Redis的基本数据结构,总体来说都是按照key-value的形式,熟悉后端的朋友可以感受到其实他的使用就像JAVA中的HashMap<K,V>和C#中的Dictionary<K,V>,只不过区别在于Redis只有一层,而事实上,Redis的Key的存储也就是按照这样的结构来的,一个HashMap。
作为一个HashMap,他的总体索引结构是一个数组,而每个索引下标对应的则是一个链表,如下图所示,一个hashmap就是一个【数组+链表】组合的二位数据结构。
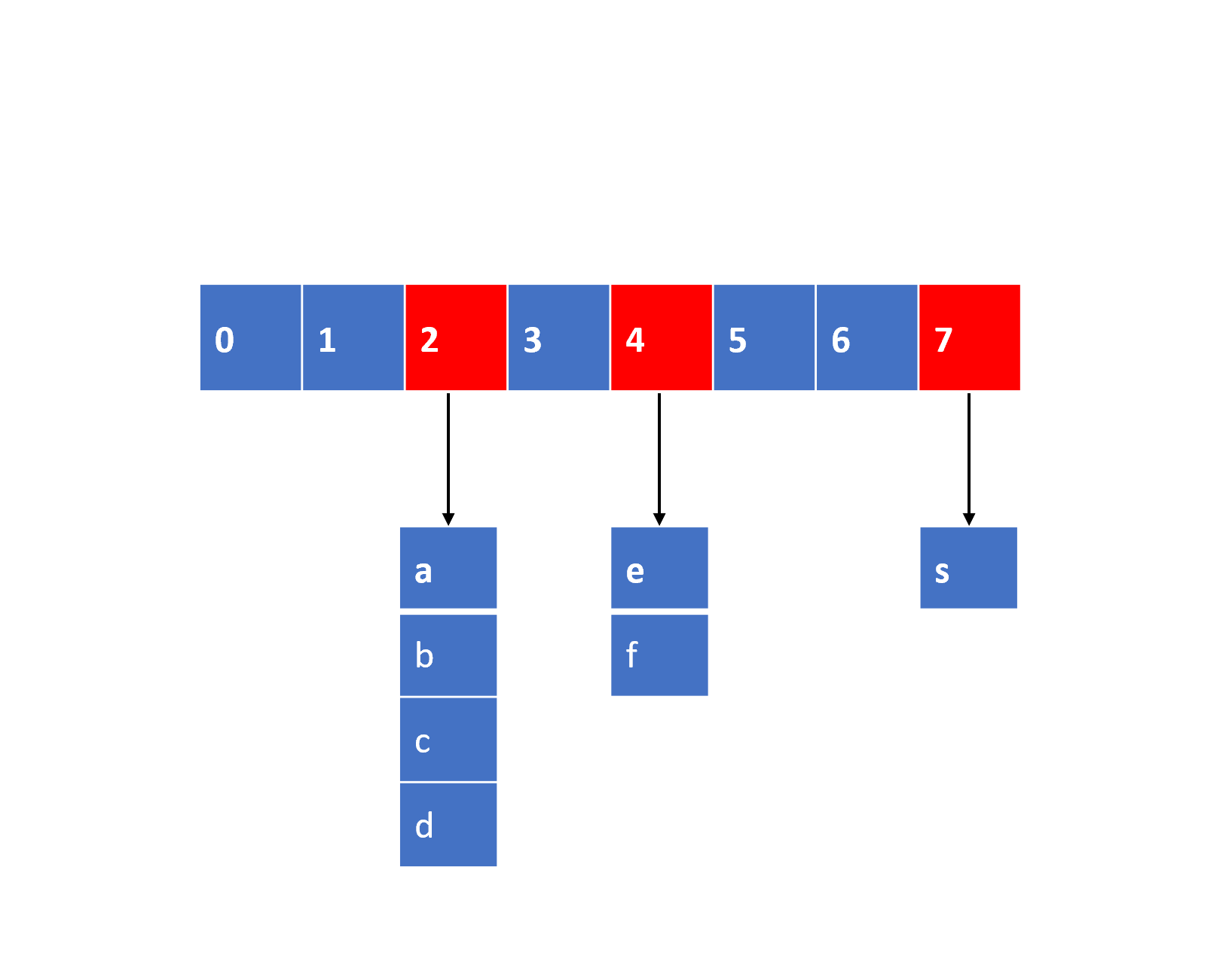
当需要去查询一个key时,首先利用预设的哈希计算出key的数组位置,然后找到数组的位置,再去链表中遍历中寻找到相关的节点进行返回,它的节点存储结构大致如下:

从上述的数据结构中可以看出,在使用hashmap的时候,需要数组大小和链表的长度平衡,理论上来说,应当做到尽量少的哈希碰撞(hash每个下标对应的链表长度小),当碰撞较多到一定的阈值的时候,我们应当对HashMap进行扩容,扩容的原理时通过增大hash产生的数组长度来达到平衡存储和哈希碰撞的目的,最理想则是没有哈希碰撞,具体前后变化如下所示:
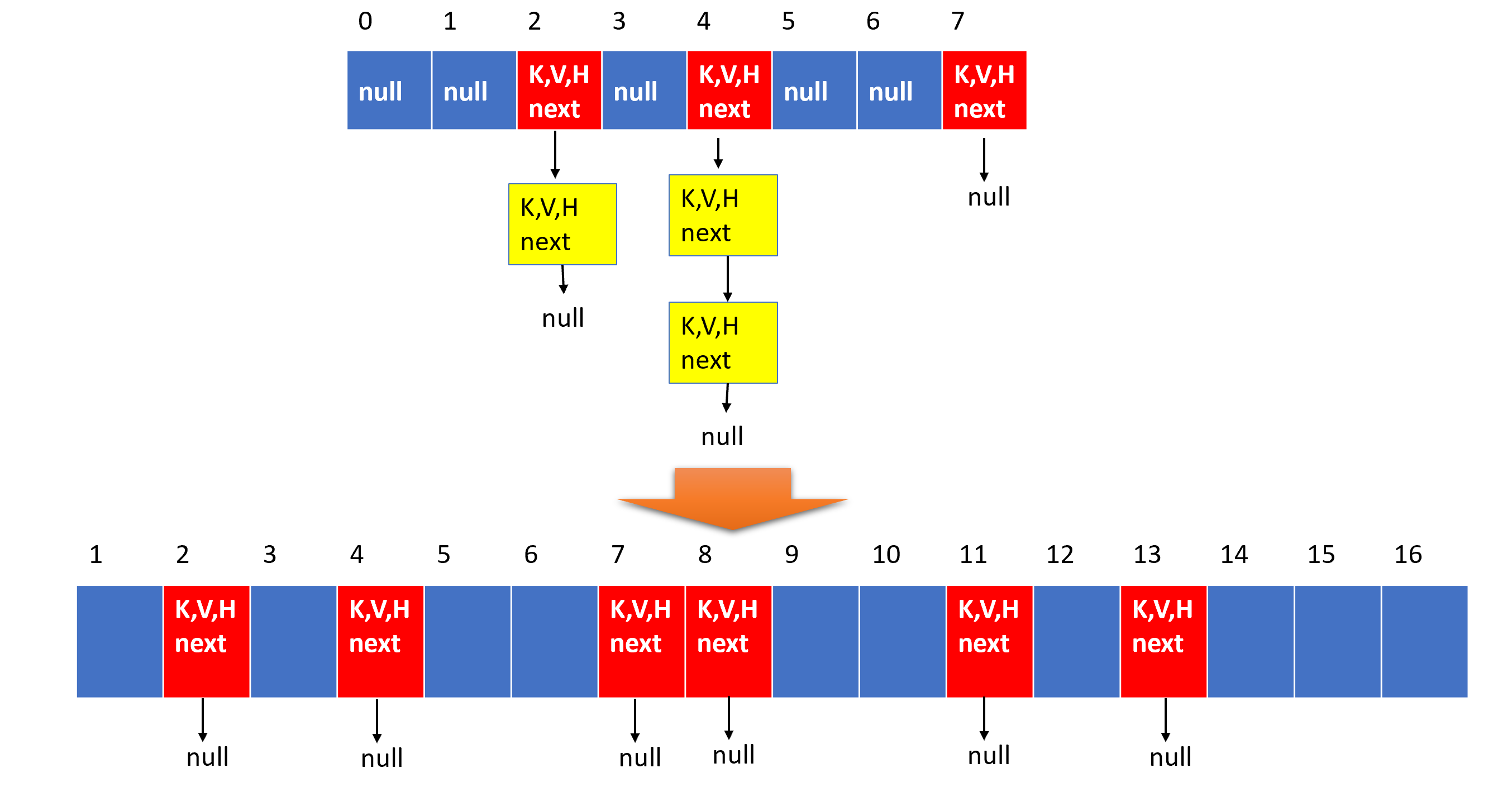
在JAVA的策略中,hashmap扩容时,会将hashmap一次性转换为新的数组结构,但是当我们在使用一个较大的hashmap时,这样的操作会让线程处于卡顿状态,这种问题可以通过在初始化hashmap的时候传入一个预计使用的长度来减少hashmap扩容的可能性,以【空间】换【时间】,但是Redis是一个难以像在使用编程代码时能够预计到初始化容量的“动态HashMap”,所以Redis的扩容在数据量急速增大的时候会自动出现,对此Redis给出的策略时“渐进式rehash”,这种方法,会同时保留旧数组和新数组,在后台任务和新的hash指令中,无感应的去将旧的元素迁移到新的数组中,等到迁移完毕旧的数组则不存在了。但是这种方式意味着会存在两个数组,所以在我们访问一个key的时候,将会同时在旧和新两个数组中进行查询。