0x00 预先准备和时间规划
1.因为要用到visual studio 2013,准备学习C#,预计一天时间能基本使用。
3.了解需求并设计基本数据结构与大致流程 20min
2.根据提议实现simple mode 30min
3.扩展simple mode的功能完成extend mode 1h
0x01 实际用时和实现过程
1.关于C#的学习,看了一下基本模式和C++、Java差不多,而且在写代码的过程中能更快地熟悉语言,实际只准备了20分钟就提刀上阵了。
2.了解需求并了解需求并设计基本数据结构与大致流程。
1) 需求分析很快,核心功能是字符串的处理,词频统计,其中需要注意的是大小写的处理、排序、单词长度和单词的模式("^[a-zA-z][0-9]*");
2)最开始面临的问题是文件的递归扫描,利用如下代码即可得到所有满足要求的文件名称。
Directory.GetFiles(path, "*.*", SearchOption.AllDirectories).Where(s => s.EndsWith(".txt") || s.EndsWith(".cpp") || s.EndsWith(".h") || s.EndsWith(".cs"));
3)接下来是字符串的处理,词频统计这一功能是很容易实现的,利用容器Dictionary来存储键值对即可。由于要处理大小写,这里用到了两个Dictionary。
static Dictionary<string, int> wordtable = new Dictionary<string, int>(); static Dictionary<string, string> word = new Dictionary<string, string>();
4)其中wordtable的key是单词的小写形式,value是频度;word的key是单词的小写形式,value是优先级最高的单词形式,(如word["file"] = "File"; wordtable["file"] = 1;),再考虑到排序是先value在key,即可完成simple mode;
5)对于extend mode,字符串处理的方法是先从文件中得到形如“word1 wrod2 ... wordn”形式的长字符串,再对这个字符串不断匹配符合要求的“word1 word2”(或“word1 word2 word3”)形式的字符串,把它当作wordtable中的key,其他方法和simple mode中的一样。
整个过程,大概花了7h左右的时间,主要是C#语言许多方法不熟悉,以及在编程过程中遇到了许多技术问题。其中,为了高效地完成匹配,在正则表达式的学习上就花了不少时间,还有从Simple mode到extend mode的过程中进行了许多尝试、debug。
0x10性能分析及代码优化
1.Word_frequency.exe D: est 316ms
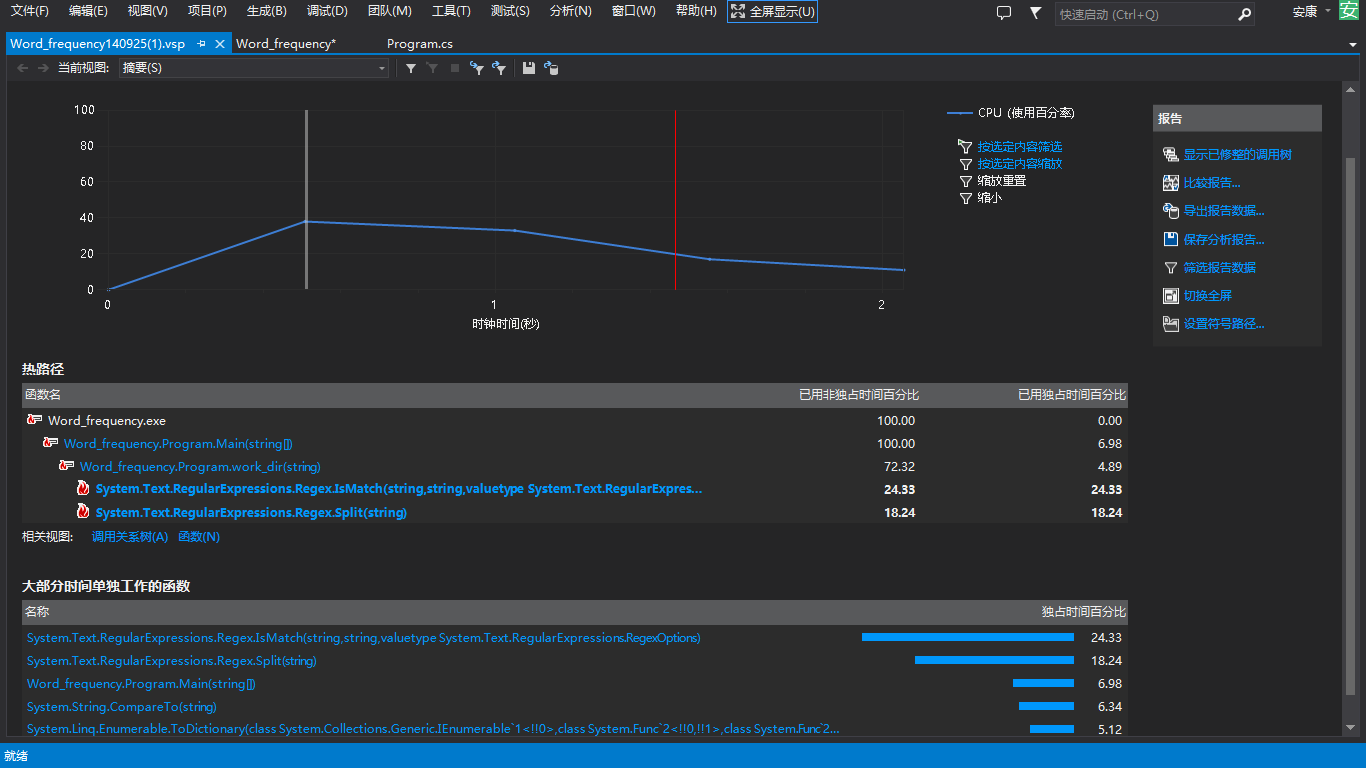
2.Word_frequency.exe -e2 D: est 475ms
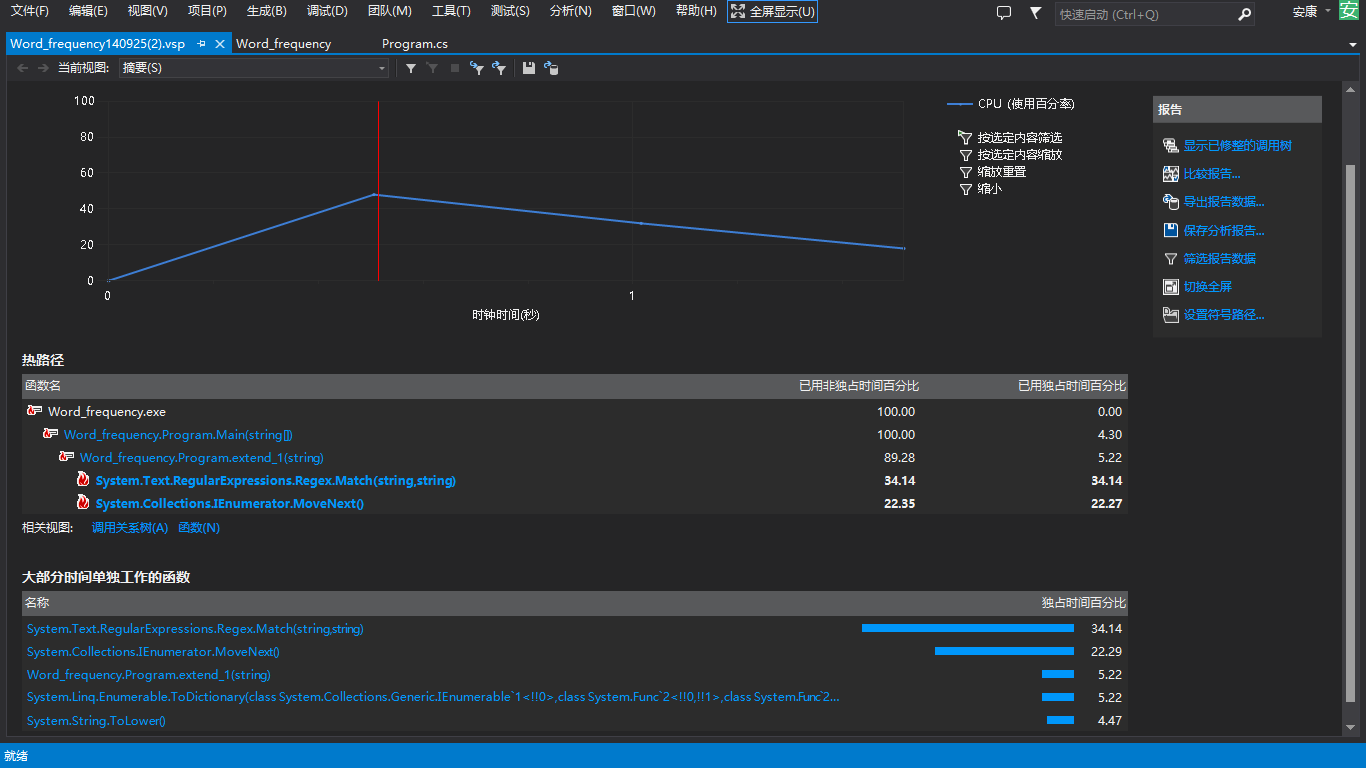
3.Word_frequency.exe -e3 D: est 559ms

由此可见,程序运行的性能主要取决于正则匹配的性能,三次测试时间的变化主要源于匹配的单词的复杂度的提升,但这方面是没有跟多优化空间的,颗星的提升性能的办法就是采用多线程,同时对多个文件进行处理,可以有效减少程序运行时间,牺牲部分内存提升性能。
0x11事后诸葛亮总结
1) 万万没想到,终于还是在deadlin前完成了。这次作业虽然完成了全部的功能,但从程序性能还是自己代码风格,都没做到很好。C#才接触,多线程实现有心无力,虽然对于少量文件来说没什么影响,但在大量文件测试线表现平平;代码中有很多可以复用的代码段,但我可耻得选择了ctrl C+V,使得代码冗余度很高,希望在下一次项目中能尽量避免。
2)项目过程中的不足:
.对于常用类、方法的认识严重不足,查找一个参数都花了很长世间;
.在码代码的过程中老是想着有现成的方法可以用,算法思想都去哪了?!
.还是没写出多线程。。。
3) 收获还是不小,c#使用熟练度上上升了好几个百分点,也终于学到了听起来很厉害的正则表达式,对程序测试的大致流程也有了较多了解。