共享内存简介
共享内存时受用户控制的一级缓存,共享存储器为片内高速存储器,是一块可以被同一block中的所有线程访问的可读写存储器。访问共享存储器的速度几乎和访问寄存器一样快(相对而言,不是十分严谨的说法,真实情况是,共享内存的延时极低,大约1.5T/s的带宽,远高于全局内存的190G/s,此速度是寄存器的1/10),是实现线程间通信的延迟最小的方法。共享存储器可以用于实现多种功能,如果用于保存共用的计数器或者block的公用结果。
计算能力1.0、1.1、1.2、1.3硬件中,每个SM的共享存储器的大小为16KByte,被组织为16个bank,对共享存储器的动态与静态分配与初始化
int main(int argc, char** argv)
{
// ...
testKernel<<<1, 10, mem_size >>>(d_idata, d_odata);
// ...
CUT_EXIT(argc, argv);
}
__global__ void testKernel(float* g_idata, float* g_odata)
{
// extern声明,大小由主机端程序决定。动态声明
extern __shared__ float sdata_dynamic[];
// 静态声明
__shared__ int sdata_static[16];
// 注意shared memory不能再定义时初始化
sdata_static[tid] = 0;
}
注意,将共享存储器中的变量声明为外部数据时,例如
extern __shared__ float shared[];
数组的大小将在kernel启动时确定,通过其执行参数确定。通过这种方式定义的所有变量都开始于相同的地址,因此数组中的变量的布局必须通过偏移量显示管理。例如,如果希望在动态分配的共享存储器获得与以下代码对应的内容:
short array0[128];
float array1[64];
int array2[256];
应该按照如下的方式对应定义:
extern __shared__ char array[];
// __device__ or __global__ function
__device__ void func()
{
short* array0 = (short*)array;
float* array1 = (float*)&array0[128];
int* array2 = (int*)&array1[64];
}
共享内存架构
共享内存时基于存储器切换的架构(bank-switched architecture).为了能够在并行访问时获得高带宽,共享存储器被划分为大小相等,不能被同时访问的存储器模块,称为bank。由于不同的存储器模块可以互不干扰的同时工作,因此对位于n个bank上的n个地址的访问能够同时进行,此时有效带宽就是只有一个bank的n倍。
如果half-warp请求访问的多个地址位于同一个bank中,就会出现bank conflict。由于存储器模块在一个时刻无法响应多个请求,因此这些请求就必须被串行的完成。硬件会将造成bank conflict的一组访存请求划分为几次不存在conflict的独立请求,此时的有效带宽会降低与拆分得到的不存在conflict的请求个数相同的倍数。例外情况:一个half-warp中的所有线程都请求访问同一个地址时,会产生一次广播,此时反而只需要一次就可以响应所有线程的请求。
bank的组织方式是:每个bank的宽度固定为32bit,相邻的32bit字被组织在相邻的bank中,每个bank在每个时钟周期可以提供32bit的带宽。
在费米架构的设备上有32个存储体,而在G200与G80的硬件上只有16个存储体。每个存储体可以存4个字节大小的数据,足以用来存储一个单精度浮点型数据,或者一个标准的32位的整型数。开普勒架构的设备还引入了64位宽的存储体,使双精度的数据无需在跨越两个存储体。无论有多少线程发起操作,每个存储体每个周期只执行一次操作。
如果线程束中的每个线程访问一个存储体,那么所有线程的操作都可以在一个周期内同时执行。此时无须顺序地访问,因为每个线程访问的存储体在共享内存中都是独立的,互不影响。实际上,在每个存储体与线程之间有一个交叉开关将它们连接,这在字的交换中很有用。
此外,当线程束中的所有线程同时访问相同地址的存储体时,使用共享内存会有很大帮助,同常量内存一样,当所有线程访问同一地址的存储单元时,会触发一个广播机制到线程束中的每个线程中。通常0号线程会写一个值然后与线程束中的其他线程进行通信。
共享存储访问优化
在访问共享存储器的时候,需要着重关注如何减少bank conflict.产生bank conflict会造成序列化访问,严重降低有效带宽。
对于计算能力1.x设备,每个warp大小都是32个线程,而一个SM中的shared memory被划分为16个bank(0-15)。一个warp中的线程对共享存储器的访问请求会被划分为2个half-warp的访问请求,只有处于同一half-warp内的线程才可能发生bank conflict,而一个warp中位于前half-warp的线程与位于后half-warp的线程间则不会发生bank conflict。
没有bank conflic的共享存储器访问示例(线程从数组读取32bit字场景):
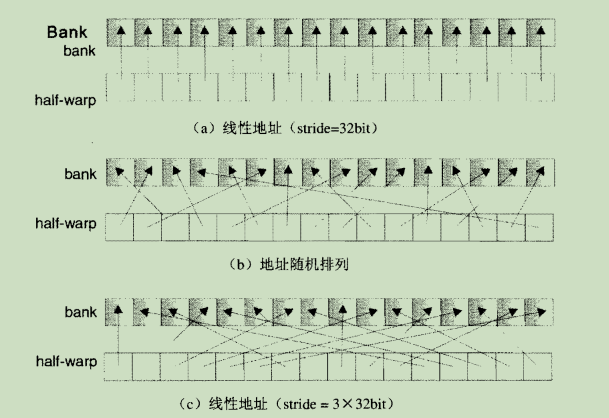
产生bank conflict的共享存储器访问示例(线程从数组读取32bit字场景):
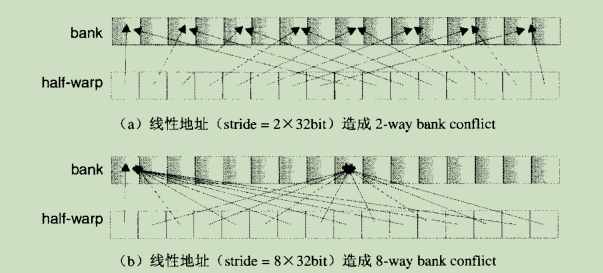
如果每个线程访问的数据大小不是32bit时,也会产生bank conflict。例如以下对char数组的访问会造成4way bank conflict:
__shared__ char shared[32];
char data = shared[BaseIndex + tid];
此时,shared[0]、shared[1]、shared[2]、shared[3]属于同一个bank。对同样的数组,按照下面的形式进行访问,则可以避免bank conflict问题:
char data = shared[BaseIndex + 4* tid];
对于一个结构体赋值会被编译为几次访存请求,例如:
__shared__ struct type shared[32];
struct type data = shared[BaseIndex + tid];
假如type的类型有如下几种:
// type1
struct type {
float x, y, z;
};
// type2
struct type {
float x, y;
};
// type3
struct type {
float x;
char c;
};
如果type定义为type1,那么type的访问会被编译为三次独立的存储器访问,每个结构体的同一成员之间有3个32bit字的间隔,所以不存在bank conflict。(没有bank conflic的共享存储器访问示例中场景c)
如果type定义为type2,那么type的访问会被编译为两个独立的存储器访问,每个结构体成员都有2个32bit字的间隔,线程ID相隔8的线程间就会发生bank conflict。(产生bank conflict的共享存储器访问示例中场景b)
如果type定义为type3,那么type的访问会被编译为两个独立的存储器访问,每个结构体成员都是通过5byte的间隔来访问,所以总会存在bank conflict。
shared memory访存机制
shared memory采用了广播机制,在响应一个对同一个地址的读请求时,一个32bit可以被读取的同时会广播给不同的线程。当half-warp有多个线程读取同一32bit字地址中的数据时,可以减少bank conflict的数量。而如果half-warp中的线程全都读取同一地址中的数据时,则完全不会发生bank conflict。不过,如果half-warp内有多个线程要对同一地址进行写操作,此时则会产生不确定的结果,发生这种情况时应该使用对shared memory 的原子操作。
对不同地址的访存请求,会被分为若干个处理步,每两个执行单元周期完成一步,每步都只处理一个conflict-free的访存请求的子集,知道half-warp的所有线程请求均完成。在每一步中都会按照以下规则构建子集:
(1)从尚未访问的地址所指向的字中,选出一个作为广播字;
(2)继续选取访问其他bank,并且不存在bank conflict的线程,再与上一步中广播字对应的线程一起构建一个子集。在每个周期中,选择哪个字作为广播字,以及选择哪些与其他bank对应的线程,都是不确定的。
参考:
《高性能运算之CUDA》
《CUDA并行程序设计 GPU编程指南》
《GPU高性能编程 CUDA实战》
《CUDA专家手册 GPU编程权威指南》