伪分布式环境:
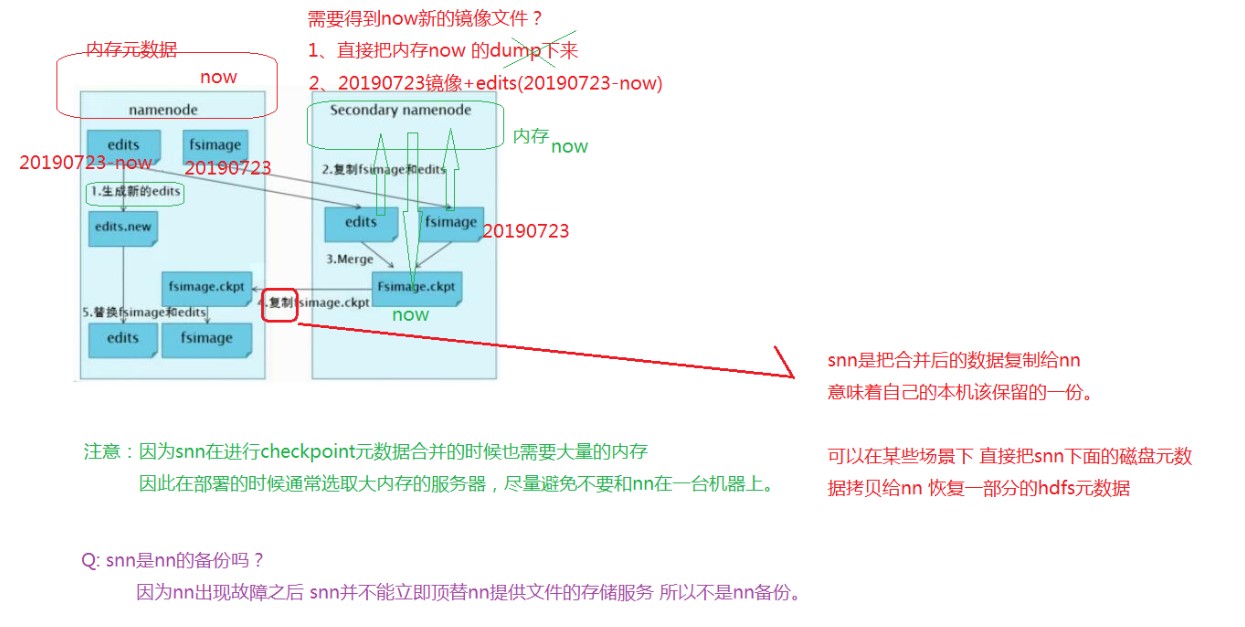
HA环境checkpoint机制
配置了HA的HDFS中,有active和standby namenode两个namenode节点。他们的内存中保存了一样的集群元数据信息,因为standby namenode已经将集群状态存储在内存中了,所以创建检查点checkpoint的过程只需要从内存中生成新的fsimage。
详细过程如下: (standby namenode=SbNN, activenamenode=ANN)
1. SBNN查看是否满足创建检查点的条件:
(1) 距离上次checkpoint的时间间隔 >= ${dfs.namenode.checkpoint.period}
(2) Edits中的事务条数达到${dfs.namenode.checkpoint.txns}限制
这两个条件任何一个被满足了,就触发一次检查点创建。
2. SbNN将内存中当前的状态保存成一个新的文件,命名为fsimage.ckpt_txid。其中txid是最后一个edit中的最后一条事务的ID(transaction ID)。然后为该fsimage文件创建一个MD5文件,并将fsimage文件重命名为fsimage_txid。
3. SbNN向active namenode发送一条HTTP GET请求。请求中包含了SbNN的域名,端口以及新fsimage的txid。
4. ANN收到请求后,用获取到的信息反过来向SbNN再发送一条HTTP GET请求,获取新的fsimage文件。这个新的fsimage文件传输到ANN上后,也是先命名为fsimage.ckpt_txid,并为它创建一个MD5文件。然后再改名为fsimage_txid。fsimage过程完成。