一.troubleshooting之控制shuffle reduce端缓冲大小以避免OOM

二.troubleshooting之解决JVM GC导致的shuffle文件拉取失败
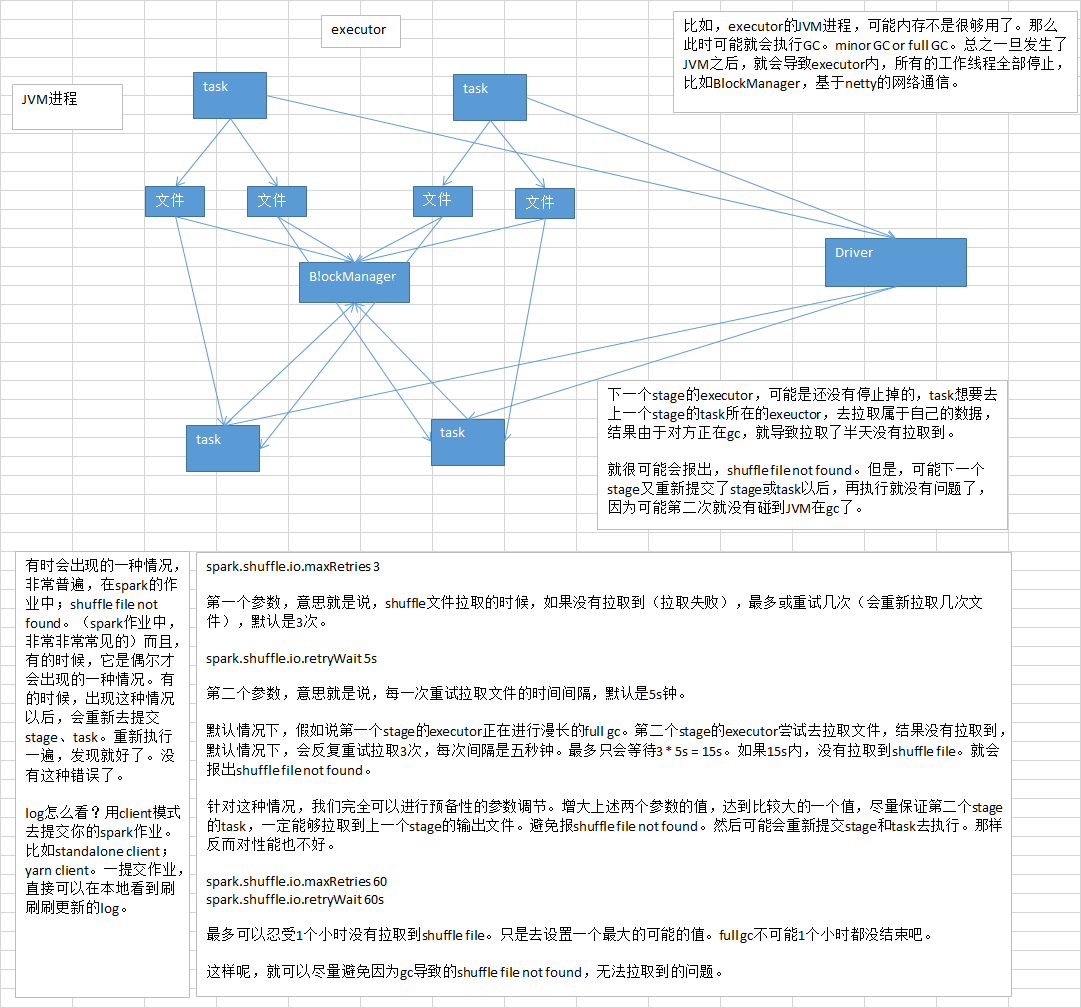
三.troubleshooting之解决YARN队列资源不足导致的application直接失败
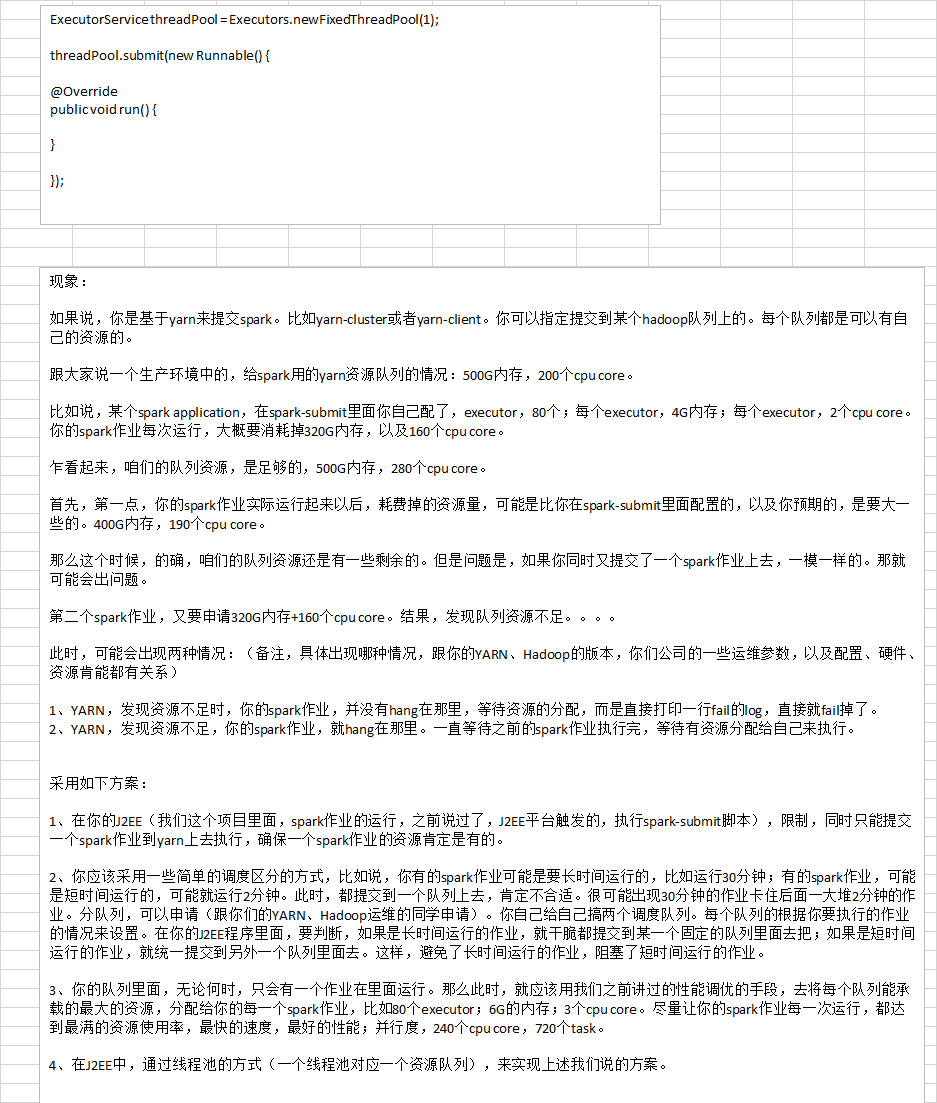
四.troubleshooting之解决各种序列化导致的报错
你会看到什么样的序列化导致的报错?
用client模式去提交spark作业,观察本地打印出来的log。如果出现了类似于Serializable、Serialize等等字眼,报错的log,那么恭喜大家,就碰到了序列化问题导致的报错。
虽然是报错,但是序列化报错,应该是属于比较简单的了,很好处理。
序列化报错要注意的三个点:
1、你的算子函数里面,如果使用到了外部的自定义类型的变量,那么此时,就要求你的自定义类型,必须是可序列化的。
final Teacher teacher = new Teacher("leo");
studentsRDD.foreach(new VoidFunction() {
public void call(Row row) throws Exception {
String teacherName = teacher.getName();
....
}
});
public class Teacher implements Serializable {
}
2、如果要将自定义的类型,作为RDD的元素类型,那么自定义的类型也必须是可以序列化的
JavaPairRDD<Integer, Teacher> teacherRDD
JavaPairRDD<Integer, Student> studentRDD
studentRDD.join(teacherRDD)
public class Teacher implements Serializable {
}
public class Student implements Serializable {
}
3、不能在上述两种情况下,去使用一些第三方的,不支持序列化的类型
Connection conn =
studentsRDD.foreach(new VoidFunction() {
public void call(Row row) throws Exception {
conn.....
}
});
Connection是不支持序列化的
五.troubleshooting之解决算子函数返回NULL导致的问题
在算子函数中,返回null
// return actionRDD.mapToPair(new PairFunction<Row, String, Row>() {
//
// private static final long serialVersionUID = 1L;
//
// @Override
// public Tuple2<String, Row> call(Row row) throws Exception {
// return new Tuple2<String, Row>("-999", RowFactory.createRow("-999"));
// }
//
// });
大家可以看到,在有些算子函数里面,是需要我们有一个返回值的。但是,有时候,我们可能对某些值,就是不想有什么返回值。我们如果直接返回NULL的话,那么可以不幸的告诉大家,是不行的,会报错的。
Scala.Math(NULL),异常
如果碰到你的确是对于某些值,不想要有返回值的话,有一个解决的办法:
1、在返回的时候,返回一些特殊的值,不要返回null,比如“-999”
2、在通过算子获取到了一个RDD之后,可以对这个RDD执行filter操作,进行数据过滤。filter内,可以对数据进行判定,如果是-999,那么就返回false,给过滤掉就可以了。
3、大家不要忘了,之前咱们讲过的那个算子调优里面的coalesce算子,在filter之后,可以使用coalesce算子压缩一下RDD的partition的数量,让各个partition的数据比较紧凑一些。也能提升一些性能。
六.troubleshooting之解决yarn-client模式导致的网卡流量激增问题
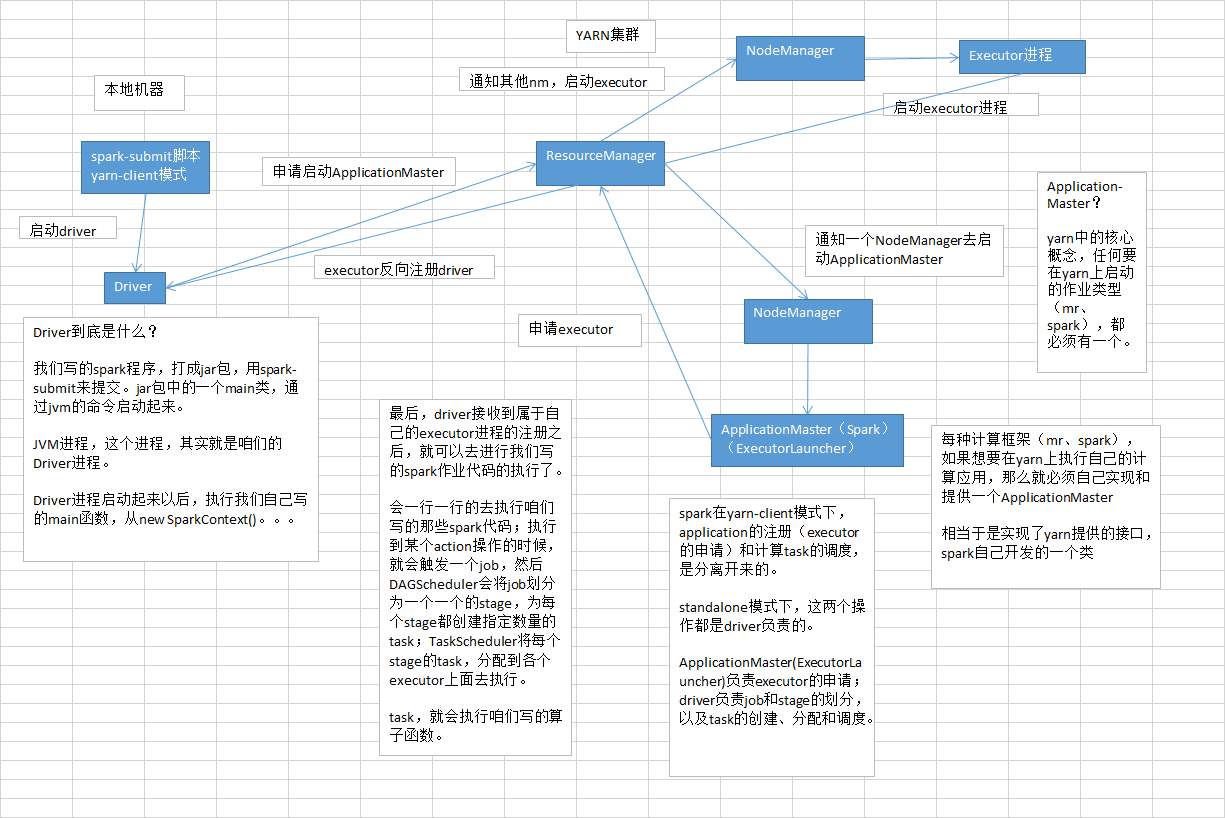
yarn-client模式下,会产生什么样的问题呢?
由于咱们的driver是启动在本地机器的,而且driver是全权负责所有的任务的调度的,也就是说要跟yarn集群上运行的多个executor进行频繁的通信(中间有task的启动消息、task的执行统计消息、task的运行状态、shuffle的输出结果)。
咱们来想象一下。比如你的executor有100个,stage有10个,task有1000个。每个stage运行的时候,都有1000个task提交到executor上面去运行,平均每个executor有10个task。接下来问题来了,driver要频繁地跟executor上运行的1000个task进行通信。通信消息特别多,通信的频率特别高。运行完一个stage,接着运行下一个stage,又是频繁的通信。
在整个spark运行的生命周期内,都会频繁的去进行通信和调度。所有这一切通信和调度都是从你的本地机器上发出去的,和接收到的。这是最要人命的地方。你的本地机器,很可能在30分钟内(spark作业运行的周期内),进行频繁大量的网络通信。那么此时,你的本地机器的网络通信负载是非常非常高的。会导致你的本地机器的网卡流量会激增!!!
你的本地机器的网卡流量激增,当然不是一件好事了。因为在一些大的公司里面,对每台机器的使用情况,都是有监控的。不会允许单个机器出现耗费大量网络带宽等等这种资源的情况。运维人员。可能对公司的网络,或者其他(你的机器还是一台虚拟机),对其他机器,都会有负面和恶劣的影响。
解决的方法:
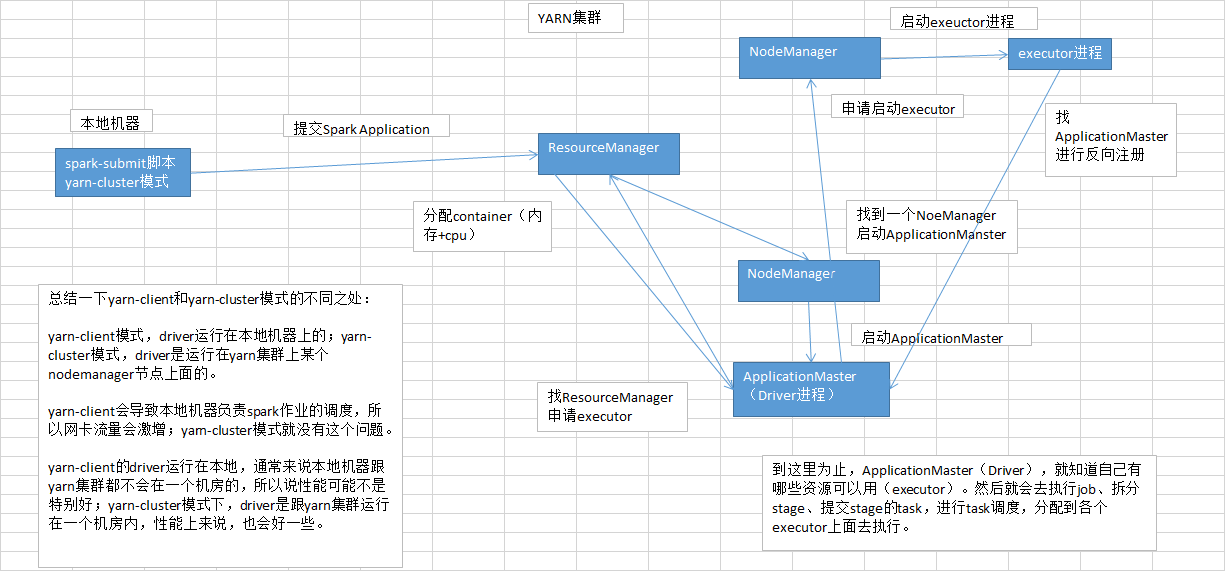
实际上解决的方法很简单,就是心里要清楚,yarn-client模式是什么情况下,可以使用的?yarn-client模式,通常咱们就只会使用在测试环境中,你写好了某个spark作业,打了一个jar包,在某台测试机器上,用yarn-client模式去提交一下。因为测试的行为是偶尔为之的,不会长时间连续提交大量的spark作业去测试。还有一点好处,yarn-client模式提交,可以在本地机器观察到详细全面的log。通过查看log,可以去解决线上报错的故障(troubleshooting)、对性能进行观察并进行性能调优。
实际上线了以后,在生产环境中,都得用yarn-cluster模式,去提交你的spark作业。
yarn-cluster模式,就跟你的本地机器引起的网卡流量激增的问题,就没有关系了。也就是说,就算有问题,也应该是yarn运维团队和基础运维团队之间的事情了。使用了yarn-cluster模式以后,就不是你的本地机器运行Driver,进行task调度了。是yarn集群中,某个节点会运行driver进程,负责task调度。
七.troubleshooting之解决yarn-cluster模式的JVM栈内存溢出问题
实践经验,碰到的yarn-cluster的问题:
有的时候,运行一些包含了spark sql的spark作业,可能会碰到yarn-client模式下,可以正常提交运行;yarn-cluster模式下,可能是无法提交运行的,会报出JVM的PermGen(永久代)的内存溢出,OOM。
yarn-client模式下,driver是运行在本地机器上的,spark使用的JVM的PermGen的配置,是本地的spark-class文件(spark客户端是默认有配置的),JVM的永久代的大小是128M,这个是没有问题的;但是呢,在yarn-cluster模式下,driver是运行在yarn集群的某个节点上的,使用的是没有经过配置的默认设置(PermGen永久代大小),82M。
spark-sql,它的内部是要进行很复杂的SQL的语义解析、语法树的转换等等,特别复杂,在这种复杂的情况下,如果说你的sql本身特别复杂的话,很可能会比较导致性能的消耗,内存的消耗。可能对PermGen永久代的占用会比较大。
所以,此时,如果对永久代的占用需求,超过了82M的话,但是呢又在128M以内;就会出现如上所述的问题,yarn-client模式下,默认是128M,这个还能运行;如果在yarn-cluster模式下,默认是82M,就有问题了。会报出PermGen Out of Memory error log。
如何解决这种问题?
既然是JVM的PermGen永久代内存溢出,那么就是内存不够用。咱们呢,就给yarn-cluster模式下的,driver的PermGen多设置一些。
spark-submit脚本中,加入以下配置即可:
--conf spark.driver.extraJavaOptions="-XX:PermSize=128M -XX:MaxPermSize=256M"
这个就设置了driver永久代的大小,默认是128M,最大是256M。那么,这样的话,就可以基本保证你的spark作业不会出现上述的yarn-cluster模式导致的永久代内存溢出的问题。
spark sql,sql,要注意,一个问题
sql,有大量的or语句。比如where keywords='' or keywords='' or keywords=''
当达到or语句,有成百上千的时候,此时可能就会出现一个driver端的jvm stack overflow,JVM栈内存溢出的问题
JVM栈内存溢出,基本上就是由于调用的方法层级过多,因为产生了大量的,非常深的,超出了JVM栈深度限制的,递归。递归方法。我们的猜测,spark sql,有大量or语句的时候,spark sql内部源码中,在解析sql,比如转换成语法树,或者进行执行计划的生成的时候,对or的处理是递归。or特别多的话,就会发生大量的递归。
JVM Stack Memory Overflow,栈内存溢出。
这种时候,建议不要搞那么复杂的spark sql语句。采用替代方案:将一条sql语句,拆解成多条sql语句来执行。每条sql语句,就只有100个or子句以内;一条一条SQL语句来执行。根据生产环境经验的测试,一条sql语句,100个or子句以内,是还可以的。通常情况下,不会报那个栈内存溢出。
八.troubleshooting之错误的持久化方式以及checkpoint的使用
错误的持久化使用方式:
usersRDD,想要对这个RDD做一个cache,希望能够在后面多次使用这个RDD的时候,不用反复重新计算RDD;可以直接使用通过各个节点上的executor的BlockManager管理的内存 / 磁盘上的数据,避免重新反复计算RDD。
usersRDD.cache()
usersRDD.count()
usersRDD.take()
上面这种方式,不要说会不会生效了,实际上是会报错的。会报什么错误呢?会报一大堆file not found的错误。
正确的持久化使用方式:
usersRDD
usersRDD = usersRDD.cache()
val cachedUsersRDD = usersRDD.cache()
之后再去使用usersRDD,或者cachedUsersRDD,就可以了。就不会报错了。所以说,这个是咱们的持久化的正确的使用方式。
持久化,大多数时候,都是会正常工作的。但是就怕,有些时候,会出现意外。
比如说,缓存在内存中的数据,可能莫名其妙就丢失掉了。
或者说,存储在磁盘文件中的数据,莫名其妙就没了,文件被误删了。
出现上述情况的时候,接下来,如果要对这个RDD执行某些操作,可能会发现RDD的某个partition找不到了。
对消失的partition重新计算,计算完以后再缓存和使用。
有些时候,计算某个RDD,可能是极其耗时的。可能RDD之前有大量的父RDD。那么如果你要重新计算一个partition,可能要重新计算之前所有的父RDD对应的partition。
这种情况下,就可以选择对这个RDD进行checkpoint,以防万一。进行checkpoint,就是说,会将RDD的数据,持久化一份到容错的文件系统上(比如hdfs)。
在对这个RDD进行计算的时候,如果发现它的缓存数据不见了。优先就是先找一下有没有checkpoint数据(到hdfs上面去找)。如果有的话,就使用checkpoint数据了。不至于说是去重新计算。
checkpoint,其实就是可以作为是cache的一个备胎。如果cache失效了,checkpoint就可以上来使用了。

checkpoint有利有弊,利在于,提高了spark作业的可靠性,一旦发生问题,还是很可靠的,不用重新计算大量的rdd;但是弊在于,进行checkpoint操作的时候,也就是将rdd数据写入hdfs中的时候,还是会消耗性能的。
checkpoint,用性能换可靠性。
checkpoint原理:
1、在代码中,用SparkContext,设置一个checkpoint目录,可以是一个容错文件系统的目录,比如hdfs;
2、在代码中,对需要进行checkpoint的rdd,执行RDD.checkpoint();
3、RDDCheckpointData(spark内部的API),接管你的RDD,会标记为marked for checkpoint,准备进行checkpoint
4、你的job运行完之后,会调用一个finalRDD.doCheckpoint()方法,会顺着rdd lineage,回溯扫描,发现有标记为待checkpoint的rdd,就会进行二次标记,inProgressCheckpoint,正在接受checkpoint操作
5、job执行完之后,就会启动一个内部的新job,去将标记为inProgressCheckpoint的rdd的数据,都写入hdfs文件中。(备注,如果rdd之前cache过,会直接从缓存中获取数据,写入hdfs中;如果没有cache过,那么就会重新计算一遍这个rdd,再checkpoint)
6、将checkpoint过的rdd之前的依赖rdd,改成一个CheckpointRDD*,强制改变你的rdd的lineage。后面如果rdd的cache数据获取失败,直接会通过它的上游CheckpointRDD,去容错的文件系统,比如hdfs,中,获取checkpoint的数据。
说一下checkpoint的使用
1、SparkContext,设置checkpoint目录
2、对RDD执行checkpoint操作