由于网络太烂,我常常写一些爬虫程序解析一些视频网站的整个专辑或漫画网站的整卷漫画的地址,然后用下载工具离线下载后再统一看。但是,从html源文件中解析出标题和链接来是一件比较麻烦的事情。由于各个网站没有什么共通的特征,并且网站经常改版,导致解析算法基本上没有复用性,必须对每个网站写一个解析算法。
以前我一贯是通过正则表达式写来直接解析文本,本身这种方式并没有什么问题,也非常方便。但是写正则表达式还是比较麻烦,需要反复调试,并且通用性不强,也很容易失效。一旦写多了还是很费脑子的。由于最近越来越懒了,因此便想转寻一种更为简洁快速的解析html文件的方法。
最初尝试的一种方式是通过第三方的HtmlParser来解析HTML为一棵树,然后根据一些attribute特征遍历这棵树来找到想要的节点。这种方式和上面的正则表达式的方式比起来要更合适一些,找特殊attribute找比编写正则表达式简单多了。找了几个HtmlParser看了一下,一个通用的问题是查询接口不够友好,往往也需要反复在VisualStudio下调试才能正确的解析出所要的结果。
在上面的这种方式碰壁了之后,我想到了另一种更为简单的实现方式:将Html文件转换为XML文件,这样就可以通过xpath或xlinq查询出我们所想要的结果。由于.net framework内置的API强大而简洁,用起来要方便得多了。
但这样做有如下两个问题:
-
如何将HTML转换为XML
-
如何快速的从XML里查询到所想要的结果
对于第一个问题,网上有不少开源的工具可以使用,但大多存在一些多多少少的bug,由于我也没有找到很合适的解析器,这里就不说了。对于第二个问题,就像我们在编写SQL语言的时候,往往并不是直接将SQL语言写入代码,而是会先找个工具测试一下,但结果无误后再将其写入代码那样;我写一个xpath查询测试工具来生成所需要的xpath,这样也能发现html转xml工具中的bug。由于能力有限,弄了一个比较简陋的工具,不过还是非常方便的。
这里我就拿一个优酷的例子演示一下:
例如,我们要获取如下网页的专辑信息http://www.youku.com/playlist_show/id_4425617.html,只需要如下几步。
-
首先输入url即可得到解析完成后的XML文件
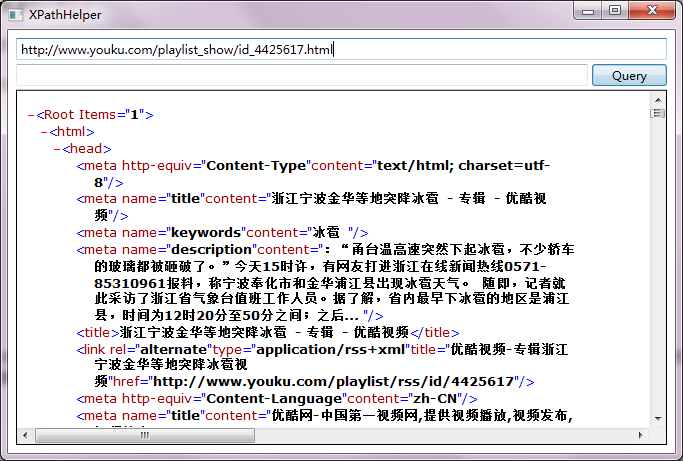
-
然后用IE中的开发者工具获取所想要信息处的HTML片段

-
根据HTML片段写出Xpath后,就可以验证Xpath的查询结果了。
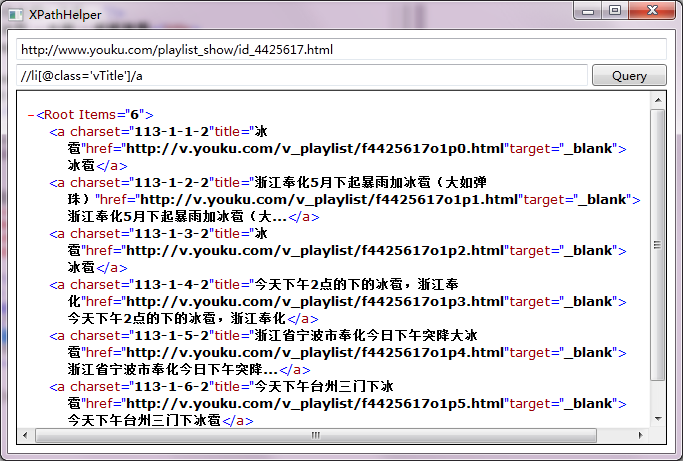
同样,用它来获取博客园今日首页的文章也是一件很容易的事情。
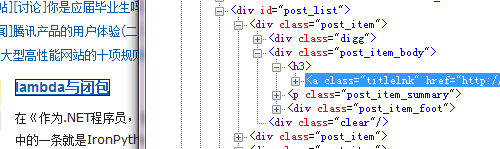

在这种方式下,对于不同的网页,只需要构造不同的Xpath即可;并且在浏览器提供的开发者工具的帮助下,写Xpath比写正则表达式简单的多,验证也非常方便。但由于目前的html解析至xml的库不够完善,xpath测试工具也不够友好和强大,还有不少问题有待解决,这里就不放代码了。本文只是抛砖引玉,介绍了一种简单的思路和方法,各位朋友有什么更合适的方法欢迎留言交流。