原创作品,可以转载,但是请标注出处地址:http://www.cnblogs.com/V1haoge/p/7004474.html
1、日期与字符串之间的转换
1 public static void main(String[] args) { 2 Date now = new Date(); 3 String d = "2017-06-13 23:23:23"; 4 5 System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(now)); 6 try { 7 System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(d)); 8 } catch (ParseException e) { 9 e.printStackTrace(); 10 } 11 }
结果:
2017-06-13 23:31:12
Tue Jun 13 23:23:23 GMT+08:00 2017
2、数值字符串格式化
1 public static void main(String[] args) { 2 Double d = 1234567890.5512d; 3 System.out.println(String.format("%,.2f", d)); 4 }
结果:
1,234,567,890.55
3、日期字符串格式化
1 public static void main(String[] args) { 2 Date now = new Date(); 3 System.out.println(String.format("%tc", now)); 4 System.out.println(String.format("%tF", now)); 5 System.out.println(String.format("%tD", now)); 6 System.out.println(String.format("%tr", now)); 7 System.out.println(String.format("%tT", now)); 8 System.out.println(String.format("%tR", now)); 9 System.out.println(String.format("%1$tF %2$tT", now,now)); 10 System.out.printf("%tc%n",now); 11 System.out.printf("%tT%n",now); 12 System.out.printf("%1$s %2$tb %2$te,%2$tY%n","date:",now); 13 System.out.printf("%1$tF %2$tT",now,now); 14 }
结果:
星期三 六月 14 01:29:40 GMT+08:00 2017 2017-06-14 06/14/17 01:29:40 上午 01:29:40 01:29 2017-06-14 01:29:40 星期三 六月 14 01:29:40 GMT+08:00 2017 01:29:40 date: 六月 14,2017 2017-06-14 01:29:40
4、B树与B+树区别,B*树
我们知道B树和B+树是用于数据库实现索引的数据结构,是平衡二叉树的衍生树,又称为平衡多路查找树,其中B就是平衡之意。
B树:每个关键字只会出现一次,每个关键字都拥有指向数据的指针,节点的关键字数量总是比子节点数量少1。
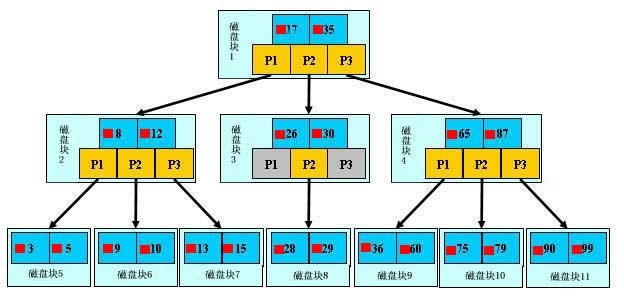
B+树:每个关键字都会在叶子节点中出现,非叶子节点中的关键字没有指向数据的指针,节点的关键字数量与子节点数量相同。叶子节点是按序排列的。
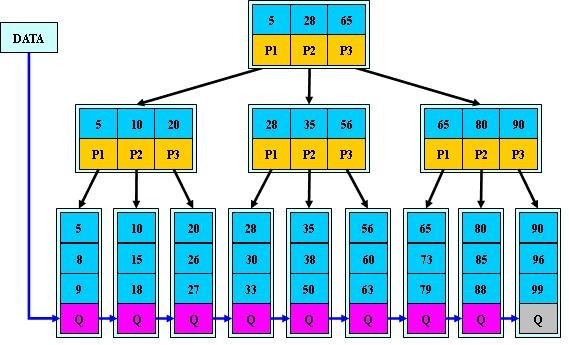
B*树是对B+树的再扩展,在每个非根节点和非叶节点上新增指向兄弟节点的指针,便于数据增加和删除,更适合作为索引数据结构。
5、VM虚拟机安装docker中部署springboot项目
由于springbooot项目启动的时候默认的端口是8080,这个8008是docker内部的虚拟端口,创建项目镜像容器的时候需要将其映射到VM虚拟机的某个端口上,这样就能在宿主机浏览器中访问部署项目的接口了。
docker run -d --name boot1 -p 8000:8080 boot/boot
解释:boot1是新建容器名称,
-p 8000:8080 将docker中的8080端口映射到VM虚拟机中的8000接口中
boot/boot 是镜像名称
6、instanceof方法的使用
instanceof()用于判断前面的引用类型(实例)是否是括号中类类型、其子类型、实现类的实例。一般用于类型强制转换之前,判断前一个对象是否是后面类的实例,是否可以成功进行转换,从而保证代码的健壮性。
1 String s = "123"; 2 if(s instanceof String && s instanceof Object){ 3 System.out.println(true); 4 }
7、Duration
Duration表示的是持续的一段时间,用于表示时间段(或一段时间)。
between方法可以获取两个时间点之间的时间段,
toXXX方法可以将时间段以某种单位表示,
toDays():天数表示
toHours():小时表示
toMinutes():分钟表示
toMillis():毫秒表示
toNanos():微秒表示
1 LocalDateTime now = LocalDateTime.now(); 2 System.out.println(Duration.between(now,now.plusDays(1)).toMinutes());
结果是60.
8、Spring中@PostConstruct注解的操做在Bean的@Autowired注入操作之后,而@Autowired操作又在构造器创建Bean对象之后,所以:
构造器 > @Autowired > @PostConstruct
9、锁
线程获取synchronized锁时,锁已被持有的情况下,该线程会进入阻塞状态,而获取LOCK锁的时候,则会进入wait状态。
Object.wait()方法会释放锁,而Thread.sleep()方法并不会释放锁,其沉睡若干时间后可立即恢复运行。而wait的线程被唤醒之后需要重新获取锁进行。
对一个线程进行中断,如果线程被wait方法、join方法、sleep方法等造成阻塞,这时候会清除线程的中断状态,并会抛出InterruptedException异常。
如果中断一个不存活的线程(比如已完成的或者为启动的线程)是没有任何效果的。
10、线程阻塞
线程可以阻塞于四种状态:
1)、当线程执行Thread.sleep()时,它一直阻塞到指定的毫秒时间之后,或者阻塞被另一个线程打断;
2)、当线程碰到一条wait()语句时,它会一直阻塞到接到通知(notify())、被中断或经过了指定毫秒时间为止(若制定了超时值的话)
3)、线程阻塞与不同I/O的方式有多种。常见的一种方式是InputStream的read()方法,该方法一直阻塞到从流中读取一个字节的数据为止,它可以无限阻塞,因此不能指定超时时间;
4)、线程也可以阻塞等待获取某个对象锁的排他性访问权限(即等待获得synchronized语句必须的锁时阻塞)。
注意,并非所有的阻塞状态都是可中断的,以上阻塞状态的前两种可以被中断,后两种不会对中断做出反应
11、日志框架两大阵营
Jul(java内部提供的日志接口,模仿Log4j开发,Commons Logging的具体实现)
Apache阵营(Commons Logging阵营)
Commons Logging(门面)
Log4j(Commons Logging的具体实现)
Log4j2(Log4j的升级版,具有logback的所有特性)
slf4j阵营(SLF4J阵营)
Slf4j(门面)
Logback(Slf4j的具体实现)
新项目之中推荐使用Slf4j和Logback组合。
12、ConcurrentHashMap和HashMap
HashMap:
1.7版本
默认初始容量为16 默认扩容因子为0.75 最大容量为1 << 30(2的幂次方) 结构:数组+单向链表 节点结构:key,value,hash值,next指针 扩容方式:2倍扩容 扩容条件:插入新值时,如果size达阈值并且当前下标链表不为空,即已有Entry保存的情况 put操作:首先通过对key取Hash值,定位节点下标,然后将节点保存到下标所在链表结构头部. 注意:首次put元素时,需要进行数组初始化,HashMap允许null的key,一律保存于数组首位链表中,但是一个HashMap中只允许一个NUllkey get操作:首先对key取Hash值,定位数组下标,然后遍历该下标链表找寻指定key的Entry。
ConcurrentHashMap:
1.7版本
Segment:分段锁(锁分段技术)每个Segment就好像是一个HashMap结构,不过要考虑并发性。ConcurrentHashMap将一整个HashMap进行分段,每一段指定给一个Segment,然后对每个Segment进行加锁,加锁的方式是继承ReentrantLock实现的。 默认的锁数量为16(即Segment数组容量默认为16) 默认扩容因子为0.75 map的总容量默认为16 每个Segment最小的容量为2(默认为2) Map的最大容量为1 << 30(2的幂次方)(此为所有Segment容量之和,每个Segment会平均分配这个容量) 节点结构:key,value,hash值,next指针 结构:分段数组+单向链表 扩容方式:2倍扩容 扩容条件:插入新值时,容量达到阀值(这里的容量和阀值针对的是当前Segment,而非整个table)
注意:Segment数组容量是不能扩容的,一旦初始化就不再发生变化,但是Segment内部的结构是可以扩容的,扩容的条件的容量与阀值的比较,这个容量是当前Segment中保存的HashEntry的数量count值 put操作:首先定位Segment下标,然后定位内部数组下标,最后保存到指定位置的链表中。首先计算key的hash值(算法复杂于HashMap),首次在某个Segment下标中添加内容时,是需要初始化该Segment的,二次以上不用,初始化完成后就可以执行Segment内部的put操作。Segment内部put操作首先需要持有该Segment锁,然后计算内部数组下标,根据下标找到指定的链表,然后分两种情况进行处理,首次添加到该链表和非首次添加到该链表。新Entry保存到链表头部,最后释放锁。 注意:在Segment内部put时,如果容量达到阈值,则进行扩容操作。 get操作:并不需要任何加锁操作,靠CAS操作和volatile实现并发同步操作。
加锁方式:首先进行尝试加锁(tryLock()),如果当前锁并不被任何线程持有,可以直接获取到锁,但如果锁已被其他线程持有,这时候自旋一定次数来循环获取锁,期间锁被释放,当前线程可以竞争获取锁,当如果一直未获取到锁(锁未释放或者锁被释放但未争到锁),自旋次数达到指定次数后,当前线程被挂起等待被唤醒。
13、递归
发现那,递归调用的前后所处的场景是不同的,递归调用之前的逻辑时调用之前的逻辑,之后的逻辑却是递归调用返回后执行的逻辑,要明白这种场景区别,才能更好地使用递归。
虽然场景不同,但都是在当前调用栈内执行的,递归就好比调用栈的嵌套。
一般正常逻辑都放在调用发生之前执行,调用之后执行的一般都是回退性质的逻辑,但却是功能实现上必不可少的一部分。
14、spring
最近看看Spring的源码,做点记录
Spring的重点:IOC容器实现、AOP功能实现
Spring源码研究入口:
IOC容器的创建初始化:
SpringBoot项目可以从main方法开始。
web项目要以ContextLoaderListener的初始化方法开始,这个方法是在Servlet容器创建后自动调用的。当然入口是在web.xml中配置的。
还可以以编程的方式来开始,最常使用的是XMLBeanFactory(已弃用),FileSystemXmlApplicationContext均可以作为入口。
Bean的实例化和属性注入:
在getBean方法获取该Bean实例的时候触发,配置了lazy-init的Bean才会如此,如果其值为false,这个Bean在加载完成后就会完成实例化。
15、架构的理解
Java中的架构,一般是采用各种设计模式来实现的,而设计模式又是通过java的各种功能机制来实现的。
因此,在一个架构中,或者是一个设计模式中,通常会因为设计的原因,出现一些在功能上比较多余的类或接口,而且还有很多,但是这些类或接口在架构中却起着不可或缺的作用。
可以这么说,java提供了继承、多态、接口、抽象类等机制为设计模式的产生,为架构的产生提供了土壤,尤其是面向对象的特性。
架构是一系列功能的合集,通过这些功能的整合,发挥出了闪亮的光辉,实现了诸如解耦、高可用、高扩展等特性,而这些都体现在那些个设计模式之中。
设计模式可以看成是对java特性的深度利用,当你非常深刻的了解了java的各种特性之后,其实各种设计模式都是信手拈来的,不到这个程度,就说明你还没有达到深度理解java特线性的程度。
设计模式信手拈来,那可能是架构师的神技了,所谓无招胜有招的程度,达到将所有设计模式都忘记的程度,融汇所有的java特性,信手拈来。
16、ThreadLocal理解
ThreadLocal是java用来解决并发问题的类,但貌似现在变成了一个线程传参工具。。。
使用方法:我们自己定义一个含有ThreadLocal属性的类,并为其提供set、get方法,用于操控,主要内容是,我们需要重写其initialValue方法(初始化值)。如下:
1 public class MyThreadLocal { 2 private ThreadLocal<Integer> local = new ThreadLocal<Integer>(){ 3 @Override 4 protected Integer initialValue() { 5 return 11; 6 } 7 }; 8 9 public Integer getNum() { 10 return local.get(); 11 } 12 13 public void setNum(Integer num) { 14 local.set(num); 15 } 16 }
原理简述:ThreadLocal是通过为每个线程提供一个变量副本的方式来解决并发情况下针对共享变量的访问的。
在Thread里面有一个ThreadLocal.ThreadLocalMap类型的属性,这个属性用于存储线程中的变量副本,因为一个线程可能包含多个ThreadLocal变量,所以这里使用Map来进行保存,键值分别是以ThreadLocal对象为键,以变量副本为值。
我们定义了一个ThreadLocal变量之后,可以通过其set或者get方式为当前线程创建一个变量副本,即将该ThreadLocal变量创建一个副本保存到当前线程的ThreadLocal.ThreadLcoalMap属性中。主要我们不执行remove操作,那么这个变量会常驻该线程,我们可以在需要的时候直接get获取。
1 public class ThreadLocalUse { 2 3 public static void main(String[] args){ 4 MyThreadLocal myThreadLocal = new MyThreadLocal(); 5 myThreadLocal.setNum(90); 6 int s= myThreadLocal.getNum(); 7 } 8 9 }
17、java泛型
java泛型在1.5版本中添加,主要用于解决类似于集合框架中确保其中保存的元素的一致性(强制性保证,不一致的情况下无法通过编译)。
集合框架都进行了泛型化,我们定义一个执行参数化类型的集合之后,在这个集合中就只能存放这种类型的元素,这个是在编译期有效的。
泛型也可以看成是一种语法糖,只在编译期生效,编译之后,就会将其去除,俗名:类型擦除。
因此,不同类型参数的同种集合在进行原始类类型比较时,得出的结果是true:
1 public static void main(String[] args){ 2 Box<String> box1 = new BoxA<>(); 3 Box<Integer> box2 = new BoxA<>(); 4 System.out.println(box1.getClass() == box2.getClass()); 5 System.out.println(box1.getClass().equals(box2.getClass())); 6 }
结果:


true true
如此我们可以总结,泛型就是一种语法糖,一种语法上的约束,一种在编译期保证同一集合中保存元素类型一致的约束。这种约束在编译期有效,编译完成会擦除,因为它已经没有存在的必要了。
泛型类、泛型接口
泛型类和泛型接口最典型的应用就是集合类库中的各个类和接口。
定义泛型类和接口,需要使用<>来声明泛型类型,类型一般使用T、E、K、V等。
1 public class Box<T> { 2 }
上面是一个简单的泛型类,泛型类型为T。
1 interface Map<K,V>{ 2 }
这是一个简单的泛型接口,其中K和V均是泛型类型。
泛型方法
泛型方法是在那些在方法中使用<>的方式声明了泛型类型的方法,并不是所有在方法中出现泛型类型的都是泛型方法。
1 class BoxA<T> extends Box<T> { 2 public T getInstance(){ 3 return (T)new BoxA<>(); 4 } 5 }
上面的getInstance就不是泛型方法,虽然其中包含泛型T,但这个泛型类型是在泛型类中声明的,而不是在该方法中声明的。
1 class BoxA<T> extends Box<T> { 2 public T getInstance(){ 3 return (T)new BoxA<>(); 4 } 5 public <E> E getInstance2(){ 6 E e = (E)new BoxA<T>(); 7 return e; 8 } 9 10 public <S> void doSting(S s){ 11 System.out.println(s.toString()); 12 } 13 }
上面的getInstance2和doSting方法都是泛型方法,因为在这两个方法中都自主声明了泛型<E>和<S>。
泛型的使用
泛型类和接口的使用:参数化类型可以使用任意类型进行替换,每种类型衍生的类型都是一种新类型,使用的时候,只要用要替换的类型替换<>之间的参数类型即可。
泛型方法的调用:同样使用参数类型进行<>之间类型的替换,使用方式如下:
1 public static void main(String[] args){ 2 BoxA<String> box4 = new BoxA<>(); 3 box4.doSting(new BoxB()); 4 box4.<String>doSting("121212"); 5 }
第4行的<String>是可以省略的。
List<Object>和List<String>的关系
虽然Object是String的超类,但是我们却不能将后者强转为前者,因为类型的强转一般发生在具有继承关系的两种类型之间,没有继承关系的类型强转无法通过编译,那么此处List<Object>和List<String>并不是继承关系,因为后者并不是通过继承前者得来的,所以二者不能进行强转。
Object和String都只是参数类型,而不是主类型,主类型为List,主类型相同,由参数类型进行区分,导致二者不同,这个不同只是编译期不同,编译期之后,类型参数被擦除,二者都是List类型。
二者都是通过选取不同的参数类型从同一主类型衍生而来的新类型,并不存在任何继承关系,确实不能进行强转。
18、HttpServletResponse.sendRedirect与RequestDispatcher.forward实现页面跳转
前者属于重新发起的页面请求,拥有更两个请求,前后两个请求,分别拥有自己的request和response,流程:页面请求servlet,发现sendRedirect()重定向,将指定的URL返回浏览器,由浏览器发起对新URL的请求,再返回目标页面。重定向可以重定向到网络中任一地址。
后者属于一次请求,页面UrL不发生变化,只是请求转发,只拥有一套request和response,流程:页面请求Servlet,发现forward转发,由Servlet进行请求转发,最后由Servlet返回页面。转发只能转发到当前应用中的其他路径。
19、JDK8中的新功能之一:Lambda表达式
Lambda表达式一般和函数接口一起使用,Lambda表达式可以看成是函数接口类型,也就是说我们可以将一个Lambda表达式赋值给一个函数接口,但是谨记,我们不能将一个Lambda表达式赋值给Object,因为Object并不是函数接口。
Lambda的使用方式:
遍历集合:forEach
替换匿名内部类(配合函数接口使用)
注意:为了兼容java的老方法,jdk8定义了许多函数接口用于转换,我们要使用Lambda,必然需要函数接口,我们是需要将Lambda表达式赋值给函数式接口的,然后使用反函数接口包装原有类进行转换。毕竟函数式编程和面向对象明显不是一个道上的,需要一个转换器。
20、JDK8中的新功能之一:方法引用
方法引用是对Lambda表达式的再简化,说到底我们使用Lambda表达式的目的就是实现将函数(方法、功能)作为参数进行传递,通过方法引用我们可以直接使用已定义的方法。
21、枚举
枚举自动继承Enum类,基于Java的单继承机制,我们定义枚举不能继承其他类,但确是可以实现多个接口;
我们可以在枚举中自定义构造器,但是枚举的构造器被限制为只有编译器才能调用,即使反射技术也被限制无法调用枚举内部的构造器;
在枚举中我们可以定义抽象方法,然后在每个枚举值内部实现这个方法,类似于泛型机制。
其实枚举就是一个构造器被限制的类。
22、Spring MVC中ServletContext,Servlet,ServletConfig的关系
ServletContext:可以看成是应用本身,即应用上下文,也叫Servlet容器,用于存放Servlet的容器
Servlet:具体的Servlet,每个Servlet生成的时候必定携带一个ServletConfig
ServletConfig:与Servlet配对,一对一,ServletConfig的内容在Servlet生成的时候被设置成功,之后无法进行更改(新增或者更新或者删除)
Servlet继承关系:
Servlet->GenericServlet->HttpServlet->HttpServletBean->FrameworkServlet->DispatcherServlet
另外:ServletConfig->GenericServlet
前三个是Tomcat中的Servlet系统,后面三个是Spring中的Servlet系统,最终是我们最熟悉的DispatchServlet。
23、DispatchServlet处理请求
其实请求是由Server拦截获取,即Servlet Containor(Servlet容器)。
server接收到请求就会将其交由Servlet的service方法,HttpServlet中的service方法会被触发执行,触发另外一个重载的service方法,并将请求和响应转换为HttpServletRequest和HttpServletResponse类型。这个service就会根据请求中的内容,具体是请求类型来进行请求分发,将请求交给对应的doXXX方法进行处理,而Spring MVC在FrameworkServlet中重写了doXXX方法,所以最后会触发这些方法,然后调用processRequest方法,再调用DispatchServlet中的doService方法,再调用doDispatch方法进行请求的再次分发,这次分发只针对handler。
24、Spring web项目启动及关系
项目启动会触发ServletContext的创建,解析<context-param></context-param>节点,将其保存到ServletContext中,然后web.xml中配置的ContextLoaderListener继承自ServletContextListener,会监听到ServletContext的创建动作,然后执contextInitialized方法进行ServletContext初始化操作,这些操作就是有ContextLoaderListener中的contextInitialized定义的操作。创建应用级的Spring IOC容器:WebApplicationContext,一般用的是XmlWebApplicationContext,并将其保存到ServletContext中。
然后注册所有过滤器。
再然后执行Servlet创建,这里指的就是DisPatcherServlet了。
25、针对函数式编程的理解
方法的签名指的是其修饰符、返回类型、方法名、参数类型、异常申明等信息。
函数式编程中必须确保Lambda表达式、方法引用和函数式接口的唯一抽象方法的方法签名一致。也就是说:要保证Lambda表达式和方法引用的方法时函数式接口抽象方法的实现,这种实现不同于接口的实现,因为针对方法引用的情况这个方法的实现可能在任意类中,而不一定是实现函数式接口的类。而对于Lambda表达式就简单了,那就是匿名内部类的简化形式而已,我们编写匿名内部类时必然要实现接口中的所有方法,函数式接口只有一个抽象方法,我们只要实现它就行,所以直接简化成Lambda表达式,省略接口名与方法名的申明,毕竟只有一个,不写也是那一个方法。而方法引用的方法就是将实现逻辑迁移到其他类中的一个具体方法中,需要使用的时候直接引用即可。
说了这么多,也就是说Lambda和方法引用的签名必须要与函数式接口的唯一抽象方法一致。
相信,这也就是Java中函数式接口实现的根本了。
26、集合置空
当我们在程序中频繁创建使用集合时,最好在集合使用完后对其进行手动释放,就是置为null或者调用clear,这样可以将该集合所引用的堆内存释放掉(在下次GC时被回收),避免在方法未结束之前无用的集合长时间占用空间。
这种情况主要针对的是那些运行时间比较长的方法,比如需要访问三方,甚至多次访问三方,需要进行复杂的计算,需要进行多次循环的场景。如果方法运行很快结束,没有必要手动释放,当方法结束时自然就释放了。