根据泰勒展开式:
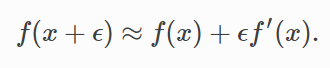

于是:
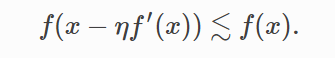
于是,我们可以通过迭代 x,不断减小 f(x)

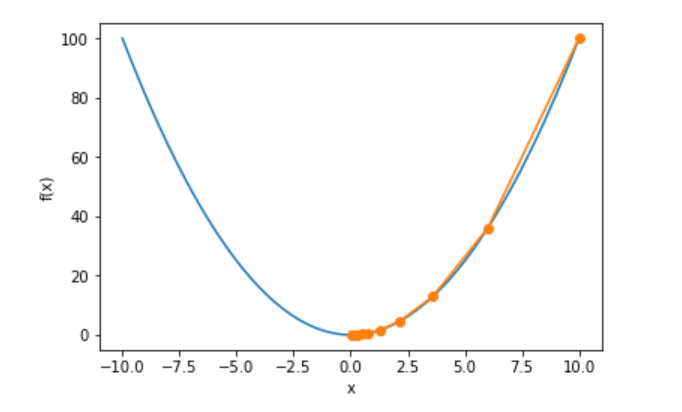
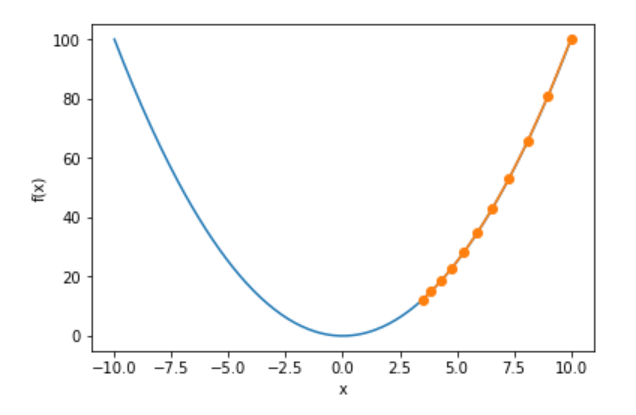
import math import matplotlib import numpy as np import gluonbook as gb from mxnet import nd,autograd,init,gluon def gd(eta): x = 10 resulte = [x] for i in range(10): x -= eta*2*x resulte.append(x) print(x) return resulte res = gd(0.2) def show_trace(res): n = max(abs(min(res)),abs(max(res)),10) f_line = np.arange(-n,n,0.1) gb.plt.plot(f_line,[x*x for x in f_line]) gb.plt.plot(res,[x*x for x in res],'-o') gb.plt.xlabel('x') gb.plt.ylabel('f(x)') show_trace(res) show_trace(gd(0.05)) show_trace(gd(1.1))
参数太小,使得到达不了最优值,参数太大,那这个泰勒展开式不成立,f(x) 可能不会减小。