分布式存储-ShardingSphere 分布式治理 (based on zookeeper)
其实前面几篇,关于shardingSphere的我知道的功能点已经聊得差不多了,但是现在多节点集群部署的方式已经成为了一种趋势,而如果每个节点中的配置文件都需要手动一个个修改的话,那将为运维工作带来了很大的不愉快,所有ShardingShere内部整合了Zk,实现了配置文件的动态配置。本篇主要聊聊:
- ShardingSphere整合zookeeper的配置动态更新。
- zookeeper的大体介绍
ShardingSphere和Zk实现(一处修改配置文件,多处通过感知)
首先导入pom
 View Code
View Code<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>shardingsphere-governance-repository-zookeeper-curator</artifactId> <version>5.0.0-alpha</version> </dependency> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>shardingsphere-jdbc-governance-spring-boot-starter</artifactId> <version>5.0.0-alpha</version> <exclusions> <exclusion> <groupId>org.apache.shardingsphere</groupId> <artifactId>shardingsphere-test</artifactId> </exclusion> </exclusions> </dependency>然后在application文件中加上zk的路径和配置
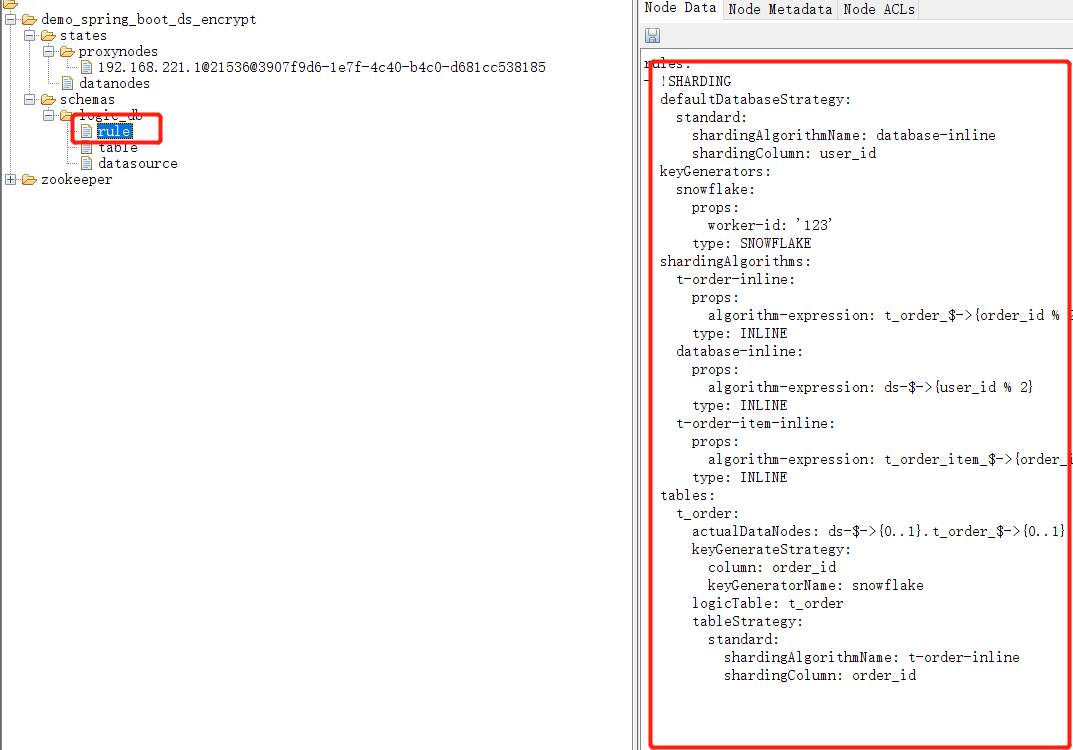
View Codespring.shardingsphere.governance.registry-center.type=ZooKeeper spring.shardingsphere.governance.registry-center.server-lists=192.168.43.3:2181 spring.shardingsphere.governance.registry-center.props.maxRetries=4 spring.shardingsphere.governance.registry-center.props.retryIntervalMilliseconds=6000【这个时候application中还有咱们对shardingSphere的配置,因为在初始化的时候,shardingSphere会把和它相关的配置变成yml传递到zk上,我们以后只要修改zk上面rule下面的配置就可以被shardingShpere感知了!】
当我们修改zk上的信息的时候,我们本地就动态感知了。
问题来了,sharingSphere为啥就要用zk呢,zk为啥这么受欢迎?下面我们就开始聊聊zk!


outline of Apache Zookeeper
zookeeper是一个分布式协调中间件,目的就是在分布式情况下,大家都基于某个点达成一致。为啥要引入他呢,因为在分布式的情况下由于网络通信的原因,在某些场景下必须在多个节点下做出一个决定,比如,和数据一致性。有一个有名的例子就是拜占庭将军的故事。拜占庭将军分布在不同的拜占庭王国中,当他们要决定是否要打仗的时候,就发出票据去投票决定,但是在发送票据的途中可能有叛徒,最终让战争失败。那针对这些问题就要有一个规则。这个规则就是paxos算法(一个非常早期的数据一致性算法),而zk就是基于paxos算法上的一个中间件。总而言之:那就所有节点去找zk,然后zk帮忙决定谁是leader.
chubby的分布式协调:
zk的前身是chubby,因为chubby不开源,所以zk就被创造出来了。chubby当时是这样做的:所有的节点去chubby上创建一个文件,前提是,文件名是唯一的,那也就证明,多个节点创建只有一个节点是成功的。那这个创建成功的节点就是learder。
zk的分布式协调:
zk也是,类似chubby的文件,但是他不是文件,他是树形节点,也就是说他的数据是以树的形式去存储的。然后每个节点都是key和value的形式存储数据的。就像上面的shardingSphere的配置文件一样。rule是key,value存储的就是yml格式的配置。 就像这样。
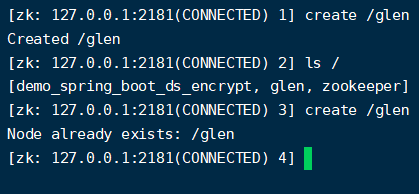
他和chubby一样,他的节点在同一节点下也是唯一的,比如我们创建一个glen的key,就不能再次创建相同的key了。那以这种方式,谁先创建谁就是learder了,
zk使用:我这里使用的是zk 3.6.3版本,这是一个稳定版本。安装这里不赘述了,使用下面地址,直接在linux上解压就行,初次使用zookeeper,需要将conf目录下的zoo_sample.cfg文件copy一份重命名为zoo.cfg,并且修改dataDir目录,dataDir表示日志文件存放的路径
【下载地址】:https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz【常用命令】:
- 启动ZK服务:
- bin/zkServer.sh start
- 查看ZK服务状态:
- bin/zkServer.sh status
- 停止ZK服务:
- bin/zkServer.sh stop
- 重启ZK服务:
- bin/zkServer.sh restart
【Zookeeper的数据结构】 :
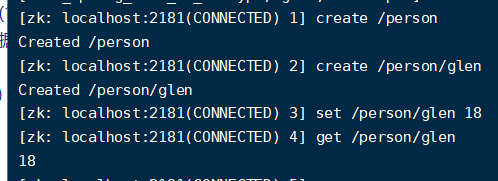
zookeeper的视图结构和标准的文件系统非常类似,每一个节点称之为ZNode, 是zookeeper的最小单元。每个znode上都可以保存数据以及挂载子节点,构成一个层次化的树形结构 。比如说要创建一个名称为Glen,年龄为18的person,他展示的就是这样的一个树形。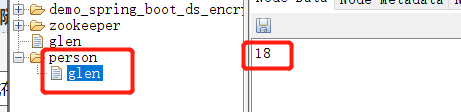
我们在创建的时候就要一步一步创建。
【 ZK节点的特性】
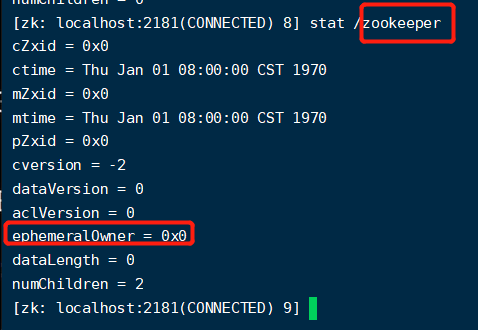
【持久化节点】: 数据会一直存储在磁盘,默认情况下创建的都是持久化节点
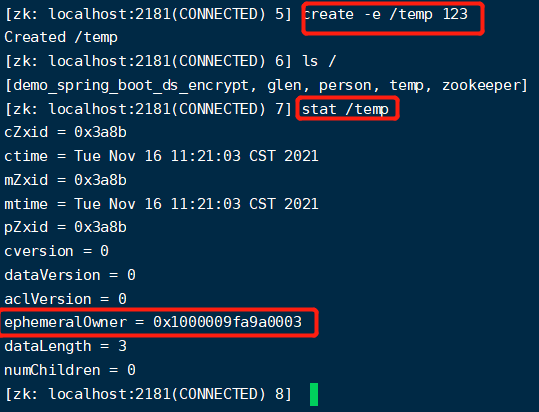
【临时节点】:这是和会话周期绑定的,当会话结束,临时节点就会被删除。
【他们的不同】:持久化节点没有临时id,而临时节点有临时id【ephemeralOwner】,zk就可以通过这个临时id去删除对应的节点。
其他的节点:
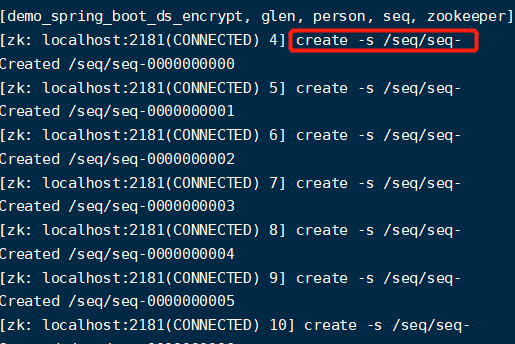
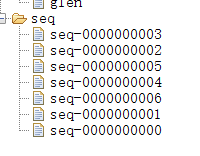
【有序节点(分为临时和持久化有序节点)】:他会按照顺序进行排列,我们创建了一个seq节点,在他下面创建这些有序节点。
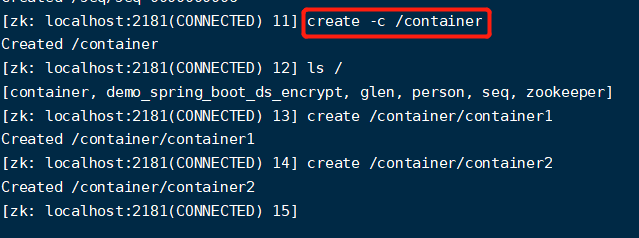
【容器节点】:当容器节点下面的最后一个子节点被删除后,他就会被标记,并且在一定时间内删除。
【ttl节点】:如果某个节点设置为TTL节点类型,那么这个节点在指定TTL时间(单位为毫秒)段内没有修改并且没有子节点时,该节点会在一段时间后被删除。(默认情况下没有被开启,需要被手动开启)必须在zookeeper的bin/zkService.sh中的启动zookeeper的java环境中设置环境变量zookeeper.extendedTypesEnabled=true。
【节点特性】:
- 同级节点不能有相同的名称的节点
- 临时节点不能有子节点(因为如果临时节点中有一个持久化节点被创建就不合理,是为了规避这种现象)
我们可以用上面的这些特性去实现相关的功能,比如分布式锁:比如有三个客户端抢占锁,那我这三个客户端就都去zk上创建一个临时有序节点,谁的序号最小,谁就可以获得这个分布式锁。