SpringCloud-Netflix(Usage of Hystrix)
有时候一个前端传递过来的请求,有可能涉及到后端的多个微服务之间的调用,然而,在微服务调用的时候,有可能某个微服务宕机,或者因为网络原因在很长时间无法返回资源,那么整个系统资源将会被快速消耗,甚至是造成整个系统服务雪崩。所以为了解决这些问题,就引入了服务熔断和服务降级
- 【服务熔断】:如果目标服务调用时间比较慢,或者大量的超时,那后续的请求将不会继续请求目标服务,而是直接返回降级的逻辑。当目标服务恢复后,熔断机制则会自动关闭。
- 【服务降级】:简而言之,就是,当主方案行不通的时候,我们改用备用方案。比如服务A调用服务B的时候,而B服务宕机了,从而导致了请求失败。那我们就可以返回一个“系统繁忙”或者“服务正在开发中”这样的字样给到用户,这种就数据服务降级。实际上降级,还分为主动降级和被动降级
- 【主动降级】:当某个服务的并发很大的时候,把一些无关紧要的服务关闭。
- 【被动降级】:如果服务调用异常,那我们就返回一个备用的数据,就像上面的例子。返回系统繁忙。
为了解决分布式架构下服务熔断问题,SpringCloud Netflix集成了一个hystrix组件,他的作用是,对某个服务的调用在一定时间内,超过一定次数,并且失败率超过一定值,该服务的熔断将会自动打开,并且执行一个由我们自己编写的一个fallback。本篇我会聊它的使用和设计原理,后面聊完Netflix的这一套使用后,则会聊它的源码。
Usage of Hystrix(alone)
我们现在有个统一的api工程,当前端调用api工程的时候,api使用resttemplate远程调用订单的微服务,然后我们在订单的微服务中让线程睡3s(用来模拟服务端返回慢),然后我们设置响应时间为1s,看看加入hystrix后会不会熔断。
统一的api模块中增加hystrix的pom
 View Code
View Code<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency>订单的微服务模块中增加一个接口模拟订单创建,并且在接口中睡3s
View Code@RestController public class OrderController { @GetMapping("orders") public String hystrixDemo(){ try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } return "success"; } }在统一的api中远程调用订单模块,并且增加hystrix配置(在5s内,超过20次请求,并且失败率超过50%,则默认触发熔断)
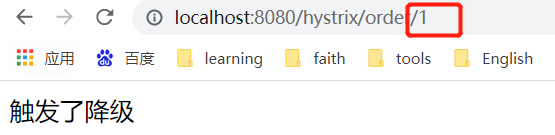
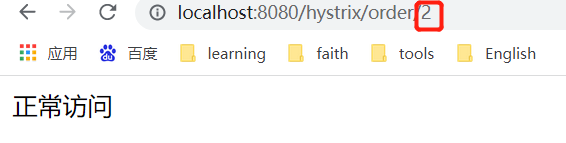
View Code@RestController public class HystrixController { @Autowired private RestTemplate restTemplate; // HystrixCommandProperties @HystrixCommand(commandProperties = { //最小请求阈值(当在配置时间窗口内达到此数量的失败后,进行短路) @HystrixProperty(name="circuitBreaker.requestVolumeThreshold",value ="10"), //睡眠时间窗口(触发熔断后等待的时间) @HystrixProperty(name="circuitBreaker.sleepWindowInMilliseconds",value ="5000"), //错误百分比 @HystrixProperty(name="circuitBreaker.errorThresholdPercentage",value ="50") },fallbackMethod = "fallback") @GetMapping("/hystrix/order/{num}") public String hystrix(@PathVariable("num") int num){ if (num%2==0){ return "正常访问"; } return restTemplate.getForObject("http://localhost:9092/orders",String.class); } //我们在orderService中睡眠了3s,而默认的超时时间是1s,那这个时候就自动触发了服务降级 public String fallback(int num){ return "触发了降级"; } }我们这里用num来控制正常访问,如果输入的num是2则返回正常访问。如果是1的话则会真正调用订单的微服务,而订单的微服务睡了3s所以肯定会对服务进行降级。
当我们连续调用订单模块之后,我们发现,使用num=2进行正常调用,则发现订单模块的微服务已经被熔断了。因为我们上面配置了5s,5s后我们再次请求num=2发现服务又自动恢复了。


Usage of Hystrix(integrate with openfeign)
我们还是使用统一api模块去调用各个微服务。
首先还是在统一的api模块中引入hystrix的pom
View Code<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency>并且在配置文件中加上【feign.hystrix.enabled=true】
新建一个类(实现前面继承商品接口的标注FeignClient注解的类),并且重写方法,用于返回服务降级的信息
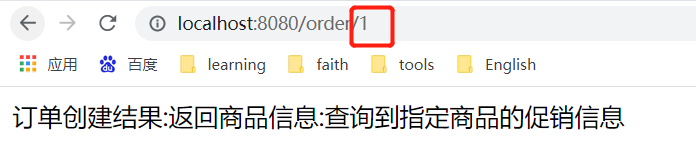
View Code//当feign触发了降级之后,他需要返回降级的消息,这个类会在标注了FeignClient的类上作为属性 public class GoodsServiceFallBack implements IGoodsServiceFeignClient { @Override public String getGoodsById(int id) { return "查询商品信息异常,Hystrix触发了降级保护机制"; } }并且把这个类交给spring进行托管。
View Code@Configuration public class HystrixConfiguration { @Bean public GoodsServiceFallBack goodsServiceFallBack() { return new GoodsServiceFallBack(); } }在商品模块中用外面传递的数字模拟控制服务响应慢
View Code/** * 根据ID查询商品信息 * @return */ @GetMapping("/goods") public String getGoodsById(int id){ log.info("收到请求,端口为:{}",port); //这里也是为了模拟服务响应超时 if (id%2==0){ try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } } return "返回商品信息"; }当我们对一个服务多次访问失败的情况下,这个服务就会自动降级


Principle of Hystrix
Hystrix默认10s内达到20次请求,并且超过50%的请求是失败的,那么就会触发熔断,熔断后,在5s内,请求不会落到目标请求上去,而是直接返回fallback给到客户端。
熔断状态:
Open: 意味着接下来的请求不会发送到服务端 ,而是直接返回fallback
Closed:服务通信正常
Half-Open:熔断的自动恢复机制
熔断的原理:
当一个请求过来后,判断是否触发了熔断,如果已经触发了熔断,那就返回服务降级的逻辑,如果没有那就对当前时间窗口(底层使用了滑动窗口对数据进行了统计)的健康请求数量进行检查,判断是否大于20次,如果大于20次,那就去汇总总的错误数量,如果大于50%则开启熔断
