pdf 文档中包含了丰富的文字和图像信息,如果可以像处理html一样方便的按照属性进行归类处理,合并提取等操作对于平常看论文来说是十分方便的。
总结python处理pdf的几个常用功能包及其特点。目前开源的软件主要包含PyPDF2和PDFMiner,以及生成pdf的功能包reportlab。
1.pypdf2
可基于python进行pdf文件的分割、合并、裁剪与页面旋转,同时可以添加自定义数据和加密。它还可以从文件中抽取文本和元数据。
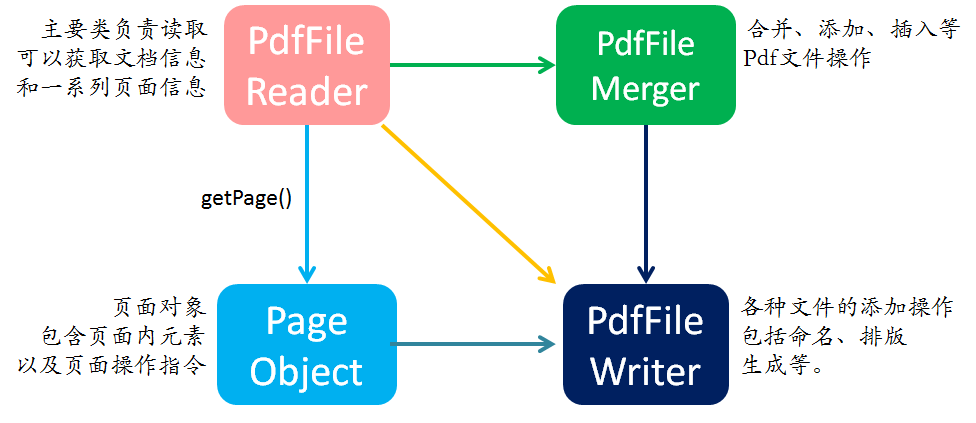
主要包含了读、写、合并、页面元素四个类,此外还包括了文件信息、xmp元信息以及目标类、域类和矩形对象类。
要进行文本操作,主要使用PdfFile读取文件,随后利用PageObject分析页面内部元素,提取进行相应操作,最后使用文件信息类来获取辅助信息。
2.PdfMiner
主要致力于pdf中的文本分析,包括字体和线条等也进行了处理。同时可以将pdf转换为text/html输出,可有效用于文本分析。它完全由python写成,主要功能如下:
pdf2txt.py #pdf2txt.py 从pdf中抽取文本
dumppdf.py #将pdf内容压缩为准xml文本
#更多文件用法可以ref:
#https://github.com/pdfminer
github:https://github.com/euske/pdfminer/
python3版本:https://github.com/pdfminer/pdfminer.six
3.pdfbox
来自apache的软件包,但是基于java开发。
4.mupdf
来自artifex,包含了软件包、命令行工具、渲染器和阅读器与适用于不同平台的源码。拥有c源码和js/java接口。
python包
ref:example, docs, pypi, github, 使用demo


5.xpdfReader
xpdfReader包含了一系列阅读器和工具包,可以实现文本抽取、图像转换和html转换。
ref:
各种pdf包工具:https://www.zaodei.com/jpress/c/208
pythonpdf2示例1:http://www.cnblogs.com/cocowool/p/6756966.html
pdf2 doc:https://pythonhosted.org/PyPDF2/ web:https://pypi.org/project/PyPDF2/1.26.0/
pdf2 github:https://github.com/mstamy2/PyPDF2
http://mstamy2.github.io/PyPDF2/
pdfminer docs:https://euske.github.io/pdfminer/programming.html
pdfminer web:http://www.unixuser.org/~euske/python/pdfminer/
miner useage:https://www.cnblogs.com/jamespei/p/5339769.html
ref:https://blog.csdn.net/bingxue7921/article/details/7951638
https://www.jb51.net/article/127956.htm
