本篇文章围绕字符串排序的核心思想,通过图示例子和代码分析的方式讲解了两个经典的字符串排序方法,内容很详细,完整代码放在文章的最后。
一、键索引计数法
在一般排序中,都要用里面的元素不断比较,而字符串这玩意儿大可不必比较,有另外一种思想。在键索引计数法中,可以突破NlongN的排序算法运行时间下限,它的时间级别是线性的!
引入字母表概念:
想要不对字符串里面的字符进行对比,我们需要引入字母表的概念,比如将‘a’看作1,‘b’看作2,‘c’看作3,这样下去,26个字母只需要一个长度为27的数组就能够表示(下标为0不用),而且按数字来看他们是有序的(从a到z对应1到26)。
所以“abcdefg..”这些字符转换为整型时(使用charAt()函数),自然有一个对应的顺序,所以我们只需要找到一个合适大小的数组来保存每个将会用到的字符的信息即可。现在我们创建count[]数组,大小为256,用来保存对应字符出现的频率和排序时的索引。
索引计数法共分为四步,下面进行说明并举例。(用R来表示字符的种类,r表示字符在R中的顺序)
1、计算频率:
for(int i=0;i<N;i++){//计算频率
count[a[i].charAt(d)+1]++;
}
遍历所有字符串,d为字符串的第d个字符(下面例子中字符串都为单个数字)。
出现什么字符,我们就将对应的count[r+1]加一(里面为什么是r+1,看到下一步你自然会明白)。
2、计算索引:
for(int r=0;r<R;r++){//将频率转换为索引
count[r+1]+=count[r];
}
需要在我们计算出频率的基础上进行:count[r+1]+=count[r]
将count数组中后一位总是加上前一位。
例子:
老师组织了一次游玩,把同学们分为四组,需要做的是将同学按组号排序(这里R为4,count数组大小为R+2,下标为0不用)
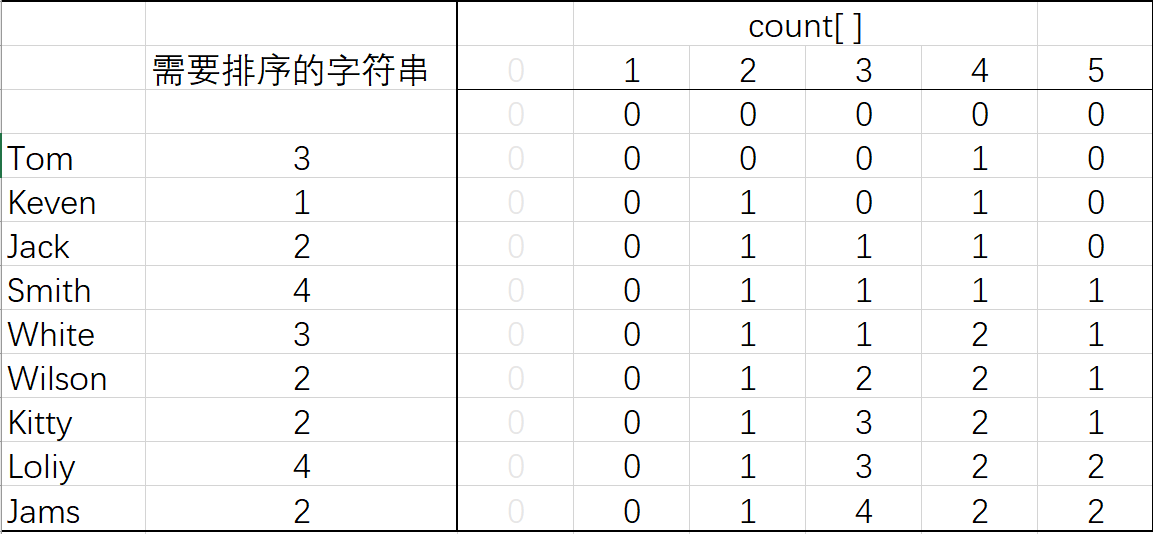
图1 计算出现频率

图2 将频率转换为起始索引
可以从图二最后一行看到,r为1对应索引为0,即一组从0开始排序。
r为2对应索引1,即二组从1开始排序。
而第三组索引为5,说明从一到四全是第二组的位置。
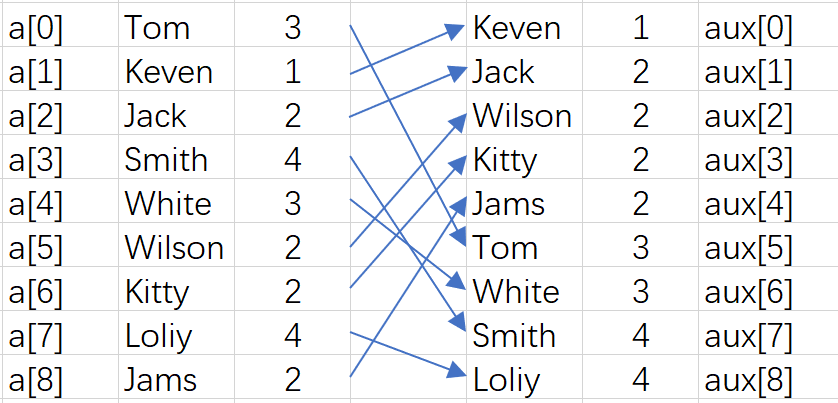
3、数据分类
for(int i=0;i<N;i++){//数据分类
aux[count[a[i].charAt(d)]++]=a[i];
}
进行数据分类我们需要一个辅助数组aux,用来暂时储存排序的数据。
把数据放入辅助字符串数组,全部放入时已经形成有序。
4、回写
for(int i=0;i<N;i++){//回写
a[i]=aux[i];
}
把辅助字符串数组的内容搬回去就行了。
到此为止键索引计数法就完成了,接下来利用它来实现LSD/MSD。
二、低位优先排序(LSD)
第位优先排序与高位优先排序的主要区别在于排序的方向,核心思想算法都是通过键索引计数法。低位优先算法是从字符串的右到左来排序(这可能会出现一些问题,在高位优先排序的介绍中将会提到)。
下图为一个地位优先排序的完整过程:

利用索引计数法,从左到右对每一位进行索引计数,这就形成了第位优先排序。
for (int d=W-1;d>=0;d--){//从右到左对所有字符串的每位判断
int count[]=new int[R+1];
for(int i=0;i<N;i++){//计算频率
count[a[i].charAt(d)+1]++;
}
for(int r=0;r<R;r++){//将频率转换为索引
count[r+1]+=count[r];
}
for(int i=0;i<N;i++){//排序
aux[count[a[i].charAt(d)]++]=a[i];
}
for(int i=0;i<N;i++){//回写
a[i]=aux[i];
}
}
三、高位优先排序(MSD)
在低位优先排序中,可能会出现一点问题。比如字符串“ab”与“ba”,长度为2需要进行两次排序,第一次排序结果为“ba”、“ab”,第二次排序结果为“ab”、“ba”,第一次排序的结果对第二次毫无意义,这就造成了时间上的浪费。
而在高位优先排序中,只会进行一次排序。结果为“ab”、“ba”。
不同之处:
在高位排序中又引入了分组的概念,即用首字母来切分下一个排序组。

在代码中我们使用递归的方式来不断切分排序组。
1 public static void sort(String[] a,int lo,int hi,int d){
2 if(lo>=hi){
3 return;
4 }
5 int[] count=new int[R+2];
6 for(int i=lo;i<=hi;i++){
7 count[charAt(a[i],d)+2]++;
8 }
9 for(int r=0;r<R+1;r++){
10 count[r+1]+=count[r];
11 }
12 for(int i=0;i<=hi;i++){
13 aux[count[charAt(a[i],d)+1]++]=a[i];
14 }
15 for(int i=0;i<=hi;i++){
16 a[i]=aux[i];
17 }
18 for(int r=0;r<R;r++){
19 sort(a,lo+count[r],lo+count[r+1]-1,d+1);
20 }
21 }
上面这段代码非常简洁,但其中有一些地方是复杂的,请研究下面例子的调用过程确保你理解了算法。

图3 sort(a,0,9,0)的顶层调用
在下一期带来另一种字符串排序方法,三向字符串快速排序,相比于这两种方法,将会有更广的受用面!
四、完整代码
1 public class LSD { 2 public static void sort(String[] a,int W){//W表示字符串的长度 3 int N=a.length; 4 int R=256;//依字符的种类数目而定 5 String aux[]=new String[N]; 6 for (int d=W-1;d>=0;d--){//从右到左对所有字符串的每位判断 7 int count[]=new int[R+1]; 8 for(int i=0;i<N;i++){//计算频率 9 count[a[i].charAt(d)+1]++; 10 } 11 for(int r=0;r<R;r++){//将频率转换为索引 12 count[r+1]+=count[r]; 13 } 14 for(int i=0;i<N;i++){//排序 15 aux[count[a[i].charAt(d)]++]=a[i]; 16 } 17 for(int i=0;i<N;i++){//回写 18 a[i]=aux[i]; 19 } 20 } 21 } 22 }
1 public class MSD { 2 private static int R=256; 3 private static String[] aux; 4 5 public static int charAt(String s,int d){ 6 if(d<s.length()){ 7 return s.charAt(d); 8 }else{ 9 return -1; 10 } 11 } 12 13 public static void sort(String[] a){ 14 int N=a.length; 15 aux=new String[N]; 16 sort(a,0,N-1,0); 17 } 18 19 public static void sort(String[] a,int lo,int hi,int d){ 20 if(lo>=hi){ 21 return; 22 } 23 int[] count=new int[R+2]; 24 for(int i=lo;i<=hi;i++){ 25 count[charAt(a[i],d)+2]++; 26 } 27 for(int r=0;r<R+1;r++){ 28 count[r+1]+=count[r]; 29 } 30 for(int i=0;i<=hi;i++){ 31 aux[count[charAt(a[i],d)+1]++]=a[i]; 32 } 33 for(int i=0;i<=hi;i++){ 34 a[i]=aux[i]; 35 } 36 for(int r=0;r<R;r++){ 37 sort(a,lo+count[r],lo+count[r+1]-1,d+1); 38 } 39 } 40 }