前时间爬了一个视频的弹幕,只爬一个视频没意义,所以我们来爬所有的。完整代码在最后。
这里我以科技美学为例啊(因为每天都看)主页链接:https://space.bilibili.com/3766866/video
我们先来尝试获取某一个视频的弹幕,打开这个url,f12,进入开发者模式
视频链接:https://www.bilibili.com/video/BV15K411j7rB
这里好像是chrome的一个bug,我用ie都可以看到,所以最好再配一个火狐
直接访问,弹幕就在这里面了
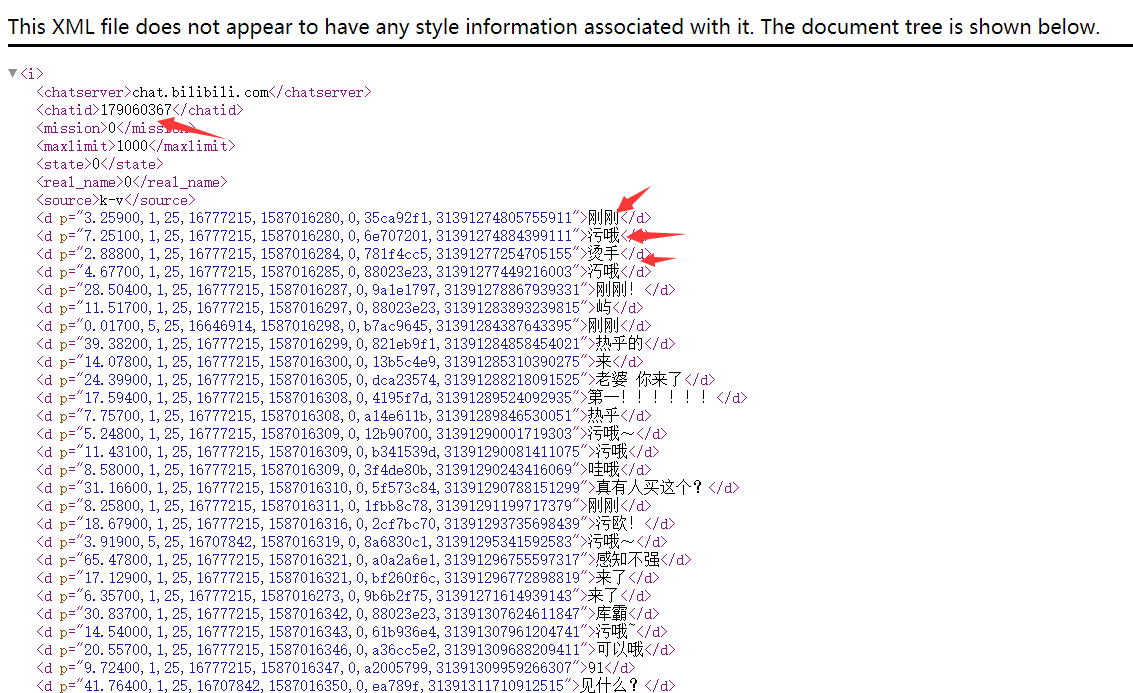
然后很简单写个正则就出来了

这里就解决了如何爬某个视频的弹幕了,接下来我们深入研究一下,如何才能得到一个up主的所有视频弹幕。

注意到这个返回弹幕的那个网址的url,我们随意改变它的oid,会给我返回不同的弹幕内容。
这里可以确信,每个视频对应一个oid,以oid来区别返回的弹幕。
所以,我们只需要获取到他所有的oid就可以得到所有的弹幕解决了。
于是,我找了这个网页中的url,看那个会返回它的oid,最终找到了https://www.bilibili.com/video/BV15K411j7rB
即视频链接的这个url中就会返回oid


在这里它叫做cid,所以我们得到cid就可以了,编写代码获取cid

至此我们可以通过1.点击一个视频,2.获取oid 3.获取弹幕
这里我用selenium,访问主页链接,来打印它的page_source(因为你有requests得不到,我也不懂为什么)

这里我们就找到了第一页所有的视频链接,创建一个列表来保存所有链接

然后我们再按我们第一步获取某个视频oid的方法就可以写所有的了
完整代码如下:
1 import requests 2 import parsel 3 import re 4 import parsel 5 from selenium import webdriver11 #代码部分 12 danmu = re.compile('>(.*?)</d>') 13 links = [] 14 def get_links(url): 15 browser = webdriver.Chrome() 16 browser.get(url) 17 html = browser.page_source 18 soup = parsel.Selector(html) 19 get_ul = soup.xpath('//ul[@class="list-list"]/*')#获取到父标签 20 for i in range(0,29): 21 link = str(get_ul[i].xpath('./a/@href').extract()) 22 link = link.replace('//','') 23 link = link[2:-2] 24 links.append(link) 25 26 def get_danmu(*links): 27 for urls in links: 28 url ='http://' + urls 29 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36 Edg/81.0.416.53'} 30 html = requests.get(url,headers) 31 html_text = html.text 32 get_oid = re.search('cid=d*',html_text).group().replace('cid=','') 33 danmu_links = 'https://api.bilibili.com/x/v1/dm/list.so?oid={}'.format(get_oid) 34 html = requests.get(danmu_links) 35 html.encoding = 'utf-8' 36 datas = danmu.findall(html.text)[1:] 37 for each in datas: 38 with open('那先生的弹幕.txt','a',encoding='utf-8') as f: 39 f.write(each) 40 f.close() 41 print(each) 42 43 44 if __name__ == '__main__': 45 url = 'https://space.bilibili.com/3766866/video?tid=0&page=1&keyword=&order=pubdate' 46 get_links(url) 47 get_danmu(*links)
爬第二页第三页找下翻页的规律就行了,要爬取别的up也可以,url也有相应的规律,我就懒得做了。
最后我做了张词云图
