Hbase和mapreduce结合
为什么需要用mapreduce去访问hbase的数据?
——加快分析速度和扩展分析能力
Mapreduce访问hbase数据作分析一定是在离线分析的场景下应用
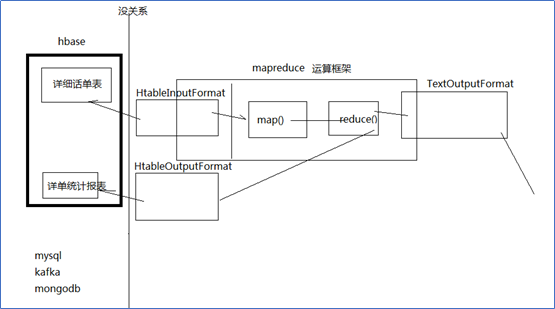
案例1、HBase表数据的转移
在Hadoop阶段,我们编写的MR任务分别进程了Mapper和Reducer两个类,而在HBase中我们需要继承的是TableMapper和TableReducer两个类。
目标:将fruit表中的一部分数据,通过MR迁入到fruit_mr表中
Step1、构建ReadFruitMapper类,用于读取fruit表中的数据
import java.io.IOException;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
public class ReadFruitMapper extends TableMapper<ImmutableBytesWritable, Put> {
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context)
throws IOException, InterruptedException {
//将fruit的name和color提取出来,相当于将每一行数据读取出来放入到Put对象中。
Put put = new Put(key.get());
//遍历添加column行
for(Cell cell: value.rawCells()){
//添加/克隆列族:info
if("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))){
//添加/克隆列:name
if("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){
//将该列cell加入到put对象中
put.add(cell);
//添加/克隆列:color
}else if("color".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){
//向该列cell加入到put对象中
put.add(cell);
}
}
}
//将从fruit读取到的每行数据写入到context中作为map的输出
context.write(key, put);
}
}
Step2、构建WriteFruitMRReducer类,用于将读取到的fruit表中的数据写入到fruit_mr表中
import java.io.IOException;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
public class WriteFruitMRReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {
@Override
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context)
throws IOException, InterruptedException {
//读出来的每一行数据写入到fruit_mr表中
for(Put put: values){
context.write(NullWritable.get(), put);
}
}
}
Step3、构建Fruit2FruitMRJob extends Configured implements Tool,用于组装运行Job任务
//组装Job
public int run(String[] args) throws Exception {
//得到Configuration
Configuration conf = this.getConf();
//创建Job任务
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
job.setJarByClass(Fruit2FruitMRJob.class);
//配置Job
Scan scan = new Scan();
scan.setCacheBlocks(false);
scan.setCaching(500);
//设置Mapper,注意导入的是mapreduce包下的,不是mapred包下的,后者是老版本
TableMapReduceUtil.initTableMapperJob(
"fruit", //数据源的表名
scan, //scan扫描控制器
ReadFruitMapper.class,//设置Mapper类
ImmutableBytesWritable.class,//设置Mapper输出key类型
Put.class,//设置Mapper输出value值类型
job//设置给哪个JOB
);
//设置Reducer
TableMapReduceUtil.initTableReducerJob("fruit_mr", WriteFruitMRReducer.class, job);
//设置Reduce数量,最少1个
job.setNumReduceTasks(1);
boolean isSuccess = job.waitForCompletion(true);
if(!isSuccess){
throw new IOException("Job running with error");
}
return isSuccess ? 0 : 1;
}
Step4、主函数中调用运行该Job任务
public static void main( String[] args ) throws Exception{
Configuration conf = HBaseConfiguration.create();
int status = ToolRunner.run(conf, new Fruit2FruitMRJob(), args);
System.exit(status);
}
案例2:从Hbase中读取数据、分析,写入hdfs
|
/** public abstract class TableMapper<KEYOUT, VALUEOUT> extends Mapper<ImmutableBytesWritable, Result, KEYOUT, VALUEOUT> { } * @author duanhaitao@gec.cn * */ public class HbaseReader {
public static String flow_fields_import = "flow_fields_import"; static class HdfsSinkMapper extends TableMapper<Text, NullWritable>{
@Override protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
byte[] bytes = key.copyBytes(); String phone = new String(bytes); byte[] urlbytes = value.getValue("f1".getBytes(), "url".getBytes()); String url = new String(urlbytes); context.write(new Text(phone + " " + url), NullWritable.get());
}
}
static class HdfsSinkReducer extends Reducer<Text, NullWritable, Text, NullWritable>{
@Override protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get()); } }
public static void main(String[] args) throws Exception { Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "spark01");
Job job = Job.getInstance(conf);
job.setJarByClass(HbaseReader.class);
// job.setMapperClass(HdfsSinkMapper.class); Scan scan = new Scan(); TableMapReduceUtil.initTableMapperJob(flow_fields_import, scan, HdfsSinkMapper.class, Text.class, NullWritable.class, job); job.setReducerClass(HdfsSinkReducer.class);
FileOutputFormat.setOutputPath(job, new Path("c:/hbasetest/output"));
job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class);
job.waitForCompletion(true); }
} |
2.3.2 从hdfs中读取数据写入Hbase
q
|
/** public abstract class TableReducer<KEYIN, VALUEIN, KEYOUT> extends Reducer<KEYIN, VALUEIN, KEYOUT, Writable> { } * @author duanhaitao@gec.cn * */ public class HbaseSinker {
public static String flow_fields_import = "flow_fields_import"; static class HbaseSinkMrMapper extends Mapper<LongWritable, Text, FlowBean, NullWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString(); String[] fields = line.split(" "); String phone = fields[0]; String url = fields[1];
FlowBean bean = new FlowBean(phone,url);
context.write(bean, NullWritable.get()); } }
static class HbaseSinkMrReducer extends TableReducer<FlowBean, NullWritable, ImmutableBytesWritable>{
@Override protected void reduce(FlowBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
Put put = new Put(key.getPhone().getBytes()); put.add("f1".getBytes(), "url".getBytes(), key.getUrl().getBytes());
context.write(new ImmutableBytesWritable(key.getPhone().getBytes()), put);
}
}
public static void main(String[] args) throws Exception { Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum", "spark01");
HBaseAdmin hBaseAdmin = new HBaseAdmin(conf);
boolean tableExists = hBaseAdmin.tableExists(flow_fields_import); if(tableExists){ hBaseAdmin.disableTable(flow_fields_import); hBaseAdmin.deleteTable(flow_fields_import); } HTableDescriptor desc = new HTableDescriptor(TableName.valueOf(flow_fields_import)); HColumnDescriptor hColumnDescriptor = new HColumnDescriptor ("f1".getBytes()); desc.addFamily(hColumnDescriptor);
hBaseAdmin.createTable(desc);
Job job = Job.getInstance(conf);
job.setJarByClass(HbaseSinker.class);
job.setMapperClass(HbaseSinkMrMapper.class); TableMapReduceUtil.initTableReducerJob(flow_fields_import, HbaseSinkMrReducer.class, job);
FileInputFormat.setInputPaths(job, new Path("c:/hbasetest/data"));
job.setMapOutputKeyClass(FlowBean.class); job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(ImmutableBytesWritable.class); job.setOutputValueClass(Mutation.class);
job.waitForCompletion(true);
}
} |