分布式存储-ShardingSphere(读写分离&分布式事务)
前面聊到ShardingSphere的一些配置和使用,但是作为一个数据库中间件,它可以做的可不是仅仅进行分库和分表。本篇想聊聊
- 它对mysql读写分离的支持
- 它支持的分布式事务,默认的管理器是【Atomikos】
- 同时也会搭建一主一从的这样一个mysql服务器【因为有至少两个服务器是shardingshpher读写分离的前提】
- 也会顺便聊聊2pc,base,cap理论这些和分布式事务相关的理论。
mysql读写分离
我们在读多写少的场景下,对数据库进行读写分离的好处有:
- 减少共享锁和排他锁的竞争。
- 减少服务器的压力:当读请求过多的时候,我们可以通过横向扩充读库去减少数据库的压力。
- 配置不同类型的数据库:大部分情况下我们配置的是innodb(支持事务的操作)。而对于查询我们就可以配置MyISAM引擎从而提升效率
mysql读写分离的配置【binlog】:
- 当数据库发生事务操作的时候,他就会把操作写进一个日志中,
- 然后slave节点中有一个io的线程定时发送一个read操作,
- master会生成一个binlog,并且返回binlog给slave,
- slave就会把得到的binlog写在自己的relaylog中,然后用一个线程去执行
操作步骤:
【整体流程】
- mater节点需要开启binlog日志
- slave节点需要指定某个binlog,以及从那个位置开始读取
- slave需要指定master节点的ip以及用户名和密码
【实际步骤】
【搭建两台mysql服务器】(我使用的是mysql8.0):
- 192.168.43.4【master】
- 192.168.43.3 【slave】
【master节点开启binlog】在mysql的配置文件中加上两行代码
- log-bin=/var/lib/mysql/mysql-bin
- server-id=1001
- log-bin指的是你的logbin文件的位置,
- server-id指的是你的这台mysql的唯一标识slave在读取的时候需要知道这个东西
- 然后重启mysql,重启后就发现logbin已经生成在了log-bin的目录中
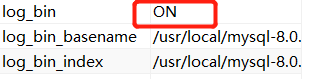
- 或者使用sql查询【show variables like 'log_bin%';】发现log-bin已经是on状态了,这也证明已经开启了
【在master节点创建一个用户】:相当于一个白名单,只有这个用户可以复制数据从master上
- -- 创建用户,其中repl表示用户名, 192.168.43.3表示slave库的ip地址,也就是只允许这个ip通过repl用户访问master库
- create user 'repl'@'192.168.43.3' identified with mysql_native_password by'123456';
- 授权
- -- replication slave 表示授权复制 -- *.* 表示所有的库和表
- grant replication slave on *.* to 'repl'@'192.168.43.3';
- 刷新权限信息
- flush privileges;
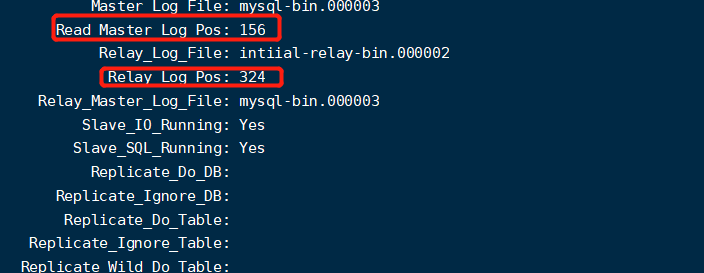
【slave节点配置】:首先在master节点,通过【show master status】了解master节点的状态,把file的内容填写到master-log-file中,把position填写到master-log-pos中
【 连接master 】【】
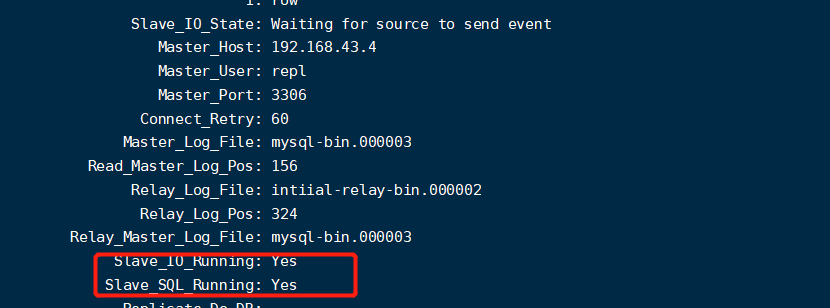
查询同步状态:【show slave statusG】 当看见下面这两个属性都是yes就证明我们已经配置完
【可能遇见的问题】:因为我是直接把虚拟机拷贝了一份,但是mysql的serverid是一致的,所以可能会出现上面的slave-io-running:no的情况,我们只需要把他的auto-confi中的id修改不一致即可。
【测试】:当我们在master上新建一个数据库的时候,slave上就会自动创建同样的数据库。同样的,在新建表的时候,slave也会自动创建。至此主从配置配置和搭建完毕。
【binlog是什么】:查询所有的binlog【show BINARY LOGS;】 查询当前使用的binlog【SHOW BINLOG EVENTS in '这里就是使用show master status查询出来的file'】。他其实就是把每一次的sql放在info中,slave拿过去进行解析后执行,就实现了和master一样的效果了
【主从同步延迟怎么办?】:主节点和从节点进行通信那网络延迟是无法被规避的,一般可能是
大事务或者节点过多而造成的数据同步延迟,这种情况下,我们可以通过【show slave statusG】中的这几个字段判断和主库的延迟量,如果延迟过大我们直接强制走主库。
或者通过控制slave节点的数量,或者去做级联,具体还是需要通过实际情况而定。



ShardingJDBC实现读写分离
上面已经搭建了主从的这样的mysql服务器,但是,当一个sql来访问我们的服务端的时候,怎么判断他走哪个节点呢?这个时候shardingSphere就为我们了干了这个事情。
【配置】
 View Codespring.shardingsphere.props.sql-show=true spring.shardingsphere.datasource.names="write-ds,read-ds" spring.shardingsphere.datasource.common.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.common.driver-class-name=com.mysql.jdbc.Driver #写库配置 spring.shardingsphere.datasource.write-ds.jdbc-url=jdbc:mysql://192.168.43.4/readwritedb?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 spring.shardingsphere.datasource.write-ds.username=root spring.shardingsphere.datasource.write-ds.password=123456 #读库配置 spring.shardingsphere.datasource.read-ds.jdbc-url=jdbc:mysql://192.168.43.3/readwritedb?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 spring.shardingsphere.datasource.read-ds.username=root spring.shardingsphere.datasource.read-ds.password=123456 # db0这个名字随意定义,就是一个逻辑库的名字 spring.shardingsphere.rules.replica-query.data-sources.db0.primary-data-source-name=write-ds spring.shardingsphere.rules.replica-query.data-sources.db0.replica-data-source-names=read-ds spring.shardingsphere.rules.replica-query.load-balancers.db0.type=ROUND_ROBIN #无任何意义 spring.shardingsphere.rules.replica-query.load-balancers.db0.props.test=test
View Codespring.shardingsphere.props.sql-show=true spring.shardingsphere.datasource.names="write-ds,read-ds" spring.shardingsphere.datasource.common.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.common.driver-class-name=com.mysql.jdbc.Driver #写库配置 spring.shardingsphere.datasource.write-ds.jdbc-url=jdbc:mysql://192.168.43.4/readwritedb?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 spring.shardingsphere.datasource.write-ds.username=root spring.shardingsphere.datasource.write-ds.password=123456 #读库配置 spring.shardingsphere.datasource.read-ds.jdbc-url=jdbc:mysql://192.168.43.3/readwritedb?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 spring.shardingsphere.datasource.read-ds.username=root spring.shardingsphere.datasource.read-ds.password=123456 # db0这个名字随意定义,就是一个逻辑库的名字 spring.shardingsphere.rules.replica-query.data-sources.db0.primary-data-source-name=write-ds spring.shardingsphere.rules.replica-query.data-sources.db0.replica-data-source-names=read-ds spring.shardingsphere.rules.replica-query.load-balancers.db0.type=ROUND_ROBIN #无任何意义 spring.shardingsphere.rules.replica-query.load-balancers.db0.props.test=test测试插入一条数据
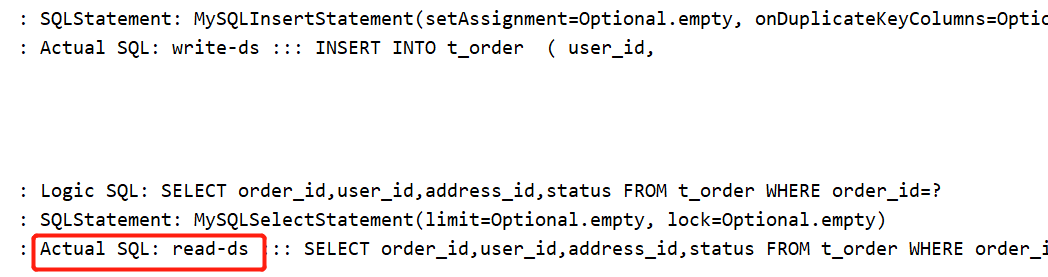
发现它走的是写库
查询一条数据
发现它走的是读库


ShardingJDBC分布式事务
分库分表解决了数据库的压力,可是,这就带来了一个新的问题,分布式事务。当用户点击一个按钮的时候,有可能是涉及到多个表的操作,但是,经过分库分表后,这些表没有在同一个数据库中,那如何保证事务的一致性呢?这个时候就引出了全局事务。流程如下:
- 在一个应用中,同时操作两个数据库的数据【当mysql收到需要操作某个数据库的数据的时候他不能直接操作,因为这就变成了单个事务了】
- 这个时候引入一个第三方【全局事务】,这个全局事务决定这两个操作是同时成功还是失败。
- 当这两个数据库的操作都完成后【他们不会直接提交事务】,他们就会分别给全局事务一个消息,告诉全局事务他们是否操作成功还是失败。
- 一旦有一个节点的执行错误,这个全局事务就让他们都回滚事务,否则才告知他们提交事务,这样就能保证了事务的一致性
【问题】:我们这里肯定不能使用传统的事务来做,因为使用全局事务他就会自动提交了,那这里就有一个XA协议
【XA协议】:是 X/Open 这个组织定义的一套分布式事务的标准中的一个协议,实际上这个组织提供三个角色和两个协议,使用这些才能构建一个分布式事务的解决方案。
三个角色分别如下:
AP(Application Program):表示应用程序,也可以理解成使用DTP模型的程序RM(Resource Manager):资源管理器,这个资源可以是数据库, 应用程序通过资源管理器对资源进行控制,资源管理器必须实现XA定义的接口TM(Transaction Manager):表示事务管理器,负责协调和管理全局事务,事务管理器控制整个全局事务,管理事务的生命周期,并且协调资源。两个协议分别是:【XA协议】:TM用它来通知和协调相关RM事务的开始、结束、提交或回滚。目前Oracle、Mysql、DB2都提供了对XA的支持;【TX协议】: 全局事务管理器与资源管理器之间通信的接口工作流程: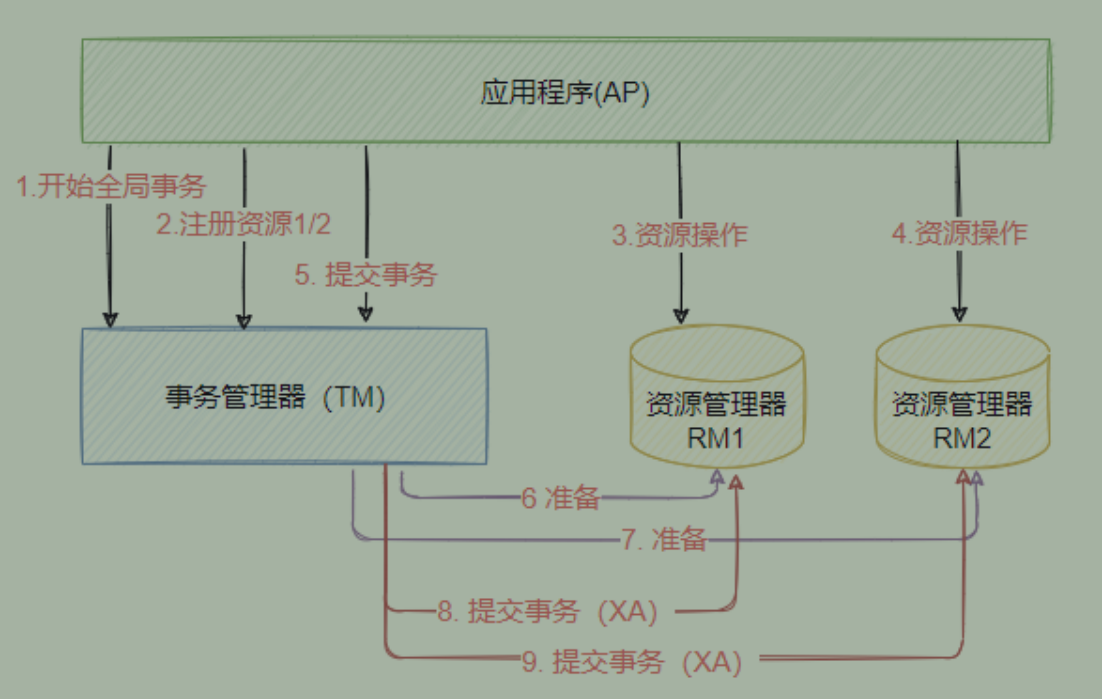
具体做法:
配置
View Codespring.shardingsphere.props.sql-show=true spring.shardingsphere.datasource.names="ds-0,ds-1" spring.shardingsphere.datasource.common.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.common.driver-class-name=com.mysql.jdbc.Driver #配置两个数据源 spring.shardingsphere.datasource.ds-0.jdbc-url=jdbc:mysql://192.168.43.3/shard01?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 spring.shardingsphere.datasource.ds-0.username=root spring.shardingsphere.datasource.ds-0.password=123456 spring.shardingsphere.datasource.ds-1.jdbc-url=jdbc:mysql://192.168.43.4/shard02?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 spring.shardingsphere.datasource.ds-1.username=root spring.shardingsphere.datasource.ds-1.password=123456 #使用user_id作为分片键 spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-column=user_id spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-inline spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINE spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=ds-$->{user_id % 2} #主键生成规则 spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=order_id spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=snowflake spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKE spring.shardingsphere.rules.sharding.key-generators.snowflake.props.worker-id=123在代码中增加一个注解即可,我们测试在代码中让它报错,看看事务会不会回滚
View Code@Override @Transactional(rollbackFor = Exception.class) @ShardingTransactionType(TransactionType.XA) public TOrder addOrder() { for (int i = 0; i <10 ; i++) { TOrder tOrder=new TOrder(); tOrder.setAddressId(1); tOrder.setStatus("GLOBAL_TRANSACTION"); tOrder.setUserId(random.nextInt(1000)); //这里让i等于4的时候报错,看看会不会回滚 if(i==4){ int ex=1/0; } orderMapper.insert(tOrder); } return new TOrder(); }我们看见已经报错了,并且数据没有进入到数据库
ShardingSphere 默认的 XA 事务管理器为 Atomikos,那他是如何实现多数据源头的事务管理的呢?
实际上主要还是基于2pc的提交(一种一致性协议):
- 表示事务管理器向每一个数据库都发送执行命令的操作,每个数据库就开始执行他们的操作,并且把执行的结果发送给事务管理器
- 如果资源管理器【数据库】有一个的发送结果是错误的,那资源管理器事务管理器就向数据库发送事务回滚的要求,否则是发送让他们都执行的要求。

分布式事务涉及问题
【XA事务存在的问题】因为xa是属于强一致性事务,因为在全局事务中,只要有任何一个RM出现异常,都会导致全局事务回滚,同时在第一阶段的时候给数据库发送请求的时候,会锁定数据库资源,但是一旦网络延迟了,那就要等待很久。【CAP理论】:这个理论告诉我们在分布式系统中,这三个只能满足两个。对于一个业务系统来说,【可用性】和【分区容错性】是必须要满足的两个条件,并且这两者是相辅相成的。我们必须保证系统可用,同时一个节点宕机,整个系统不能瘫痪。
- C:Consistency 一致性 同一数据的多个副本是否实时相同。
- A:Availability 可用性 可用性:一定时间内 & 系统返回一个明确的结果 则称为该系统可用。
- P:Partition tolerance 分区容错性 将同一服务分布在多个系统中,从而保证某一个系统宕机,仍然有其他系统提供相同的服务
【BASE理论】:
- Basically Available(基本可用):允许在一定时间段,我们的数据不同步,比如说我master中的数据是5而slave节点的数据是2
- Soft State(柔性状态):允许系统在多个不同节点的数据副本存在数据延时。
- Eventually Consistent(最终一致性):在最终的某个点的时候达到数据的最终一致性
对于base理论我们要做的就是【最终一致性】,这可以通过【重试机制】达到效果:比如说我们在注册的时候,有一个赠送积分的功能,但是由于网络或者其他原因失败了,那我们可以把这个失败的数据放在一个本地的消息表中,不断的去跑这个消息然后进行重新赠送积分。
