ES:
1:倒排索引
基于Document 关键词索引实现 、 根据关键词做索引 相关度
a. 数据结构
i. 包含关键词的Document List
ii. 关键词在每个doc中出现的次数 词频 TF term frequency
iii. 关键词在整个索引中出现的次数 IDF inverse doc frequency (TF_IDF 算法)
iv. 关键词在当前doc中出现的次数
v. 每个doc的长度,越长相关度越低
vi. 包含这个关键词的所有doc的平均长度
b. lucene
i. 宕机后节点数据丢失,没有容灾机制
ii. 自己进行数据管理,可用性差
iii. 单台节点,计算能力有线

2:ElasticSearch
• 优点
○ 开发友好、集群自动发现
○ 自动维护,数据在多个节点建立
○ 搜索进行负载均衡
○ 自动维护冗余副本,数据稳定
• 核心概念(doc 可以理解为MySQL一行记录,Type 相当于一张表 , index 相当于一个数据库)
○ Cluster(集群) 2个以上节点
○ Node 集群上的节点 , 节点 != 服务器
○ field: 一个数据字段,与 index和type一起可以进行doc定位
○ Document ES最小数据单元 JSON格式
○ Type:逻辑上的数据分类 7.X删除
○ Index : 一类相同或者类似的 doc 员工索引 商品索引
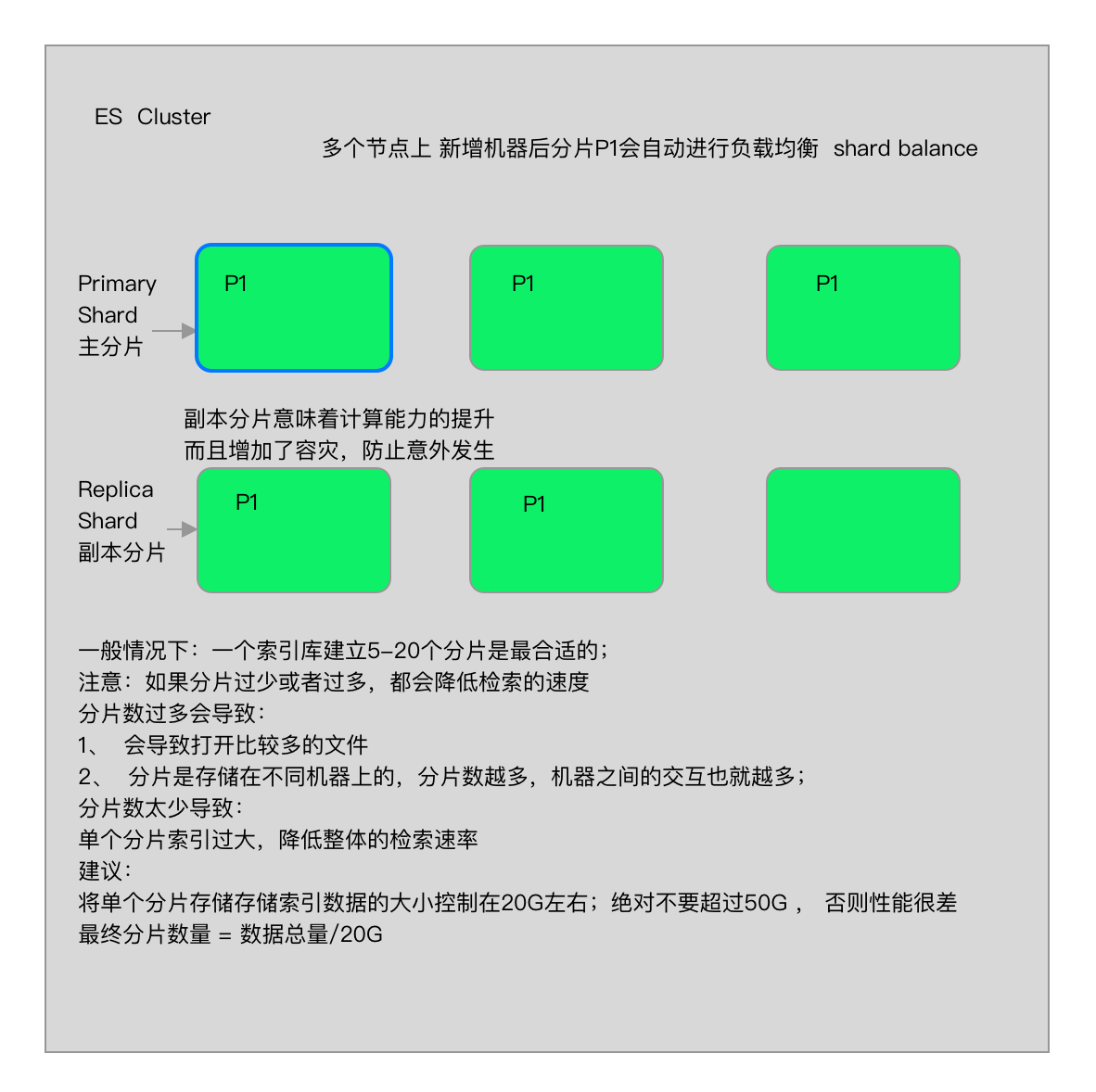
• Shard分片 (保证集群高可用)
1:一个index包含多个Shard,默认5P,默认每个P分配一个R,P的数量在创建索引的时候设置,如果想修改,需要重建索引。
2:每个Shard都是一个Lucene实例,有完整的创建索引的处理请求能力。
3:ES会自动在nodes上为我们做shard 均衡。
4:一个doc是不可能同时存在于多个PShard中的,但是可以存在于多个RShard中。
5: P和对应的R不能同时存在于同一个节点,所以最低的可用配置是两个节点,互为主备。