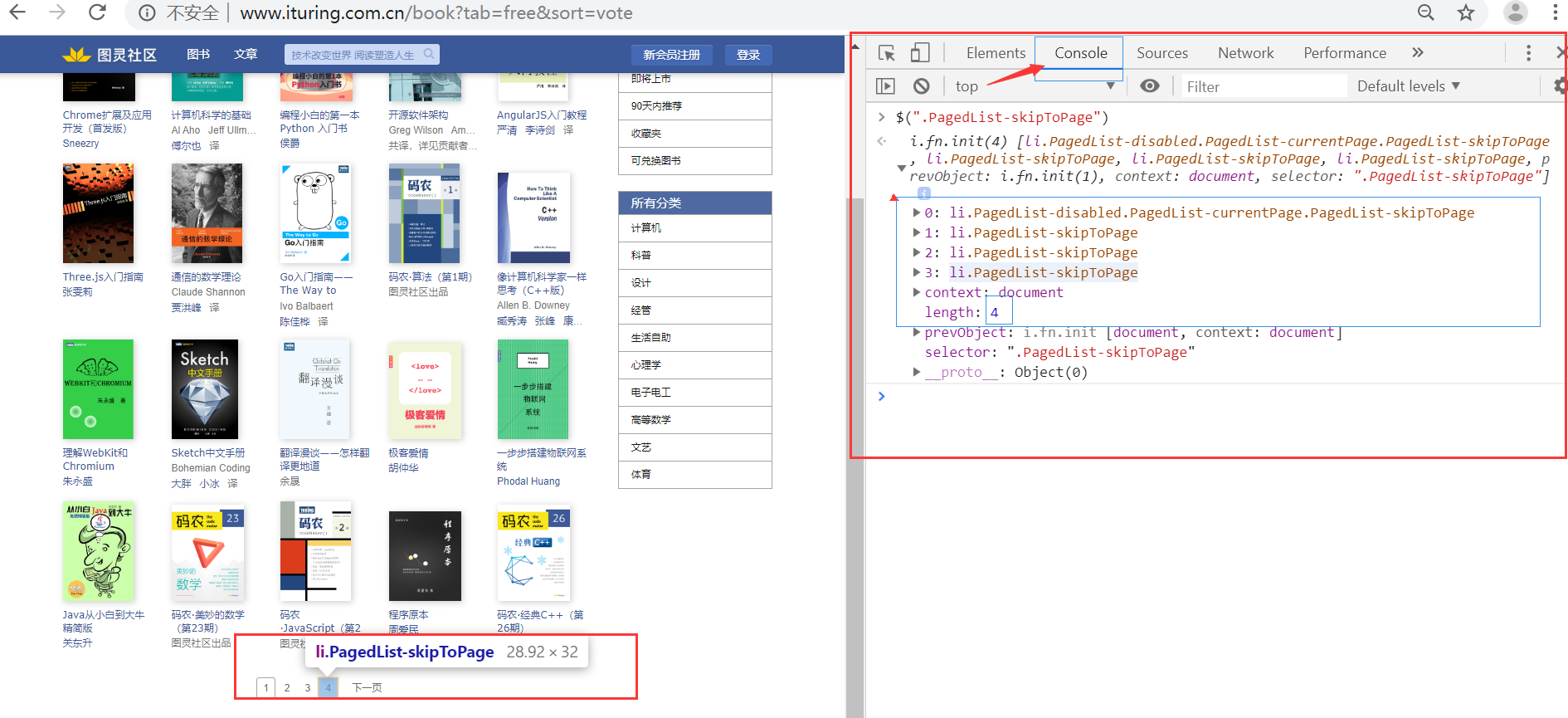
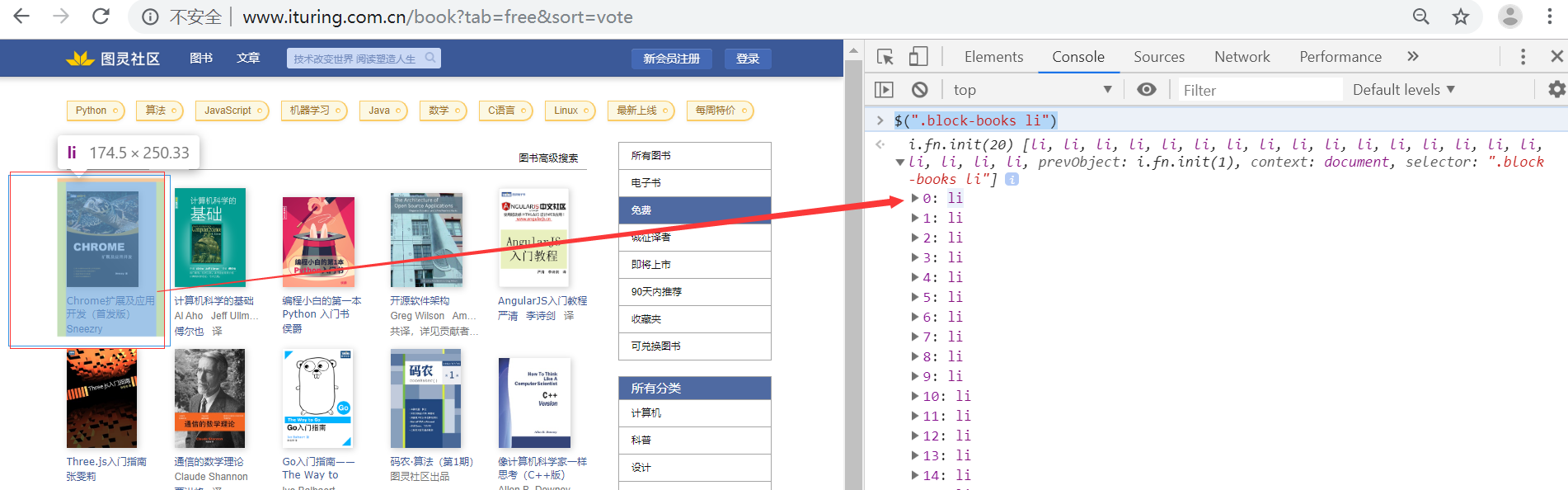
5.根据(3)获取到的信息,进入(3-b)获取进入书籍详细介绍的URL/书名等信息如下:
$(".block-books li")
界面如下:
6.根据(3)获取到的URL进入详情页,分析详情页页面
7.在详情页页面我们主要是想获取目录的URL,如下:
$(".table tr")
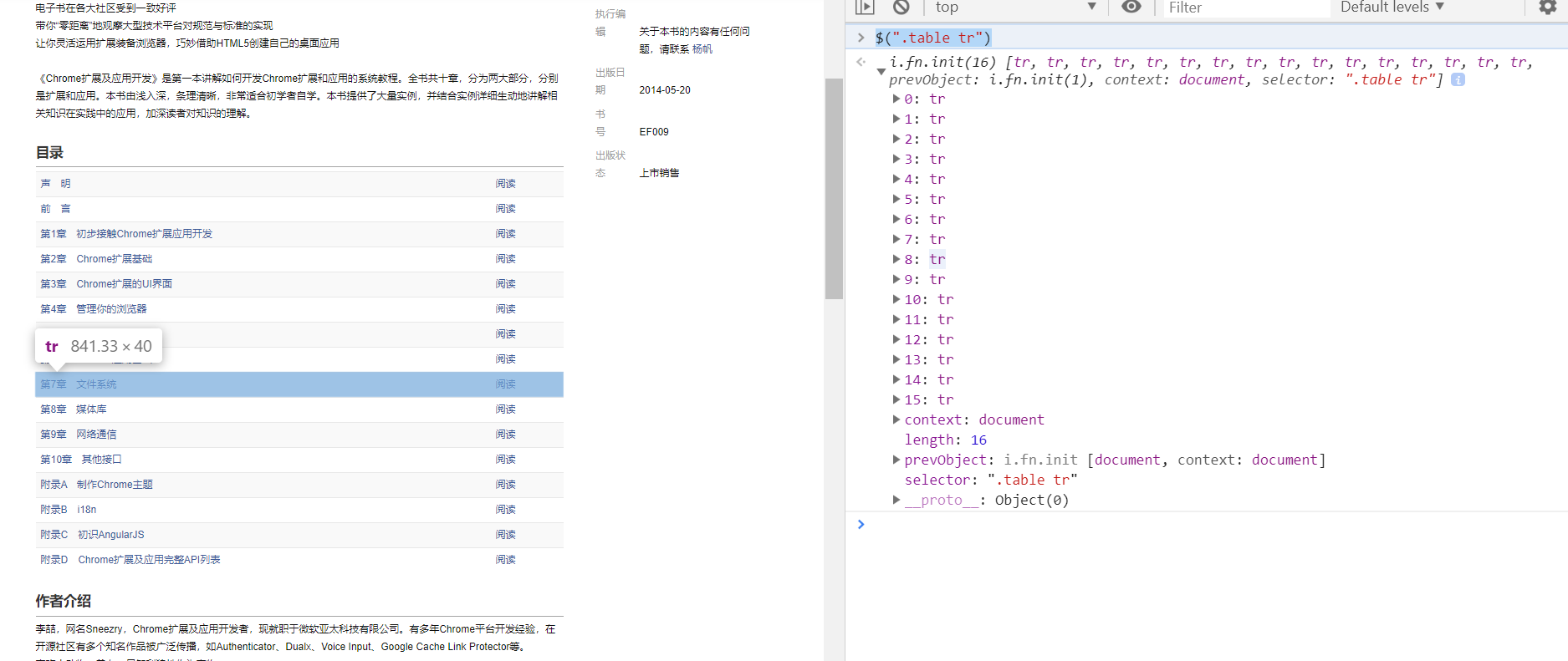
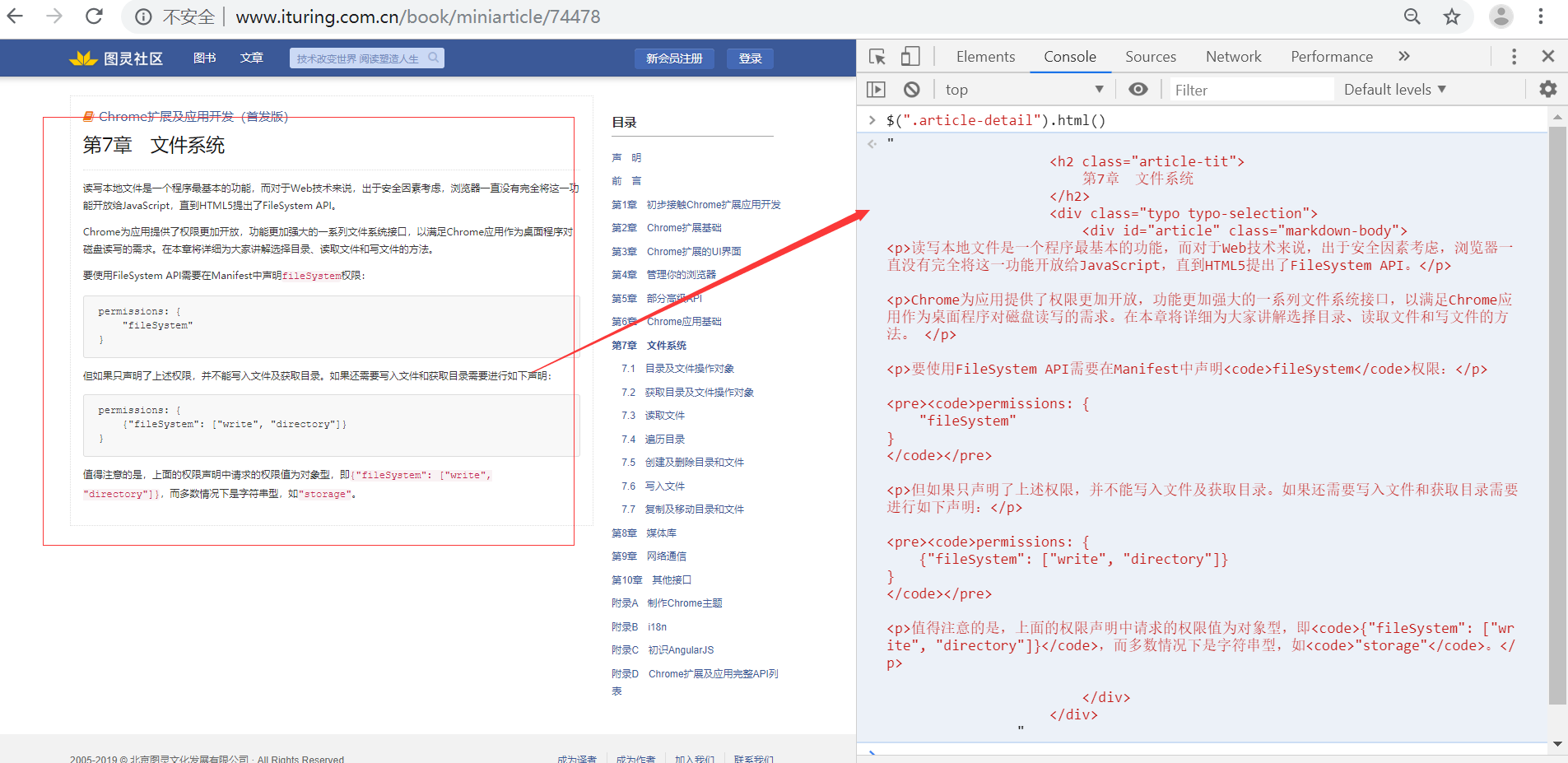
8.根据(7)获取的目录URL,进入内容详情页,分析内容详情页:
$(".article-detail").html()
三.总结
以上.就是网站分析的结果,下节会有演示展示~
即:代码编写的分析~
如果你喜欢,请关注公众号哦~,谢谢~