1、Mysql的事务
ACID
- atomic :原子性,一堆sql要么一起成功要么一起失败
- consistency :一致性,针对数据一致性来说的。就是一组SQL执行之前是正确的,执行之后数据也必须是准确的。
- isolation : 隔离性,多个事务跑的时候不能互相干扰
- durability : 持久性,事务成功后, 对数据的修改必须永久生效。
事务隔离级别
- 读未提交 read uncommited :A线程可以读取到B线程未提交的数据,这个叫做脏读
- 读已提交 read commited : A线程跑的时候,先查询一个值为1,这时候B将这条记录改为2,并提交了事务,此时A再次查询该条记录的时候就发现变为2,这个问题叫做不可重复读
- 可重复读 read repeatable :A线程在运行过程中,对于某个数据的值,无论读多少次都不会改变,哪怕B线程修改了该值并提交了事务。
- 串行化 : 不可重复读和可重复读都存在幻读的问题,假设表中只有一条数据,事务A查询全表查询一条数据,这时候事务B插入一条记录,事务A再次查询出现了两条。如果要解决幻读,就需要使用串行化隔离级别的事务,将多个事务串行起来,不允许多个事务并发操作
MVCC :多版本并发控制
- innodb在存储的时候,会在每行数据的最后加两个隐藏列,创建时间和失效时间,保存的值都是事务的id,innodb事务开始的时候都会被分配到一个事务id,依次递增
- 一个事务在查询的时候,innodb只会查询创建时间事务id<当前事务id,并且失效时间 > 当前事务的id的数据
- 当执行update操作的时候,innodb实际上将原有列的失效时间覆盖,然后新增一条创建时间为当前事务id的数据
- update操作表里肯定还是一条数据,那么事务是怎么查到之前的版本的呢?更新的时候都会在undo.log中记录一条对应版本回滚记录,然后我们只要根据当前事务id对当前值进行回滚操作,就可以看到我们应该看到的数据了。
2、binlog,redolog,undolog都是什么,起什么作用?
https://www.yuque.com/liangliang-6kwxx/grxkrz/xbply3
3、 数据库锁有哪些类型?锁是如何实现的?行级锁有哪两种?一定会锁定指定的行吗?为什么?悲观锁?乐观锁?使用场景是什么?mysql死锁原理以及如何解决?
- mysql锁类型一般就是表锁,行锁和页锁
- 表锁 : 意向共享锁:就是加共享锁的时候,必须先加这个共享表锁;还有一个意向排他锁,就是给某行加排他锁的时候,必须先给表加排他锁。这个表锁是引擎自动加的
- innodb行锁有共享锁(S)和排他锁(X)两种,多个事务可以加共享锁读同一行数据,但是别的事务不能写。排他锁就是一个事务可以写,别的事务只能读不能写。
- innodb在insert、delete、update的时候会自动给那一行加排他锁
- innodb不会自己主动加共享锁 ,必须自己手动加: select * from table where id = 5 lock in share mode
- 手动加排他锁 : select * from table where id = 5 for update;
悲观锁和乐观锁
- 悲观锁:总是害怕拿不到锁,总是先加锁
- 乐观锁:先查出来一条数据,修改的时候查看数据库是不是还是那个版本,如果还是那个版本就修改。不然就重新查出来再修改
死锁:
场景:
- 事务A : select * from table where id = 1 for update;
- 事务B : select * from table where id = 2 for update;
- 事务A : select * from table where id = 2 for update;
- 事务B : select * from table where id = 1 for update;
持有对方的锁,gg
解决方案 : 找下dba查一下死锁的日志
4、myisam和innodb的区别,什么时候选择myisam
|
innodb |
myisam |
|
|
事务 |
支持 |
不支持 |
|
存储限制 |
64TB |
无 |
|
锁粒度 |
行锁 |
表锁 |
|
外键 |
支持 |
不支持 |
|
崩溃恢复 |
支持 |
不支持 |
5、索引
b-树
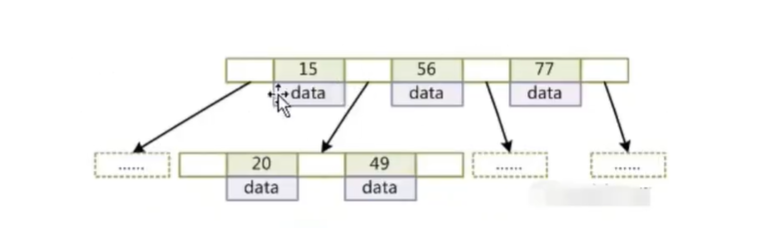
B+树
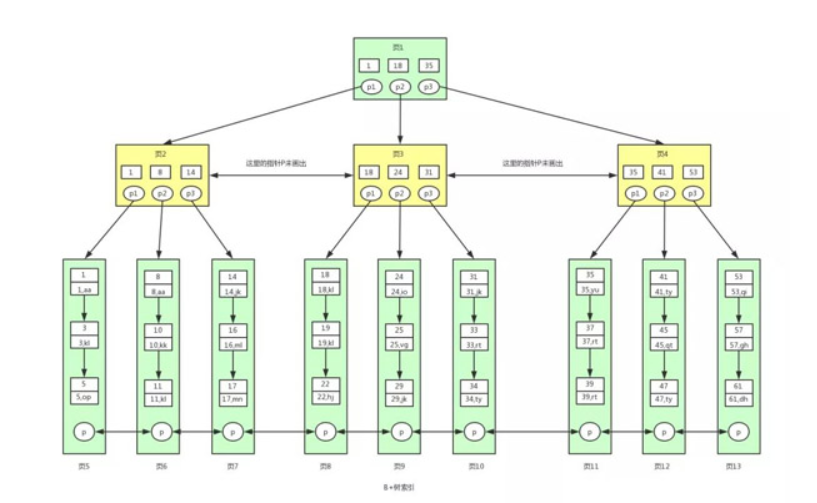
从磁盘中读取数据都是按照磁盘块来读取的,那么我们应该在一个磁盘块中存储更多的索引,来减少磁盘的查询次数。B+树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。之所以这么做是因为在数据库中页的大小是固定的,innodb中页的默认大小是16KB。如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查询的效率也会更快。
因为B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。而B树因为数据分散在各个节点,要实现这一点是很不容易的。
- myisam叶子节点不存数据,存的是物理地址,然后根据物理地址到数据文件中去查找到对应的数据。
- innodb 默认会根据主键建立索引,称为聚簇索引。innodb的数据文件本身就是索引文件,聚簇索引的叶子节点存储了真实的数据,如果对非主键建立索引,其叶子节点存储的是主键的值,然后根据主键再查询到对应的数据,该操作称之为回表。
6、索引的使用
索引的原则 : 全值匹配、最左匹配原则、慎用like 百分号在右边、范围查找只有范围查找字段可用索引、不要使用函数修改列
7、sql如何优化
https://www.yuque.com/liangliang-6kwxx/grxkrz/gpc4mk
https://www.yuque.com/liangliang-6kwxx/grxkrz/tziqg5
8、Order By
表结构
-- auto-generated definition
create table product_application_config
(
id bigint auto_increment primary key,
product_no varchar(32) not null,
channel_code varchar(32) null,
org_id bigint not null,
created_by varchar(100) default 'SYS' not null,
created_date timestamp default CURRENT_TIMESTAMP not null
);
create index product_application_config_channel_id_index
on product_application_config (channel_code);
查询语句
explain select product_no,channel_code,created_date from product_application_config where product_no = 'dummy' order by created_date
查询Extra字段显示Using filesort,表示需要排序
步骤(全字段排序)
- MySQL会给每个线程分配一块内存,称为sort_buffer
- 初始化sort_buffer,根据product查找到出满足条件的主键id
- 到id索引取出整行,取出product_no、channel_code、create_date三个字段,存入sort_buffer中
- 重复2 3步骤取出所有满足的数据
- 对sort_buffer中的create_date字段做快速排序
- 按照排序结果把数据返回给客户端
排序
排序这个动作可能会在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数sort_buffer_size
- sort_buffer_size:就是MySQL为排序开辟的内存
- 如果排序所需内存小于sort_buffer_size,那么排序在内存在完成
- 如果排序所需内存太大,则不得不利用磁盘临时文件辅助排序(通过查看OPTIMIZER_TRACE的number_of_temp_files参数来确认是否使用了临时文件,大于0就使用了,排序所需内存越大 数字越大,简单理解就是MySQL将需要排序的数据分成了多份,每份单独排序完再组成一个大的有序文件)
如果单行长度过长(rowid排序)
由上面得知,MySQL会把要返回的字段放入sort_buffer_size,那么如果要返回的字段很大,这样内存里能同时存放下的行数很少,要分成多个临时文件,性能很差。
解决方法: 修改max_length_for_sort_data,当要返回的数据长度大于该参数,MySQL就会进行优化,具体流程如下:
- 初始化sort_buffer,确定放入product_no和id两个字段
- 索引product_no找到第一个满足product_no = ‘dummy’的条件,取出该主键id
- 通过id索引出整行,取 id和created_date放入sort_buffer中
- 索引produt_no取下一个记录的主键id
- 重复234取出所有满足的条件的记录,并将它们的id和created_date放入sort_buffer中
- 对sort_buffer中的created_date进行排序
- 遍历排序结果,按找id从原表中取出要返回的字段给客户端
总结:当要返回的字段长度大于max_length_for_sort_data时,根据where条件查到满足的记录,然后将排序条件和主键放入sort_buffer中,而不是所有的返回字段