新到一家公司,需要折腾点认可出来。然后开始苦逼的优化工作~
优化效果
优化前,作业历史记录(前20)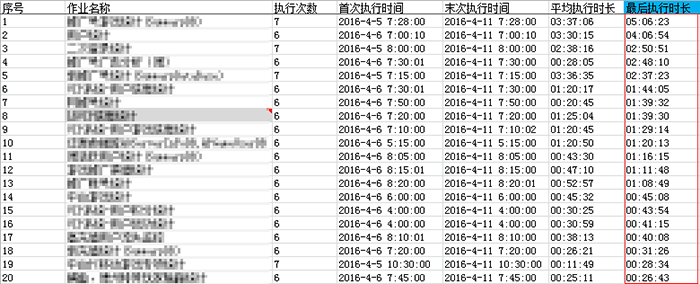
优化前,CPU使用情况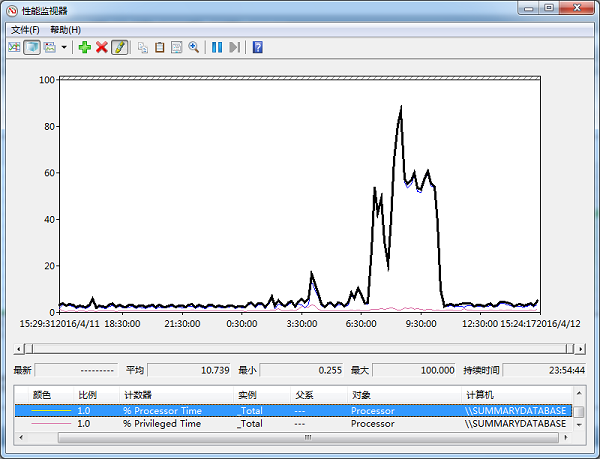
有几个作业平均时长2.5~3.5小时,还有很多时长在半小时以上的作业,基本要到11-12点才能完成作业统计。CPU每天7:00-11:00一直维持在比较高的数值。
优化后,作业历史记录(前20)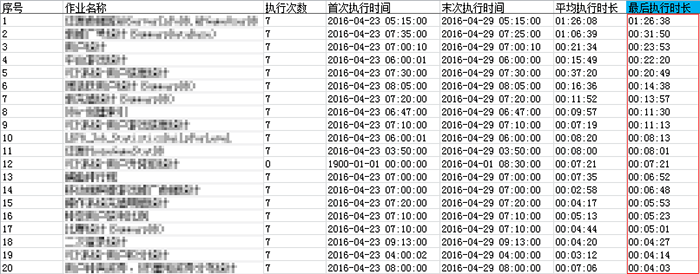
最近三天的CPU情况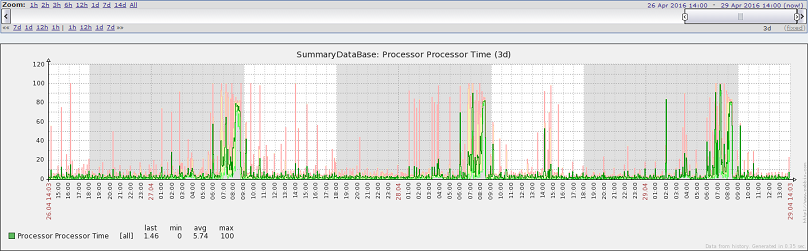
最近一天的CPU情况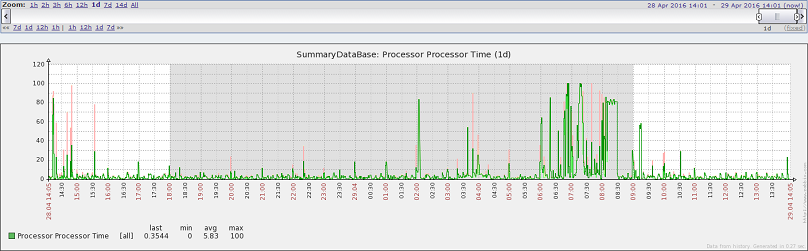
优化后,作业执行时长明显降低,从最近3天执行情况看,9:00前统计作业能够执行完成。服务器CPU高峰时段由之前的7:00-11:00降到现在7:00-8:30。
优化步骤
由于问题很明确,降低作业执行时长!3个小时、4个小时太长,降低!有多低降多低!所以就直奔主题,针对作业、作业涉及语句/存储过程进行优化!所以这里第一步没有去取worker_time或者logical_reads消耗高的语句/存储过程。
1、提取作业历史记录,按平均执行时间倒序,优先处理执行时间最长的作业
第一个作业往往只能从执行计划查看缺失的索引、以及高消耗的操作,结合set statistics io on得到每步操作的reads情况,大致就能定位到高消耗的语句。大部分是缺少索引,对表进行扫描,这种情况下创建合适索引即可。另一种情况需要对存储过程进行修改,表后面加/删索引提示,语句后面添加重编译选项,关联查询指定联接方式,借助临时表保存多次使用的数据,以改善执行计划的选择。
往往优化完一个作业后,会发现部分其他作业也得到提升。其一、它们使用了相同的表,查询条件也类似,可以从之前的索引中获益。会存在这种情况,后续优化过程中需要调整之前创建好的索引,综合考虑相关的操作,创建一个相对通用的索引。其二、前面的作业优化后,消耗降低。系统有更多的资源来处理后续作业,性能会有适当的提升。


--最近7天作业执行时长 select top 1000 a.name ,isnull(b.JobRunTimes,0) JobRunTimes ,convert(varchar,isnull(b.FirstRunDateTime,0),120) FirstRunDateTime ,convert(varchar,isnull(b.LastRunDateTime,a.LastRunDateTime),120) LastRunDateTime ,isnull(right('00'+convert(varchar,b.AvgRunDuration/3600),2)+':' +right('00'+convert(varchar,b.AvgRunDuration%3600/60),2)+':' +right('00'+convert(varchar,b.AvgRunDuration%60),2),a.LastRunDuration) AvgRunDuration ,a.LastRunDuration,isnull(b.JobRunTimes,0)*(a.StepCount+1) HistoryRecords from ( select sj.name,count(sjs.step_id) StepCount ,msdb.dbo.agent_datetime(sjv.last_run_date,sjv.last_run_time) LastRunDateTime ,convert(varchar,msdb.dbo.agent_datetime('20151201',sjv.last_run_duration),108) LastRunDuration from msdb.dbo.sysjobs sj inner join msdb.dbo.sysjobsteps sjs on sj.job_id=sjs.job_id inner join msdb.dbo.sysjobservers sjv on sj.job_id=sjv.job_id where sj.enabled=1 and sjv.last_run_date>0 group by sj.name,sjv.last_run_date,sjv.last_run_time,sjv.last_run_duration) a left join ( SELECT sj.name,count(sj.name) JobRunTimes ,min(msdb.dbo.agent_datetime(run_date,run_time)) FirstRunDateTime --05及以上版本可直接调用msdb.dbo.agent_datetime ,max(msdb.dbo.agent_datetime(run_date,run_time)) LastRunDateTime ,avg(left(right('000000'+convert(varchar,sjh.run_duration),6),2)*3600 +substring(right('000000'+convert(varchar,sjh.run_duration),6),3,2)*60 +right(right('000000'+convert(varchar,sjh.run_duration),6),2)) AvgRunDuration FROM msdb.dbo.sysjobhistory sjh with(nolock) INNER JOIN msdb.dbo.sysjobs sj ON sjh.job_id=sj.job_id WHERE sjh.step_id=0 AND sj.enabled=1 and msdb.dbo.agent_datetime(run_date,run_time)>=CONVERT(varchar,GETDATE()-6,112) --限制查看最近7天的记录 GROUP BY sj.name,sj.job_id ) b on a.name=b.name order by a.LastRunDuration desc,a.name
2、结合CPU使用情况,重点检查CPU突然上涨时刻的作业
把执行时间较长的(比如30分钟以上的)作业优化后,检查CPU突然上涨时刻的作业。这些作业的执行时间可能并不长,但是CPU随着它们开始就上涨,完成便降低,此时就需检查作业对应存储过程的reads是不是相对较高,如果比较高,就要对它们进行优化。另外有一个容易忽略的地方,比如在统计库上发现每天8:10-8:30之间CPU持续达到70-80%,通过作业活动监视器,按上次运行时间排序,找出那段时间内执行的作业,逐个去分析。但,这样我们容易忽略高频执行的作业(比如每隔10分钟)。这些作业它在那段时间执行过多次,但上次执行时间却没在那个区间。所以不要忘记检查这一类作业的消耗情况。
3、作业禁用、调整计划
根据业务需求,禁用不再使用的作业;对于执行时间过于集中的作业,适当错开作业执行时间。由于前面两步已对高消耗作业做了优化,作业执行时间可调整空间变大。有时为了确定某一个作业引起的影响,可能将它本身或它所执行区间的作业移出。
这里可以结合获取指定区间作业运行情况和上面的作业执行历史记录,得到作业区间内首次执行时间、区间内末次执行时间、可能运行时长、区间内执行次数、循环间隔、每天执行频率等信息
use dbname go --注意调整存储过程返回列、及ORDER BY字段 create table #JobSchedules(name varchar(128),FirstRunTimeInRange datetime,LastRunTimeInRange datetime ,RunTimesInRange int,intercycle varchar(64),execution_interval varchar(1000) ,active_start_date varchar(10),active_end_date varchar(10),date_created datetime,date_modified datetime) declare @sql varchar(200) set @sql='DBA_Pro_GetJobSchedules ''20160423 00:00:00.000'',''20160423 23:59:59.997''' insert #JobSchedules exec(@sql) select a.*,b.LastRunDuration PossibleRunDuration from #JobSchedules a left join ( --作业执行历史记录.sql ) b on a.name=b.name
4、其他影响
在上面操作都调整后,发现统计库的CPU在8:10-8:30之间依然过高,怀疑统计库除了本身作业执行,应该还有其他高消耗的语句在执行。于是开启跟踪筛选CPU较大的语句。发现主库在那段时间通过链接服务器从统计库中获取大量数据。实际这个操作是可避免的。