1、redis过期键删除?
定期删除 + 惰性删除
- 定期删除 :默认每隔100ms随机抽取一些设置了过期时间的key进行删除
- 惰性删除 :查询key的时候,懒惰的检查一下
2、内存淘汰机制?
- noeviction : 当内存不足以容纳新写入数据时,新写入数据会报错
- allkeys-lru :移除最近最少使用的key(最常用)
- allkeys-random : 随机
- volatile-lru : 在设置了过期时间的key中,移除最近最少使用的key
- volatile-random : 过期key中,随机删除
3、手写LRU算法
public class LRUCache<K,V> extends LinkedHashMap<K,V> { private int cacheSize; public LRUCache(int cacheSize) { super(16,0.75f,true); this.cacheSize = cacheSize; } /** * 判断元素个数是否超过缓存容量 */ @Override protected boolean removeEldestEntry(Map.Entry<K, V> eldest) { return size() > cacheSize; } }
4、如何保证Redis的高并发和高可用?Redis的主从复制原理?哨兵原理?
- 高并发:主从架构,一主多从,一般来说很多项目已经足够了,单主用来写入数据,单机几万QPS,多从用来查询数据,可以水平扩展
- 高可用:Sentinel哨兵 + Redis主从,哨兵本身是分布式的,至少需要3个实例
- 异步复制导致数据丢失、脑裂:min-slave-to-writer、min-slave-max-lag
- 哨兵的master选举算法:
- 跟master断开的时间长度
- 优先级
- 复制offset
- run id
- quorum数量的哨兵认为sdown就会转换为odown,然后得到majority数量哨兵的授权,转换为master
5、RDB 和 AOF
- RDB持久化就是把当前进程数据生成快照保存到磁盘的过程。
- 触发的机制 :
- 手动触发: bgsave 和 save 命令
- save : 阻塞直至RDB操作完成
- bgsave : fork子进程,RDB持久化交给子进程完成
- 自动触发:
- save相关配置 ,比如说save m n 那么就是如果数据集在m秒内改动了n次,就触发
- shutdown,如果没有开启AOF配置,那么默认执行RDB
- 从节点进行全量复制的时候
- 手动触发: bgsave 和 save 命令
- AOF:
- 以append-only模式将每次的写命令存在独立的文件中,系统重启通过重放命令达到数据恢复的效果
- 触发机制:
- bgrewriteaof
- 根据auto-aof-rewrite-min-size 和 auto-aof-rewrite-percentage参数
- 流程:
- 所有写命令追加到aof_buf缓冲区中
- AOF缓冲区根据对应的策略像磁盘做同步操作(always :每条写命令都写磁盘,everysec :fsync操作每秒执行一次 ,no :同步硬盘操作由系统完成,通常最长30秒)
- 随着AOF文件越来越大,需要定期向AOF文件进行重写,达到压缩的目的
- 内过期数据不再写入文件
- 将无效命令直接由内存数据生成,如del key,set a 1、set a 2
- Redis重启重放AOF文件,进行数据恢复
6、缓存穿透和缓存雪崩?
缓存雪崩
- 场景:缓存宕机,大量请求打到数据库直接打死
- 解决:
- 事前:Redis高可用
- 事中:本地ehcache缓存 + hystrix限流和降级,防止数据库被打死
- 事后:redis持久化机制恢复内存数据
缓存穿透
- 场景:瞬时大量的不存在的key请求,数据库又被打死了
- 解决:每次只要查不到,就写一个空值到缓存中去
7、缓存与数据库双写一致性?
读的时候先读缓存,缓存没有就读数据库,然后取出数据放入缓存,同时返回响应。写的时候先删除缓存,后更新数据库。
高并发的情况下还是会出现双写不一致问题,可以将相同key的读写放在一个队列中(可以通过hash值对队列数量取模),达到顺序执行的效果。
8、Redis并发竞争问题?
分布式锁保证同一时间只能有一个系统能操作key,写的时候判断本次的时间戳是否晚于db库中的时间戳。
9、为什么redis那么快
- 内存操作
- 非阻塞的IO多路复用
- 单线程避免了上下文切换的性能消耗
10、redis的文件事件处理器
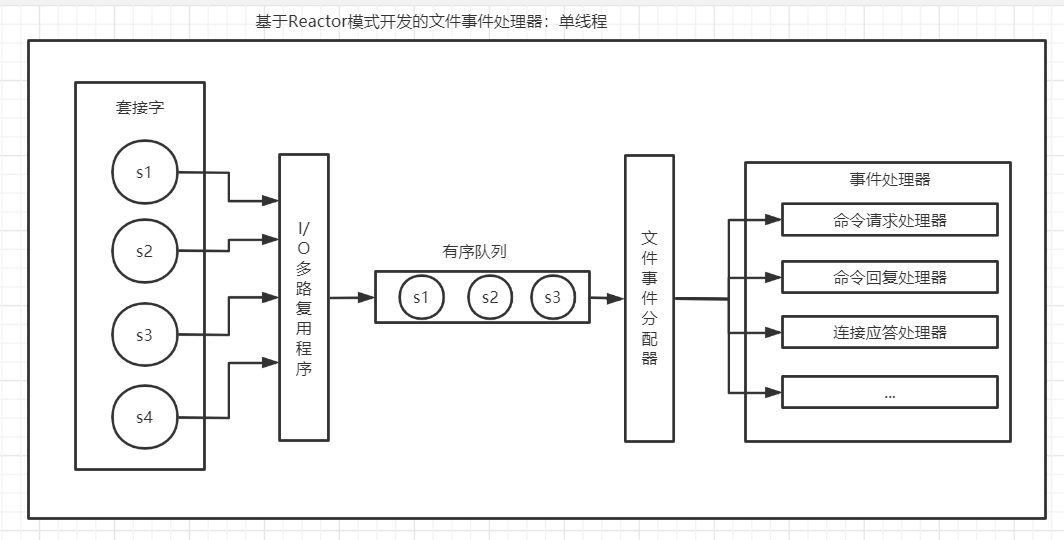

一次完整的客户端与服务器连接事件示例:
- 一个redis客户端向服务器发起连接,产生一个AE_READABLE事件,触发连接应答处理器执行。处理器响应客户端连接请求,创建客户端套接字并将客户端套接字的AE_READABLE事件与命令请求处理器关联,使得客户端可以向服务器发送命令请求
- 客户端向服务器发送一个命令请求,那么客户端套接字会产生一个AE_READABLE事件,引发命令请求处理器执行
- 服务器将客户端套接字的AE_WRITABLE事件与命令回复处理器进行关联,当客户端尝试读取命令回复的时候,客户端将产生AE_READABLE事件,触发命令回复处理器执行,当命令回复处理器将命令回复全部写入套接字后,服务器会解除客户端套接字AE_WRITEABLE事件与命令回复处理器之间的联系。
11、Redis的应用场景
- 缓存
- 共享session
- 消息队列
- 分布式锁
12、Redis支持的数据类型 (看看自己的redis整理)
- String
- list
- hash
- set
- zset
- HyperLogLog :
- pfadd(添加)、pfcount(统计)、pfmerge(合并多个key的计数)、pf是发明者的英文首字母
- 准备率在0.81
- 在计数比较小时,它的存储空间采用稀疏矩阵存储,空间占用很小,仅仅在计数慢慢变大,稀疏矩阵占用空间渐渐超过了阈值时才会一次性转变成稠密矩阵,才会占用 12k 的空间
- HyperLogLog 实现中用到的是 16384 个桶,也就是 2^14,每个桶的 maxbits 需要 6 个 bits 来存储,最大可以表示 maxbits=63,于是总共占用内存就是
2^14 * 6 / 8 = 12k字节。
- Bloom Filter :当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在
- bf.add : 添加元素
- bf.exists : 查询元素是否存在
- bf.madd : 批量添加
- bf.mexists : 批量查询元素是否存在
- 向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致
- geo :
- geoadd 指令携带集合名称以及多个经纬度名称三元组,注意这里可以加入多个三元组
- geodist 指令可以用来计算两个元素之间的距离,携带集合名称、2 个名称和距离单位
- geopos 指令可以获取集合中任意元素的经纬度坐标,可以一次获取多个
- geohash 可以获取元素的经纬度编码字符串
- georadiusbymember 指令是最为关键的指令,它可以用来查询指定元素附近的其它元素
- georadius 根据用户的定位来计算「附近的车」,「附近的餐馆」等.它的参数和 georadiusbymember 基本一致,除了将目标元素改成经纬度坐标值
13、skipList跳表的数据结构
- 跳跃表是在一种有序数据结构,它通过在每个节点维护多个指向其他节点的指针,从而达到快速访问节点的目的
- 有待补充