Redis集群-简介:
Redis Cluster是Redis作者自己提供的集群方案,如下图1所示,集群由一堆节点组成,每个节点都和集群中的其他节点相连。
图1
Redis集群-原理:
Redis的集群概念和我们在日常开发中的【应用集群】概念不太相同,对于Redis来说Redis的集群主要是将数据进行分片,类似于数据库通常的分库策略,在Redis没有出现官方的集群方案时,集群在民间的方案一般表现为,clinet分片,和porxy分片,从名字来看一个时类似于sharding-jdbc的分片,一个是类似于类似于mycat的代理分片,其中原理都是针对key进行hash定位,再将hash结果通过计算而导向不同的Redis服务。
Redis Cluster在分片原理上与上述方案大同小异,主要的核心还是分片策略,但是分片的实现和对集群的管控,相比较之前两种方式所处的位置有所不同,Redis Cluster将分片策略和计算映射都放在Redis服务中,对比上述Client方案和Porxy方案最主要的区别是:
1.Client分片:扩展方式不同,扩展客户端对应的集群时,需要做到客户端更改配置甚至代码,并且在Redis集群扩展时还需要按照客户端分片策略来迁移数据
2.Proxy:中间件代理,多了网络开销,部署成本,以及和Redis的版本无法做到实时同步,Redis的一些特性更新一定总是先于中间件的更新
在Redis Cluster中,程序将所有的数据按照key来划分为16384(0x3FFF+1)个槽位,集群中所有的节点各自负责一部分槽位,而每个槽位由其对应的节点,通过key来找到对应的槽位,便可以直接定位到目标节点,从key到槽(solt)再到redis节点的图示例如下: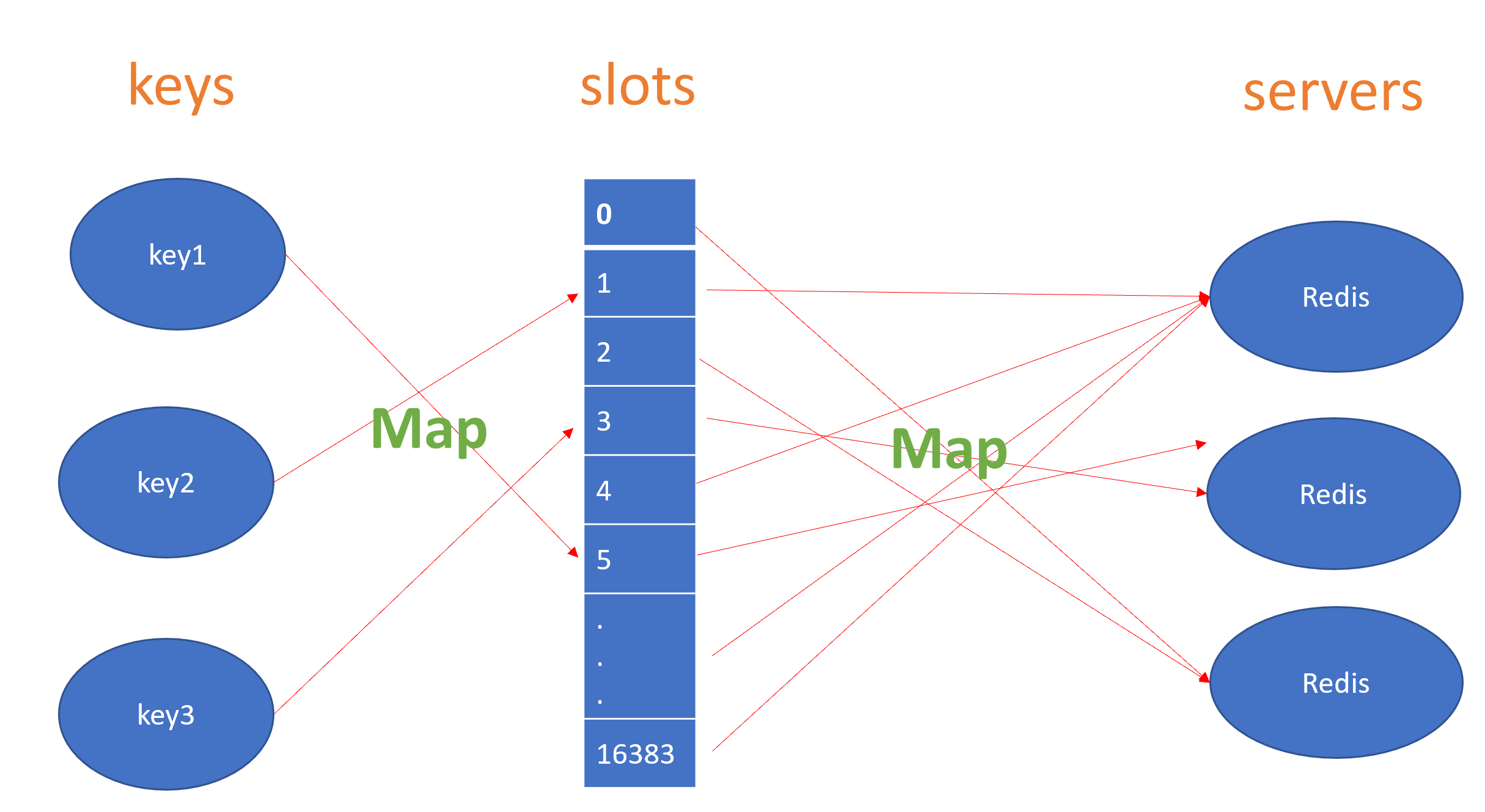
图2
上面说到槽位一共有16384(0x3FFF+1)个,对于一个Redis集群的 key来说,key将会通过crc16算法计算hash整数,然后使用这个整数值对16384(0x3FFF+1)取余来算出槽位,当然Redis Cluster中也允许客户端强行对某个key指定槽位,使用方法时在key字符串中嵌入一个tag标记,在Redis源码中,默认计算槽位的代码大致如下,其中最重要的部分就是crc16(key,keylen) & 0x3FFF:
unsigned int keyHashSlot(char *key, int keylen) { int s, e; /* start-end indexes of { and } */ for (s = 0; s < keylen; s++) if (key[s] == '{') break; /* No '{' ? Hash the whole key. This is the base case. */ if (s == keylen) return crc16(key,keylen) & 0x3FFF; /* '{' found? Check if we have the corresponding '}'. */ for (e = s+1; e < keylen; e++) if (key[e] == '}') break; /* No '}' or nothing between {} ? Hash the whole key. */ if (e == keylen || e == s+1) return crc16(key,keylen) & 0x3FFF; /* If we are here there is both a { and a } on its right. Hash * what is in the middle between { and }. */ return crc16(key+s+1,e-s-1) & 0x3FFF; }
对于Redis Cluster来说,他们包含的Redis服务器都与其他所有的Redis相连,如下图3所示:
图3
通过上面在代码中则通过获取槽位,在由槽位获取到对应的ClusterNode,使用代码类似下面:
int slot = keyHashSlot((char*)key->ptr, sdslen(key->ptr)); clusterNode *node = server.cluster->slots[slot];
上述则是key-槽-redis实例的基本定位。
Redis集群-槽位同步:
上述提到的是Redis Cluster中的槽位算法原理以及各个Cluster之间的简单连接关系,当我们在使用客户端访问的时候,首先客户端在本地会缓存一份Redis Cluster中的槽位配置表,通过这样的方式将集群信息和本地配置独立开来,对于客户端来说,总体的流程只需要:连接Redis->获取所有槽位映射->访问时根据槽位来访问对应的Redis,如图4,5所示: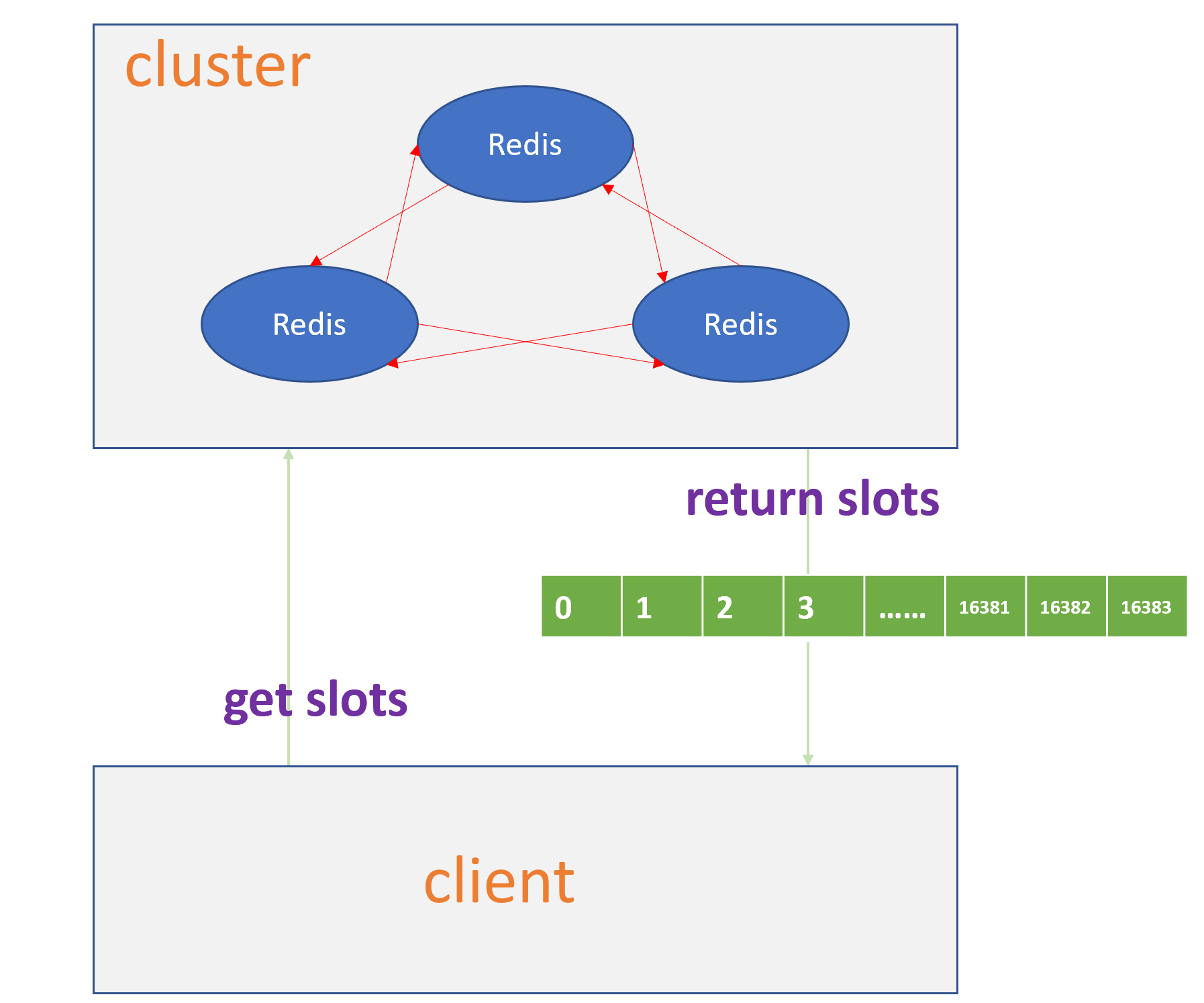
图4
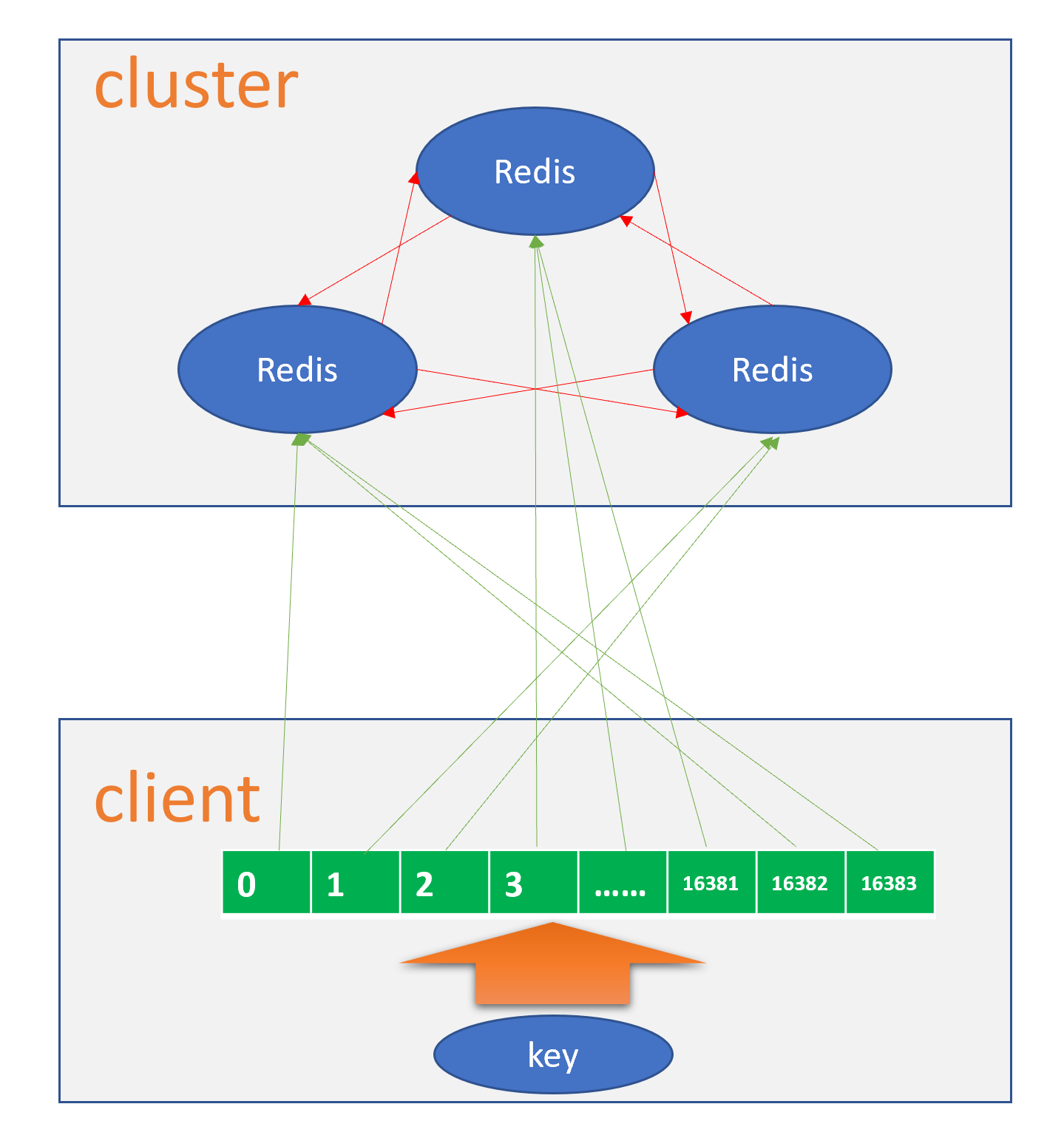
图5
在上述的流程中,可以看到,一般是由客户端缓存一份槽位映射数据,那么当槽位发生变化(配置变化,集群扩大,缩减节点,直接手动通过Redis-trib管理槽位等操作引发数据迁移)时,本地缓存的槽位和服务器中实际的槽位无法对上,此时用户在操作和获取一个key的时候,会将命令发送到一个错误的Redis实例上,这种情况下的访问是错误的,那么这个时候如何处理这样的问题呢?在Redis Cluster中,作者已经想到了这样的场景,在向一个错误的节点发出了命令的时候,该节点会通过上面的keyHashSlot方法获取到key对应的槽,通过槽来对比当前的redis实例,若是计算出的槽位不属于自己管理,redis会向客户端发送一个跳转命令(RESP),然后客户端会根据返回的命令来纠正本地缓存的槽位信息,后面槽位命中这个槽位时,回去访问纠正后的redis节点:
-MOVED 5621 127.0.0.1:6379
除了在迁移之后导致的槽位信息同步问题以外,还存在一种中间状态,即是访问migrating状态(扩容缩容/或者是手动槽位调整,处于迁移状态)的Redis Cluster,在Redis Cluster中,迁移是按照槽为来迁移,即一个槽一个槽的迁移。那么处于migrating时,会存在新旧两个节点对应的槽位都存在部分数据,如果客户端正确按照槽位访问一个节点时,就存在两个情况,一个是该数据不存在,一个是该数据已经被迁移到新的节点里去了,旧的节点在槽位正确的情况下,无法判断数据是存在还是已经迁移到了其他节点上,此时redis会向客户端发动一个询问指令(RESP),客户端收到这个指令就应该去访问新的节点获取数据:
ASK 5642 192.168.0.33:6380
在客户端收到Ask指令后,会取向新的的目标节点发送一个空的Asking指令,然后再去新的目标节点执行之前的指令,那么为何需要多发送一个Asking指令呢?在migrating状态下,按理说槽位不属于新的节点所管控,那么当新节点接收到指令时,会发现命令对应的槽位并非自己管控,如同上述所说,会回给i客户端一个跳转指令(MOVED)到旧节点,但是旧的节点又会回给客户端一个ASK相应,如此交互下去,会形成一个循环, 所以需要发给新的节点Asking指令来告诉新的节点,下一条指令对应的操作要当作自己的槽位来处理,这样就不会引发MOVED指令了。但是在槽位正常的情况下,增大了命令执行次数,从1次变成了3次。
Redis集群-杂项:
1.Redis Cluster中还可以为每个节点设置多个从节点,当主节点发生故障时,集群回自动将某个从节点升级为主节点,如果在没有丛节点的情况下有某个节点发生故障,那么整个集群都将被视为故障,但是Redis中提供了参数cluster-require-full-coverage来设置允许没有故障的其他节点继续向外提供服务。
2.客户端可通过对返回命令来实现对集群变更的同步或者重试,例如槽位对应的节点挂掉,客户端可以采取随机访问的方式,去访问其他节点,这时候节点回返回move指令来为客户端指明新的槽位关系。