我们在学习/科研过程中,时常要参(bai)考(piao)别人的开源代码。很多深度学习的代码是基于PyTorch的,那我们就来看一下代码的组织格式吧。
正如一个人有两条腿走路,CV领域也有模型和数据两条腿。
├── dataset # 数据集相关文件夹
├── model # 模型相关文件夹
│ ├── sub_module.py # 网络的子模块
│ └── xxnet.py # 基于子模块构建的网络
├── train.py # 模型训练脚本
├── valid.py # 模型验证脚本文件
├── test.py
├── utils.py # 其它的一些工具脚本
├── checkpoints # 训练过程中产生的模型
└── log # 日志文件
一、数据集
数据加载方面主要涉及到Dataset和DataLoader这两个类
1.1 Dataset
torch.utils.data.Dataset是一个抽象类,自定义的数据集类需要继承此类,并实现两个成员方法:__getitem__()和__len__()
第一个方法get item最为重要,它关系到我们每次怎么读数据。举例说明(读取图片):
def __getitem__(self, index):
img_path, label = self.data[index].img_path, self.data[index].label
img = Image.open(img_path)
return img, label
第二个方法__len__返回数据集的长度
这里所讲的dataset, 按照官方文档上来说是Map-Style datasets。即可以通过索引idx来访问第idx幅图片和对应的标签。
1.2 DataLoader
构造函数
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)
参数dataset:上面自定义的dataset
batch_size:一次加载几组数据
shuffle:乱序数据加载,通常在train时设为True; test时置为False
num_worker:多线程数据加载【最大设为多少呢?】
1.3 Transform
读取图片时使用PIL来读取,可以进行crop, resize, flip等操作,最重要的是将读取的图片对象转为Tensor
https://pytorch.apachecn.org/docs/1.0/torchvision_transforms.html
二、模型
模型中网络的子模块和网络类需要继承nn.Module
实现前向传播forward()函数
构造函数中需要super().__init__(), 即调用父类nn.Module的构造函数
三、训练
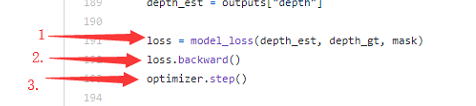
dataloader中数据feed至定义的xx-net中,进行forward。forward的产物计算loss, backward
tensorboardX的使用
https://tensorboardx.readthedocs.io/en/latest/tutorial.html#