这里拿四个网站举例吧,应该涵盖了目前字体加密的80%了吧,还有什么网站也可以留言我后面看
1.入门菜,最基础的字体加密
第一种字体加密是最原始的,他的字体规则是一套固定的样式,不会随着网页的改变而改变,我愿将之称为“静态字体加密“(狗头)
例子:实习僧 https://www.shixiseng.com/com/com_tyju1cjdpntm
打开该网页
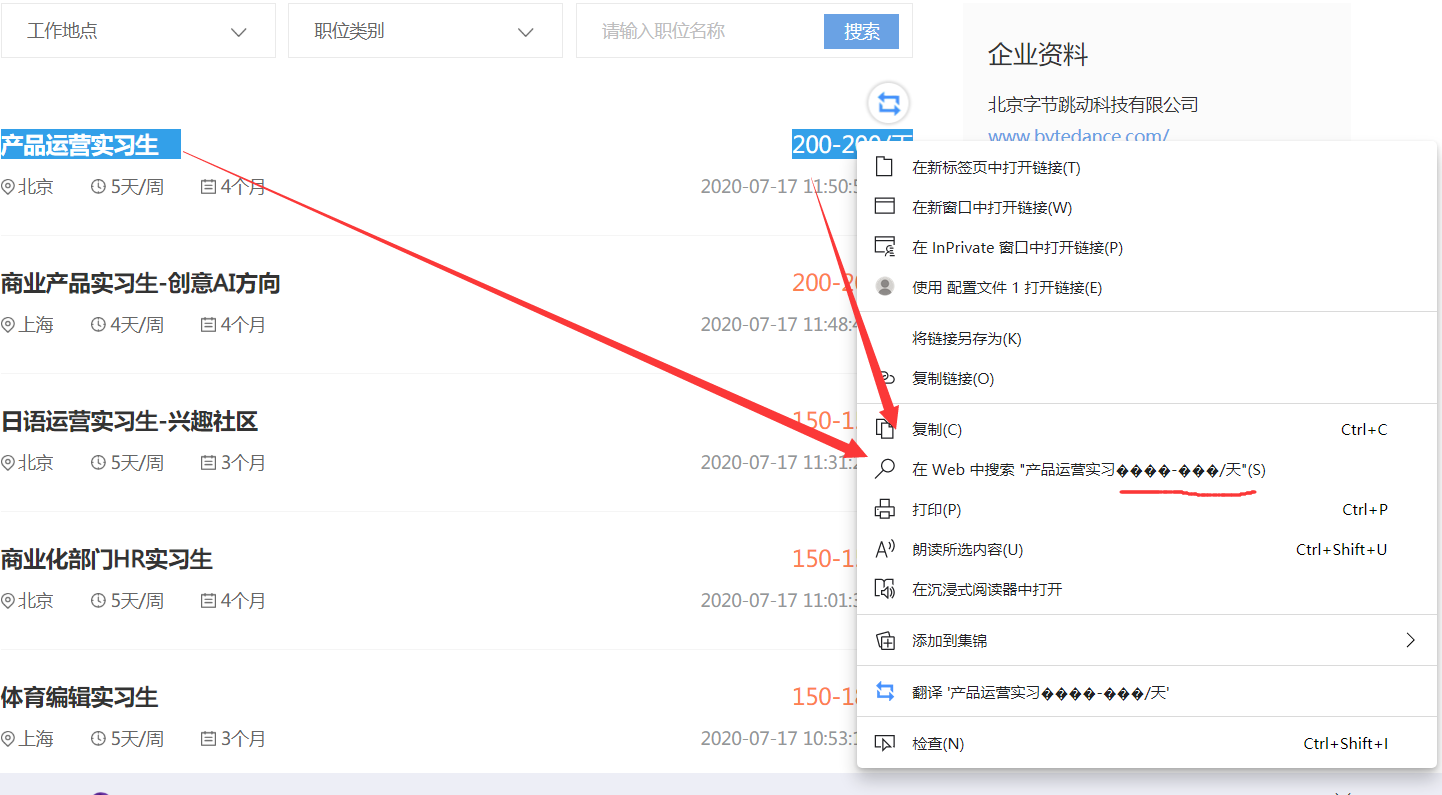
f12定位一下

这种可以肯定它就是字体加密了
那它到底是怎么实现的呢?
我们打开右键打开网页源代码,Ctrl+F搜索 /天

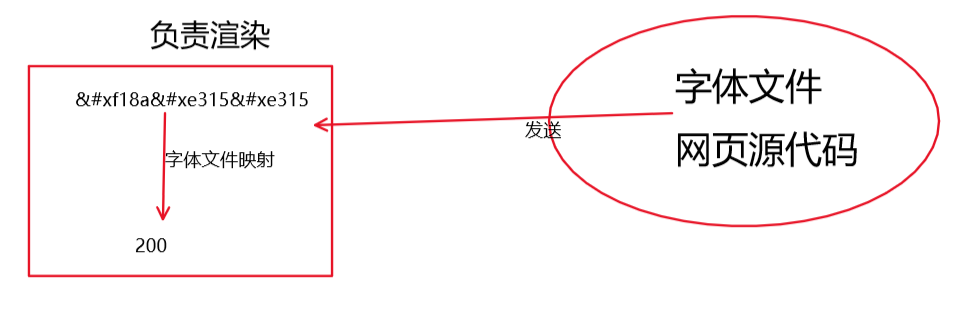
这样就很好理解了,服务器将一份字体文件,和该网页源代码一同发送给客户端,游览器会根据font-face中指定的字体来进行网页的渲染,页就是将这些&#x这种代码转换为我们看到的数字
我们的目标code(编码)-> name(该字名) -> glyph(字形) -> 字(目标)
好,那我们第一步就去找该网页的字体文件,一般现在都选择用base64加密后携带在网页中,这样可以更快的加载网页

将该字体base64解密保存为woff文件用FontCreator打开

这就可以看到它所有加密过的字体了,接下来我们将其保存为XML文件查看细节
from fontTools.ttLib import ttFont baseFont = ttFont.TTFont("字体.woff") baseFont.saveXML('字体.XML')
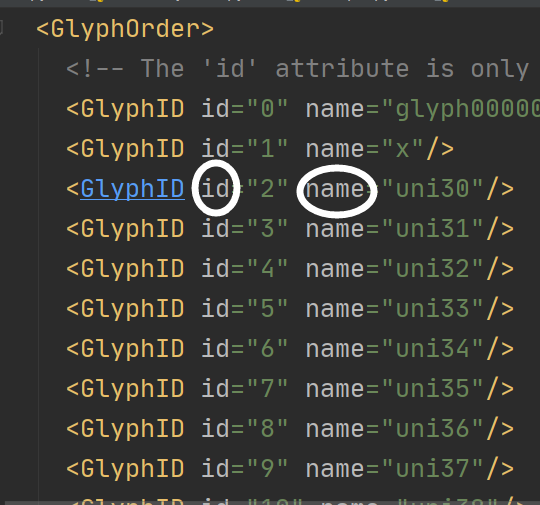
你在后头看看字体文件数字上的uni30,没错这以为着0-->uni30-->id=2,也就是id为2的字体的编码就是我们要找的0
baseCodeName = baseFont.getBestCmap()#getBestCmap返回一个字典,该字典有code(字编码)和name(子名字)的对应关系 for code,name in baseCodeName.items():#字名字(你叫什么都可以),比如数字0对应的就是uni30 print(hex(code),name)#将code转换为16进制,因为网页上是16进制
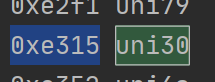
这样我们就找到了0的编码了,但这是我们手动搜索并对应字体文件得出的0xe315就代表0,要想程序明白0xe315对应的是0,我们需要建立一个number字形对应的字典
我只将对应的数字和几个常见的英文,一个汉字的关系找出来了,一个一个对应还是比较无聊的,重点是掌握方法
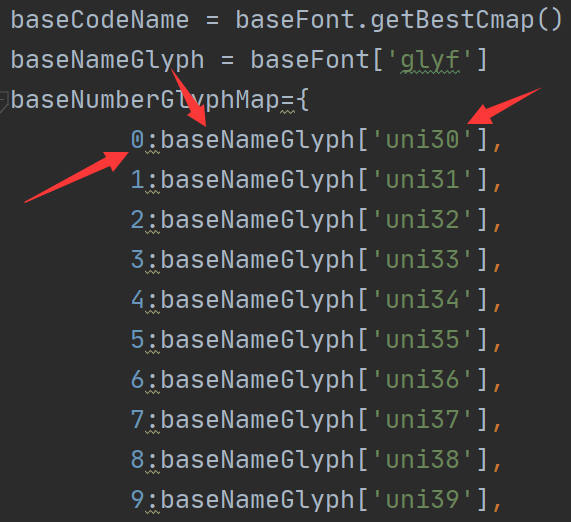
解释下:baseFont是一个ttfont对象,baseFont['glyf']:可以返回这个字体的所有形状,获取name和形状的一个字典,就是所给对应的name返回对应的字形
之后我们对比字形,如果该字形和0对应的字形相当,我们就认为它是0的字形,输出0的编码,和0
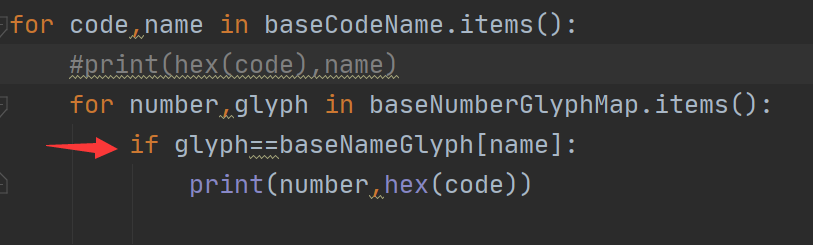
运行

最后用re的sub将网页中的code替换为字就行了,运行替换成功

最后来理一遍流程,1.下载字体文件2.保存为XML,用fontcreator手动找出其中code和name的对应关系3.比较字形,字形相同的为我需要的字体4.讲网页中原本的code替换为目标字
光看你可能不是很能理解,我建议你自己动手试试,按流程来,并理解我所说的code,name,glyph代表什么,找他们之间的联系,你就懂了
2.每次的字形是一样的但是code和name的对应关系不同
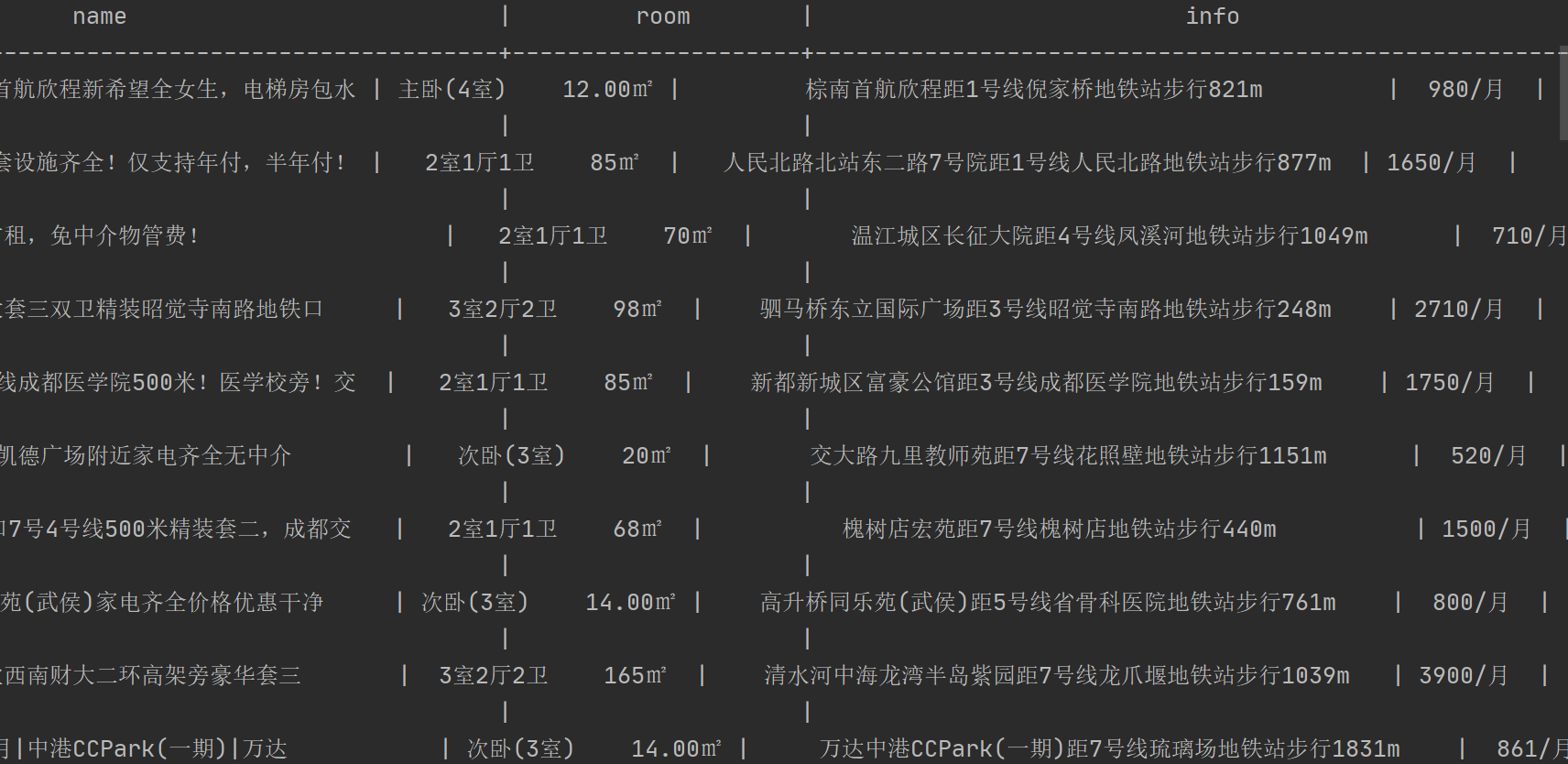
例子:58同城 https://cd.58.com/chuzu/?PGTID=0d000000-0000-0f12-e270-c701f230eff6&ClickID=1

我默认你已经懂了第一种再来阅读这个
58比实习僧要稍微多了一个点但基本流程都是一样的
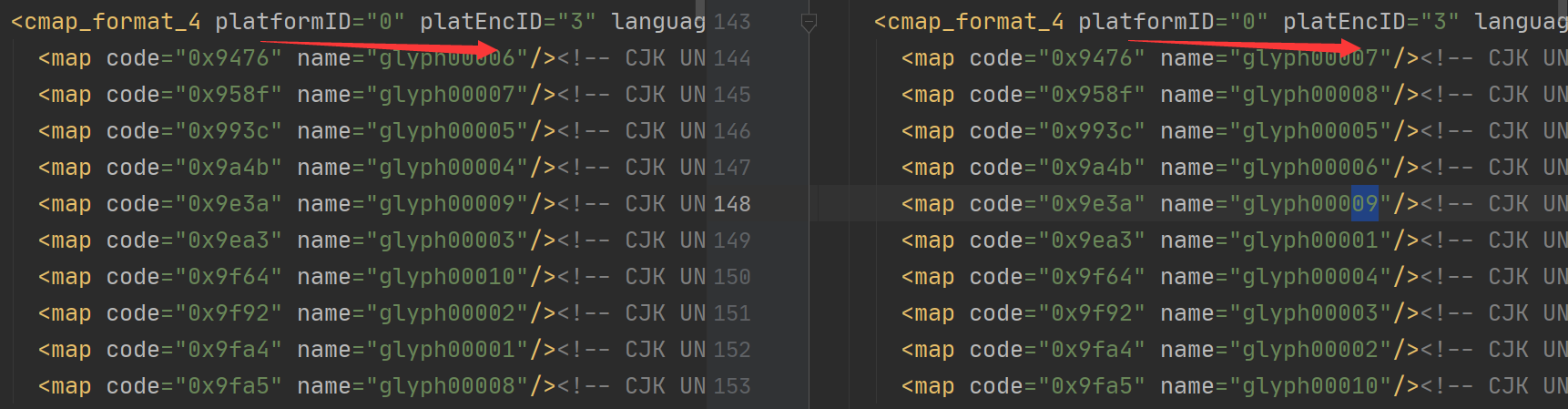
保存两个字体到本地,发现他们字形没变,但是code和name对应不同,这其实和上面是一个思路稍微变一点
就是我先保存一份字体到本地作为基准,我们先肉眼把本地的基准字体0对应什么1对应什么的关系找到,然后我们每次爬取获取该页面的字体文件
将他与我们的基准文件的字形做对比(因为字形不改变),如果基准字形与该字形对应,我们就认为它和基准字体中的某某是同一个字,意思如图
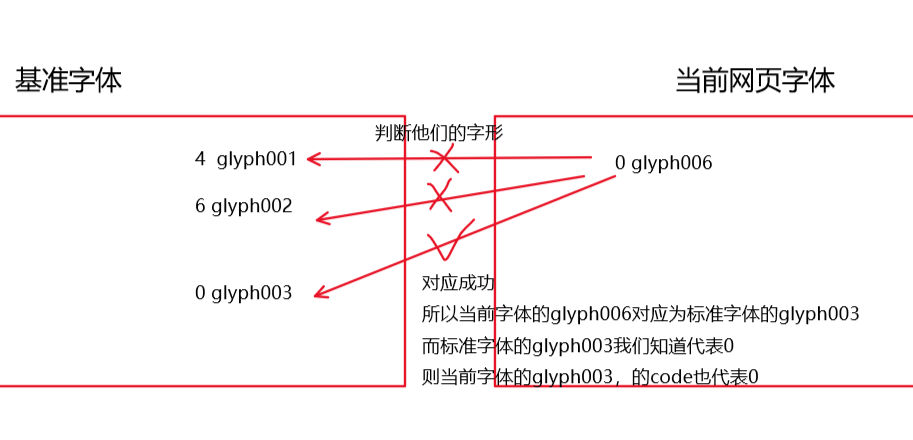
其实无非就是实习僧用一套字体,这个需要多套的区别,核心代码和实习僧的一样,加一个每次下载字体到本地
最终结果,爬取正常
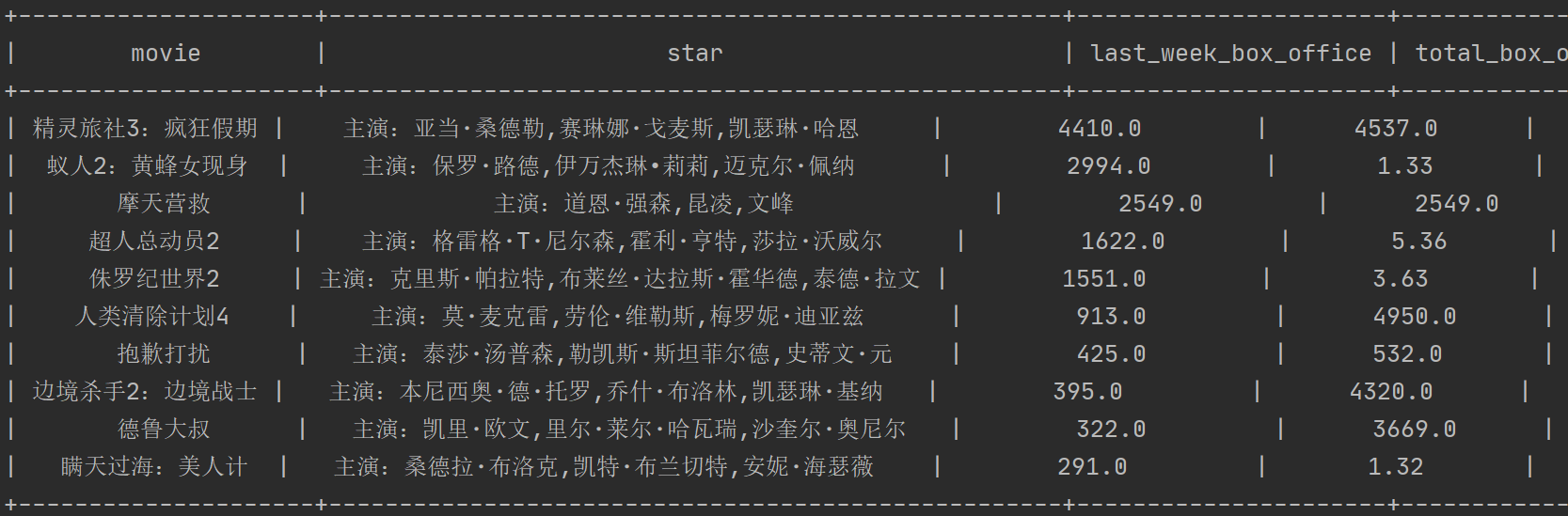
3.第三种就是猫眼电影这种字形也变,对应关系也变的了
解决思路也很清晰,就是把本地一套字体,每次获取它当前的字体,我们对比字形坐标,因为它字形虽然会变但是区别不会特别大,所以我们只要找到当前字体与本地字体中坐标差值最小的那个,我们就认为它们是同一个字,当然这里有个坑就是坐标排序的顺序会改变,还需要先找出坐标最相近的,再做差值
说起来不难,第一次实践还是整了挺久的,查了很多博客才整出来,这里就不展开讲了,思路已经给你了
运行,结果正确
4.王炸GlidedSky字体加密2
我一开始做的时候一头雾水,后面直呼作者牛逼,有兴趣的可以研究下
网站是http://glidedsky.com/,题目描述如下,你要先解决前几道题才看的到这题

就问你懵逼不懵逼,如果你能把这到题做出了,我想字体加密应该差不多了吧(个人认为,还有什么网站可以告诉我)
给大家提供点思路吧,总共代码40行,重点是思路。最核心的映射关系自己找吧,我说说后面
1.做到后面会发现解析出的汉字和真实网页上的汉字不对应的情况,查了下,是什么汉字字典对应的关系什么鬼,反正就是同一个汉字长得一样不一定真的一样。。。比如说
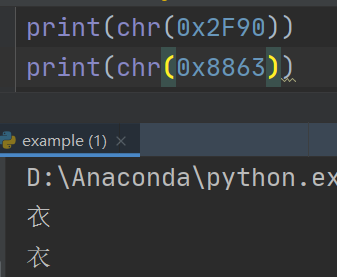
这两个衣就不一样,第二个是网页中给出来的,第一个是我用unicode转字符的,他们是不能够对应的,那怎么办,我一开时以为这种就几个特殊的情况,就手动查该字的编码表,一个一个换
换了几十个我放弃了,不知道到底有多少个,后面没用这个方法,但我看网上有那个康熙字典,按理来说应该可以
https://blog.csdn.net/qq_40734108/article/details/105104412
2.我的做法是阅读XML文件,找他如何从unicode编码来到真实的0x这种16进制编码,是的,通过unicode(name)去找code,这样反倒还简单