分布式存储-
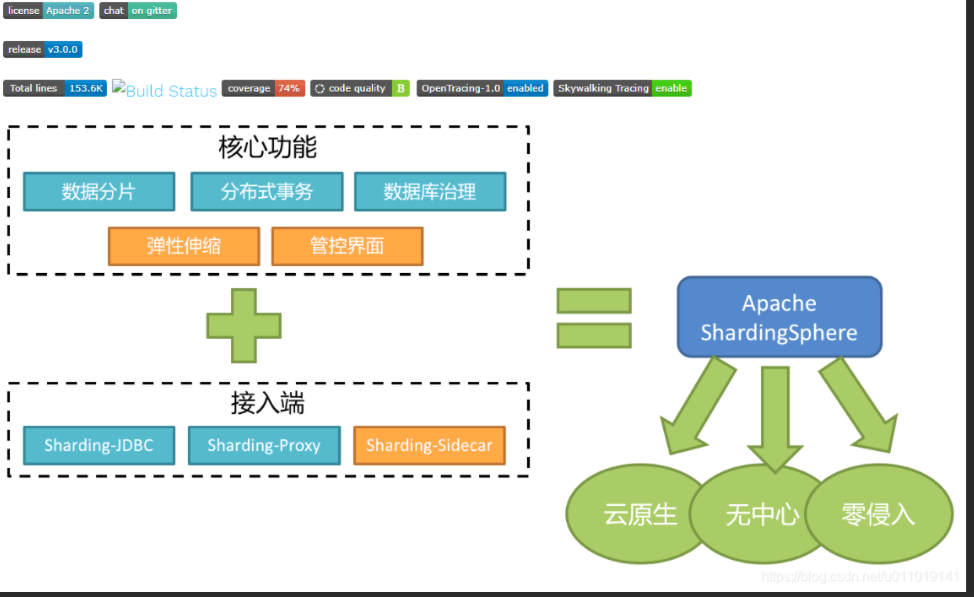
前面我们没有使用中间件去进行分库分表而没有使用任何中间件,本章给大家介绍一个分库分表的中间件shardingSphere 。它包含三款开源分布式数据库中间件解决方案.
Sharding-JDBC【服务端代理】本篇我们主要聊他:它定位的是一个增强版的JDBC驱动,简单来说就是在应用端来完成数据库分库分表相关的路由和分片操作。我们的业务代码在操作数据库的时候,就会通过Sharding-JDBC的代码连接到数据库。也就是分库分表的一些核心动作,比如SQL解析,路由,执行,结果处理,都是由它来完成的,它工作在客户端。
Sharding-Proxy【客户端代理】:简单来说,以前我们的应用是直连数据库,引入了Sharding-Proxy之后,我们的应用是直连Sharding-Proxy,然后Sharding-Proxy通过处理之后再转发到mysql中。这种方式的好处在于,用户不需要感知到分库分表的存在,相当于正常访问mysql
Sharding-Sidecar:它主要定位于 Kubernetes 的云原生数据库代理,现在还没有正式发布。
- spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds-$-> {0.}.t_order_$->{0.}
- 【广播表】:广播表也叫全局表,也就是它会存在于多个库中冗余,避免跨库查询问题,比如省份、字典等一些基础数据,为了避免分库分表后关联表查询这些基础数据存在跨库问题,所以可以把这些数据同步给每一个数据库节点,这个就叫广播表。
- # 广播表, 其主节点是ds0
- spring.shardingsphere.sharding.broadcast-tables=t_config spring.shardingsphere.sharding.tables.t_config.actual-data-nodes=ds$-> {0}.t_config
- 【绑定表】:我们有些表的数据是存在逻辑的主外键关系的,跨库关联查询也比较麻烦。我们就可以通过这个让他们在同一个库中,比如order_id=1001的数据在node1,它所有的明细数据也放到node1。这样关联查询的时候就还在同一个库中。
- # 绑定表规则,多组绑定规则使用数组形式配置
- spring.shardingsphere.rules.sharding.binding-tables=t_order,t_order_item
- 如果存在多个绑定表规则,可以用数组的方式声明
- spring.shardingsphere.rules.sharding.binding-tables[0]= # 绑定表规则列表
- spring.shardingsphere.rules.sharding.binding-tables[x]= # 绑定表规则列表
和所有的第三方一样,我们只需要导入maven即可。我们这里只要说他的配置。我们在自己进行数据库分库分表的时候,需要:设计数据库的分库、分表规则、以及主键id的算法。那在使用sharding的时候我们就需要配置这些东西。
private static Map<String, DataSource> createDataSourceMap(){ //代表真实的数据源 Map<String,DataSource> dataSourceMap=new HashMap<>(); //逻辑库,真实的数据库 dataSourceMap.put("ds0",DataSourceUtil.createDataSource("shard01")); dataSourceMap.put("ds1",DataSourceUtil.createDataSource("shard02")); return dataSourceMap; } //创建分片规则 // * 针对数据库 // * 针对表 //* 一定要配置分片键 //* 一定要配置分片算法 //* 完全唯一id的问题 //根据uuid取模进行分库 //根据orderId取模进行分辨 private static ShardingRuleConfiguration createShardingRuleConfiguration(){ ShardingRuleConfiguration configuration=new ShardingRuleConfiguration(); //把逻辑表和真实表的对应关系添加到分片规则配置中 configuration.getTables().add(getOrderTableRuleConfiguration()); //设置数据库分库规则 configuration.setDefaultDatabaseShardingStrategy( new StandardShardingStrategyConfiguration ("user_id","db-inline")); Properties properties=new Properties(); //这里就使用user_id和2取模,然后找到真正的数据库, ds指的是我们的逻辑库 properties.setProperty("algorithm-expression","ds${user_id%2}"); //设置分库策略 configuration.getShardingAlgorithms(). put("db-inline",new ShardingSphereAlgorithmConfiguration("INLINE",properties)); //设置表的分片规则(数据的水平拆分) 分片键 和 分片算法,算法我们使用inline 算法 configuration.setDefaultTableShardingStrategy(new StandardShardingStrategyConfiguration ("order_id","order-inline")); //设置分表策略 Properties props=new Properties(); props.setProperty("algorithm-expression","t_order_${order_id%2}"); configuration.getShardingAlgorithms().put("order-inline", new ShardingSphereAlgorithmConfiguration("INLINE",props)); //设置主键生成策略 // * UUID // * 雪花算法 Properties idProperties=new Properties(); idProperties.setProperty("worker-id","123"); configuration.getKeyGenerators().put("snowflake",new ShardingSphereAlgorithmConfiguration( "SNOWFLAKE",idProperties)); return configuration; } //配置逻辑表以及表的id策略 private static ShardingTableRuleConfiguration getOrderTableRuleConfiguration(){ //配置逻辑表格和真实表格的关系 ShardingTableRuleConfiguration tableRuleConfiguration= new ShardingTableRuleConfiguration("t_order","ds${0..1}.t_order_${0..1}"); tableRuleConfiguration.setKeyGenerateStrategy(new KeyGenerateStrategyConfiguration("order_id","snowflake")); return tableRuleConfiguration; } // 使用ShardingSphere创建一个数据源 // 我们可以传递多个数据源。以及分分库分表的规则配置 public static DataSource getDatasource() throws SQLException { return ShardingSphereDataSourceFactory .createDataSource(createDataSourceMap(), Collections.singleton(createShardingRuleConfiguration()),new Properties()); }配置写好,只用获取上面的getDatasource方法即可,获取一个数据源即可,sharding会根据我们上面的配置进行处理。
创建数据源的代码
public class DataSourceUtil { private static final String HOST = "127.0.0.1"; private static final int PORT = 3306; private static final String USER_NAME = "root"; private static final String PASSWORD = "123456"; public static DataSource createDataSource(final String dataSourceName) { HikariDataSource result = new HikariDataSource(); result.setDriverClassName("com.mysql.jdbc.Driver"); result.setJdbcUrl(String.format("jdbc:mysql://%s:%s/%s?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8", HOST, PORT, dataSourceName)); result.setUsername(USER_NAME); result.setPassword(PASSWORD); return result; } }测试的时候通过getDatasource获取数据源,在写sql的时候我们一律使用逻辑表

- 【自动分片算法】:我们只用配置好,然后在springBoot中操作我们配置的逻辑表或者库就可以达到相应的效果。他只要提供一下几种。
 View Codeserver.port=8080 spring.mvc.view.prefix=classpath:/templates/ spring.mvc.view.suffix=.html spring.shardingsphere.datasource.names=ds-0 spring.shardingsphere.datasource.common.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.common.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.ds-0.username=root spring.shardingsphere.datasource.ds-0.password=123456 spring.shardingsphere.datasource.ds-0.jdbc-url=jdbc:mysql://127.0.0.1:3306/shard01?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 spring.shardingsphere.rules.sharding.tables.t_order_volume_range.actual-data-nodes=ds-0.t_order_volume_range_$->{0..2} spring.shardingsphere.rules.sharding.tables.t_order_volume_range.table-strategy.standard.sharding-column=user_id spring.shardingsphere.rules.sharding.tables.t_order_volume_range.table-strategy.standard.sharding-algorithm-name=t-order-volume-range spring.shardingsphere.rules.sharding.tables.t_order_volume_range.key-generate-strategy.column=order_id spring.shardingsphere.rules.sharding.tables.t_order_volume_range.key-generate-strategy.key-generator-name=snowflake # 基于范围的分片策略 spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.type=VOLUME_RANGE spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.props.range-lower=200 # 数据存储范围最大的容量 spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.props.range-upper=600 # 每个范围的区间是200 spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.props.sharding-volume=200 spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKE spring.shardingsphere.rules.sharding.key-generators.snowflake.props.worker-id=123
View Codeserver.port=8080 spring.mvc.view.prefix=classpath:/templates/ spring.mvc.view.suffix=.html spring.shardingsphere.datasource.names=ds-0 spring.shardingsphere.datasource.common.type=com.zaxxer.hikari.HikariDataSource spring.shardingsphere.datasource.common.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.ds-0.username=root spring.shardingsphere.datasource.ds-0.password=123456 spring.shardingsphere.datasource.ds-0.jdbc-url=jdbc:mysql://127.0.0.1:3306/shard01?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 spring.shardingsphere.rules.sharding.tables.t_order_volume_range.actual-data-nodes=ds-0.t_order_volume_range_$->{0..2} spring.shardingsphere.rules.sharding.tables.t_order_volume_range.table-strategy.standard.sharding-column=user_id spring.shardingsphere.rules.sharding.tables.t_order_volume_range.table-strategy.standard.sharding-algorithm-name=t-order-volume-range spring.shardingsphere.rules.sharding.tables.t_order_volume_range.key-generate-strategy.column=order_id spring.shardingsphere.rules.sharding.tables.t_order_volume_range.key-generate-strategy.key-generator-name=snowflake # 基于范围的分片策略 spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.type=VOLUME_RANGE spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.props.range-lower=200 # 数据存储范围最大的容量 spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.props.range-upper=600 # 每个范围的区间是200 spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-volume-range.props.sharding-volume=200 spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKE spring.shardingsphere.rules.sharding.key-generators.snowflake.props.worker-id=123- 【根据分片边界进行分片】:我们可以设置0-1000 是一个区间(存储在第一张表中) 10001-20000是一个区间(存储在第二张表中) 300000-无穷大是一个区间(存储在第三张表中)
spring.shardingsphere.rules.sharding.tables.t_order_boundary_range.actual-data-nodes=ds-0.t_order_boundary_range_$->{0..3} spring.shardingsphere.rules.sharding.tables.t_order_boundary_range.table-strategy.standard.sharding-column=user_id spring.shardingsphere.rules.sharding.tables.t_order_boundary_range.table-strategy.standard.sharding-algorithm-name=t-order-boundary-range spring.shardingsphere.rules.sharding.tables.t_order_boundary_range.key-generate-strategy.column=order_id spring.shardingsphere.rules.sharding.tables.t_order_boundary_range.key-generate-strategy.key-generator-name=snowflake spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-boundary-range.type=BOUNDARY_RANGE # 0-1000 是一个区间 10001-20000是一个区间 300000-无穷大是一个区间 spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-boundary-range.props.sharding-ranges=1000,20000,300000 spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKE spring.shardingsphere.rules.sharding.key-generators.snowflake.props.worker-id=123- 【根据时间段进行分片】 :比如一年为一张表。
# 配置12个表 spring.shardingsphere.rules.sharding.tables.t_order_interval.actual-data-nodes=ds-0.t_order_interval_$->{0..12} spring.shardingsphere.rules.sharding.tables.t_order_interval.table-strategy.standard.sharding-column=create_time spring.shardingsphere.rules.sharding.tables.t_order_interval.table-strategy.standard.sharding-algorithm-name=t-order-auto-interval spring.shardingsphere.rules.sharding.tables.t_order_interval.key-generate-strategy.column=order_id spring.shardingsphere.rules.sharding.tables.t_order_interval.key-generate-strategy.key-generator-name=snowflake spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-auto-interval.type=AUTO_INTERVAL # 时间开始区间 spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-auto-interval.props.datetime-lower=2010-01-01 23:59:59 # 时间结束区间 spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-auto-interval.props.datetime-upper=2021-01-01 23:59:59 # 以s为单位的一年 spring.shardingsphere.rules.sharding.sharding-algorithms.t-order-auto-interval.props.sharding-seconds=31536000 spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKE spring.shardingsphere.rules.sharding.key-generators.snowflake.props.worker-id=123
- 【自定义分片算法】:如果他的提供的分片算法不满足我们的需求,我们可以实现自己的分片算法。实际上就是spi。
- 【SPI】:实际上就是某些扩展某些框架的方法,比如dubbo,springBoot、等一些常见的框架或者中间件都会给用户提供自己发挥的空间,因为他们无法满足所有用户的要求,所以sharding也是一样的。那我们需要怎么做呢?
在工程的META-INF/services/目录下,以接口的全限定名作为文件名,文件内容为实现接口的服务类。(因为我们需要扩展他的接口,所以我们创建的文件名称就必须和他的接口名称一致,内容就写我们实现类的全限定名)
当然在springBoot配置中还要指定要使用自己的算法
- 然后实现我们自己的分片算法。
- 我们写一个自己的spi就知道他的底层是如何实现的
- 新建一个项目,类似于提供解析的工具类。写一个spi的加载类。这个类中,我们用一个容器去存储,所有我们提供的工具类。并且在加载类的时候,加载所有的工具类的子类下面的实现类。
- 然后使用maven进行项目打包,把上面的代码作为一个jar,并且在项目中导入那个jar,并且使用jar中的功能
- 创建一个文件名称为接口名称的文件,并且在里面写上我们自己的实现类的路径
- 然后我们自己对他原来的功能进行扩展
- 接下来就可以在不改变原来框架的基础上使用我们自己实现的功能了。