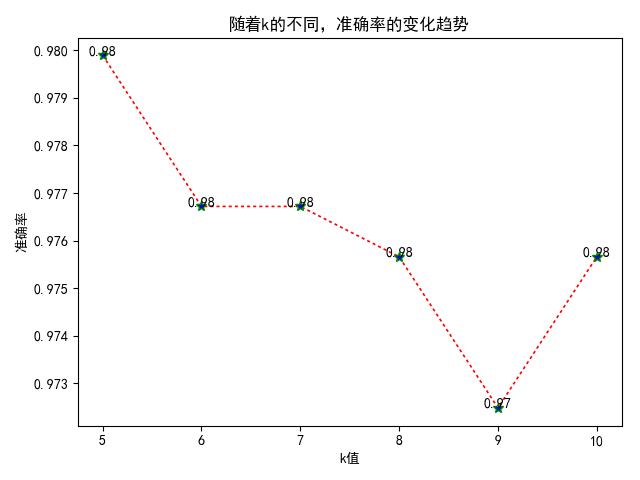
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 import os 5 from sklearn.neighbors import KNeighborsClassifier # knn分类 6 7 8 def build_data(file_path): 9 """ 10 加载并处理数据 11 :param file_path:文件夹路径 12 :return: 数据集 13 """ 14 # 获取文件名称 15 file_name_list = os.listdir(file_path) 16 print("file_name_list: ", file_name_list) 17 18 # 加载每一个文件中的内容 19 # for循环加载 20 # 大数组 21 data_arr = np.zeros(shape=(len(file_name_list), 1025)) 22 for file_index, file_name in enumerate(file_name_list): 23 # 获取文件序号 文件名称 24 # print("file_index:", file_index) 25 # print("file_name:", file_name) 26 # 获取每一个文件的文件内容 27 file_content = np.loadtxt(file_path + "/" + file_name, dtype=np.str) 28 # print("file_content: ", file_content) 29 # 单个样本 30 single_sample_feture = np.zeros(shape=(len(file_content), 32)) 31 for file_content_num, file_content_data in enumerate(file_content): 32 # print("file_content_num:", file_content_num) 33 # print("file_content_data:", file_content_data) 34 # 将每一个元素转化 数值类型 0 1 0 1 35 # 法1 36 # li = [int(i) for i in file_content_data] 37 # print(li) 38 # map函数 39 li = list(map(int, file_content_data)) 40 # print(li) 41 single_sample_feture[file_content_num, :] = li 42 # print(single_sample_feture) 43 # 将样本的二维数组展开成一维 作为样本的特征值 44 single_data_arr_feature = single_sample_feture.ravel() 45 # 将单个样本的特征值加到data_arr 46 data_arr[file_index, :1024] = single_data_arr_feature 47 48 # 获取目标值 49 target = file_name.split("_")[0] 50 51 # 将目标值添加到数组中 52 data_arr[file_index, 1024] = target 53 54 # print("data_arr: ",data_arr) 55 # print("data_arr 的形状: ",data_arr.shape) 56 57 return data_arr 58 59 60 def save_data(file_data, file_name): 61 """ 62 保存数据 63 :param file_data: 数据 64 :param file_name: 文件名称 65 :return: None 66 """ 67 # 如果data 文件不存在,就创建,如果存在,则不执行 68 if not os.path.exists("./data"): 69 os.makedirs("./data") 70 # 保存文件 71 np.save("./data/" + file_name, file_data) 72 73 74 def load_data(): 75 """ 76 加载数据 77 :return:train test 78 """ 79 train = np.load("./data/train_data.npy") 80 test = np.load("./data/test_data.npy") 81 82 return train, test 83 84 85 def distance(v1, v2): 86 """ 87 计算距离 88 :param v1:点1 89 :param v2: 点2 90 :return: 距离dist 91 """ 92 # 法1 93 # v1 是矩阵 将矩阵转化数组,再进行降为1维 94 # v1 = v1.A[0] 95 # print(v1) 96 # sum_ = 0 97 # for i in range(v1.shape[0]): 98 # sum_ += (v1[i] - v2[i]) ** 2 99 # dist = np.sqrt(sum_) 100 # print(dist) 101 # 法2 102 dist = np.sqrt(np.sum(np.power((v1 - v2), 2))) 103 return dist 104 105 106 def knn_owns(train, test, k): 107 """ 108 knn识别手写字 109 :param train: 训练集 110 :param test: 测试集 111 :param k: 邻居个数 112 :return: 准确率 113 """ 114 true_num = 0 115 # 计算每一个测试样本与每一个训练样本的距离 116 for i in range(test.shape[0]): 117 # 构建数组 来保存 每一个测试样本与所有训练样本的距离 118 arr_dist = np.zeros(shape=(train.shape[0], 1)) 119 for j in range(train.shape[0]): 120 dist = distance(test[i, :1024], train[j, :1024]) 121 arr_dist[j, 0] = dist 122 # print(arr_dist) 123 # 将距离与训练集的目标值 组合起来 124 mutile_arr = np.concatenate((arr_dist, train[:, 1024].reshape((-1, 1))), axis=1) 125 # 因为数组排序不是整个样本一块动---排序---dataframe 126 res_df = pd.DataFrame(data=mutile_arr, columns=["dist", "target"]) 127 # print(res_df) 128 # 按照距离进行升序排序 129 y_predict = res_df.sort_values(by="dist")["target"].head(k).mode()[0] 130 # print("y_predict:", y_predict) 131 if test[i, 1024] == y_predict: 132 true_num += 1 133 # 准确率 134 score = true_num / test.shape[0] 135 136 return score 137 138 139 def show_res(score_list, k_list): 140 """ 141 结果展示 142 :param score_list: 准确率列表 143 :param k_list: k列表 144 :return: None 145 """ 146 # 1、创建画布 147 plt.figure() 148 # 修改RC参数,来让其支持中文 149 plt.rcParams['font.sans-serif'] = 'SimHei' 150 plt.rcParams['axes.unicode_minus'] = False 151 # 2、绘图 152 plt.plot(k_list, score_list, color='r', linestyle=':', linewidth=1.2, marker="*", markersize=7, markerfacecolor='b', 153 markeredgecolor='g') 154 # 增加标题 155 plt.title("随着k的不同,准确率的变化趋势") 156 # 增加横轴、纵轴名称 157 plt.xlabel("k值") 158 plt.ylabel("准确率") 159 # 增加横轴刻度 160 plt.xticks(k_list) 161 # 标注 162 for i, j in zip(k_list, score_list): 163 plt.text(i, j, "%.2f" % j, horizontalalignment='center') 164 # 保存图片 165 plt.savefig("./准确率变化走势图_sklearn.png") 166 # 3、展示 167 plt.show() 168 169 170 def knn_owns_yh(train, test, k): 171 """ 172 优化之后的Knn算法 173 :param train: 训练集 174 :param test: 测试集 175 :param k:邻居个数 176 :return: 准确率 177 """ 178 # 最终的训练集中心 179 data = np.zeros(shape=(10, 1025)) 180 # 取训练集的各个中心来代替训练集 181 for i in range(10): 182 # i 0 1 2 .. 9 183 bool_index = train[:, 1024] == i 184 # 使用bool数组 185 data[i, :] = train[bool_index, :].mean(axis=0) 186 187 print("data: ",data) 188 189 # 训练 190 true_num = 0 191 # 计算每一个测试样本与每一个训练样本的距离 192 for i in range(test.shape[0]): 193 # 构建数组 来保存 每一个测试样本与所有训练样本的距离 194 arr_dist = np.zeros(shape=(data.shape[0], 1)) 195 for j in range(data.shape[0]): 196 dist = distance(test[i, :1024], data[j, :1024]) 197 arr_dist[j, 0] = dist 198 # print(arr_dist) 199 # 将距离与训练集的目标值 组合起来 200 mutile_arr = np.concatenate((arr_dist, data[:, 1024].reshape((-1, 1))), axis=1) 201 # 因为数组排序不是整个样本一块动---排序---dataframe 202 res_df = pd.DataFrame(data=mutile_arr, columns=["dist", "target"]) 203 # print(res_df) 204 # 按照距离进行升序排序 205 y_predict = res_df.sort_values(by="dist")["target"].head(k).mode()[0] 206 # print("y_predict:", y_predict) 207 if test[i, 1024] == y_predict: 208 true_num += 1 209 # 准确率 210 score = true_num / test.shape[0] 211 212 return score 213 214 215 216 217 def main(): 218 """ 219 主函数 220 :return: 221 """ 222 # # 1、加载并处理数据 223 # train = build_data("./trainingDigits") 224 # test = build_data("./testDigits") 225 # 226 # print("train: ",train) 227 # print("train的形状: ",train.shape) 228 # 229 # print("test: ", test) 230 # print("test的形状: ", test.shape) 231 # 232 # # 2、保存训练集与测试集数据 233 # save_data(train,"train_data") 234 # save_data(test,"test_data") 235 236 # 1、加载数据 237 train, test = load_data() 238 print("train: ", train) 239 print("test: ", test) 240 241 # 2、优化版 的knn 242 k = 1 243 score = knn_owns_yh(train, test, k) 244 245 print("准确率: ",score) 246 247 # 2、自实现knn算法 248 # score_list = [] 249 # k_list = [5, 6, 7, 8, 9, 10] 250 # # 自实现knn原理识别手写字 251 # for k in k_list: 252 # score = knn_owns(train, test, k) 253 # 254 # score_list.append(score) 255 # print("score_list: ", score_list) 256 257 # 使用sklearn 中的knn算法进行手写字识别 258 # for k in k_list: 259 # # (1)初始化算法实例 260 # knn = KNeighborsClassifier(n_neighbors=k) 261 # # (2) 训练数据 262 # knn.fit(train[:, :1024], train[:, 1024]) 263 # # (3) 进行预测 264 # y_predict = knn.predict(test[:, :1024]) 265 # 266 # # 获取准确率 267 # score = knn.score(test[:, :1024], test[:, 1024]) 268 # 269 # print("预测值 y_predict: ", y_predict) 270 # score_list.append(score) 271 272 # 3、结果展示 273 # show_res(score_list, k_list) 274 275 276 if __name__ == '__main__': 277 main()